
本文从分析现在流行的前后端分离Web应用模式说起,然后介绍如何设计REST API,通过使用Django来实现一个REST API为例,明确后端开发REST API要做的最核心工作,然后介绍Django REST framework能帮助我们简化开发REST API的工作。
全套笔记直接地址: 请移步这里
共 5 章,24 子模块


DRF工程搭建
见识DRF的魅力
我们仍以在学习Django框架时使用的图书英雄为案例,使用Django REST framework快速实现图书的REST API。
1. 创建序列化器
在booktest应用中新建serializers.py用于保存该应用的序列化器。
创建一个BookInfoSerializer用于序列化与反序列化。
class BookInfoSerializer(serializers.ModelSerializer):"""图书数据序列化器"""class Meta:model = BookInfofields = '__all__'
- model 指明该序列化器处理的数据字段从模型类BookInfo参考生成
- fields 指明该序列化器包含模型类中的哪些字段,'all’指明包含所有字段
2. 编写视图
在booktest应用的views.py中创建视图BookInfoViewSet,这是一个视图集合。
from rest_framework.viewsets import ModelViewSet
from .serializers import BookInfoSerializer
from .models import BookInfoclass BookInfoViewSet(ModelViewSet):queryset = BookInfo.objects.all()serializer_class = BookInfoSerializer
- queryset 指明该视图集在查询数据时使用的查询集
- serializer_class 指明该视图在进行序列化或反序列化时使用的序列化器
3. 定义路由
在booktest应用的urls.py中定义路由信息。
from . import views
from rest_framework.routers import DefaultRouterurlpatterns = [...
]router = DefaultRouter() # 可以处理视图的路由器
router.register('books', views.BookInfoViewSet, name='books') # 向路由器中注册视图集urlpatterns += router.urls # 将路由器中的所以路由信息追到到django的路由列表中
4. 运行测试
运行当前程序(与运行Django一样)
python manage.py runserver
在浏览器中输入网址127.0.0.1:8000,可以看到DRF提供的API Web浏览页面:

1)点击链接127.0.0.1:8000/books/ 可以访问所有数据的接口,呈现如下页面:
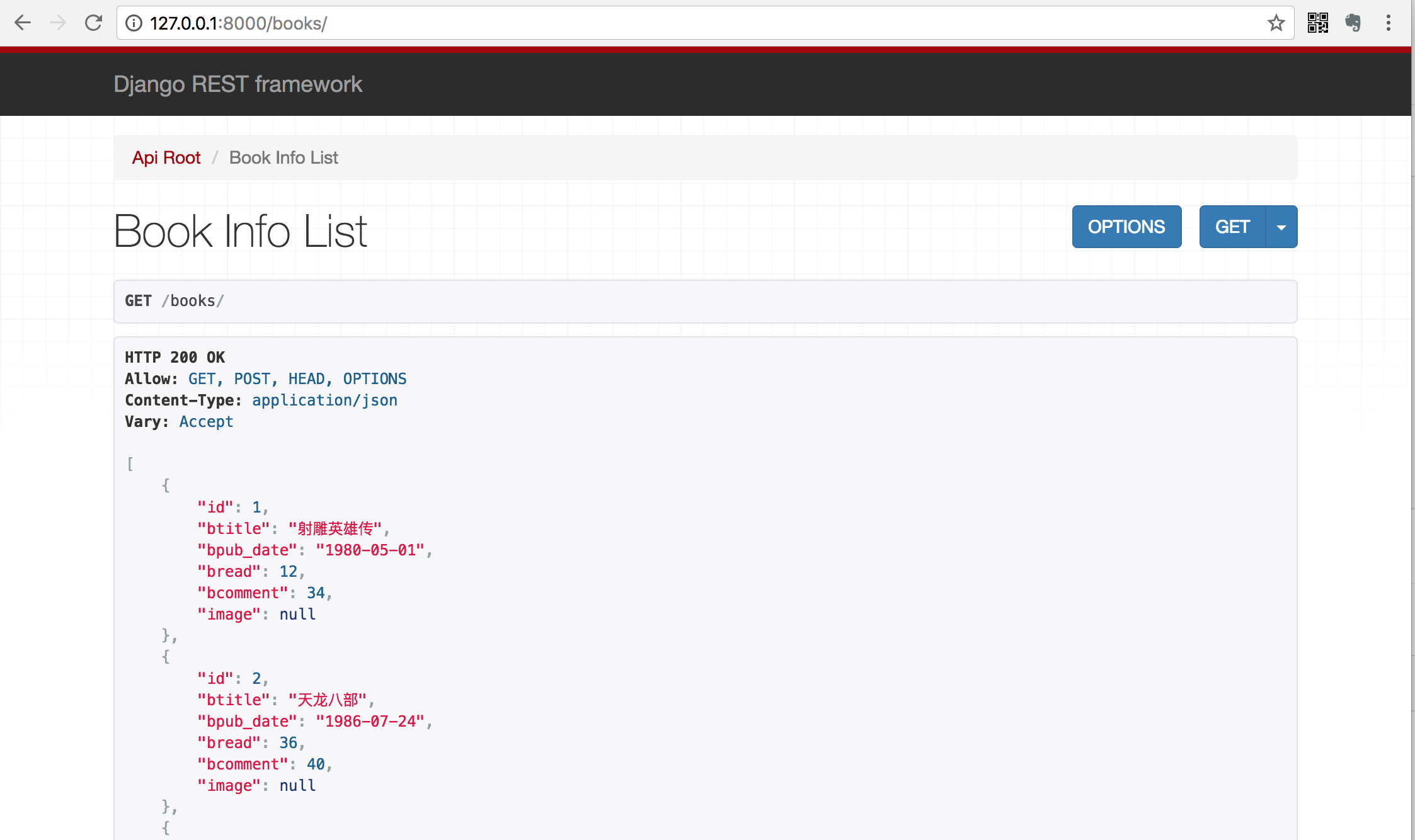
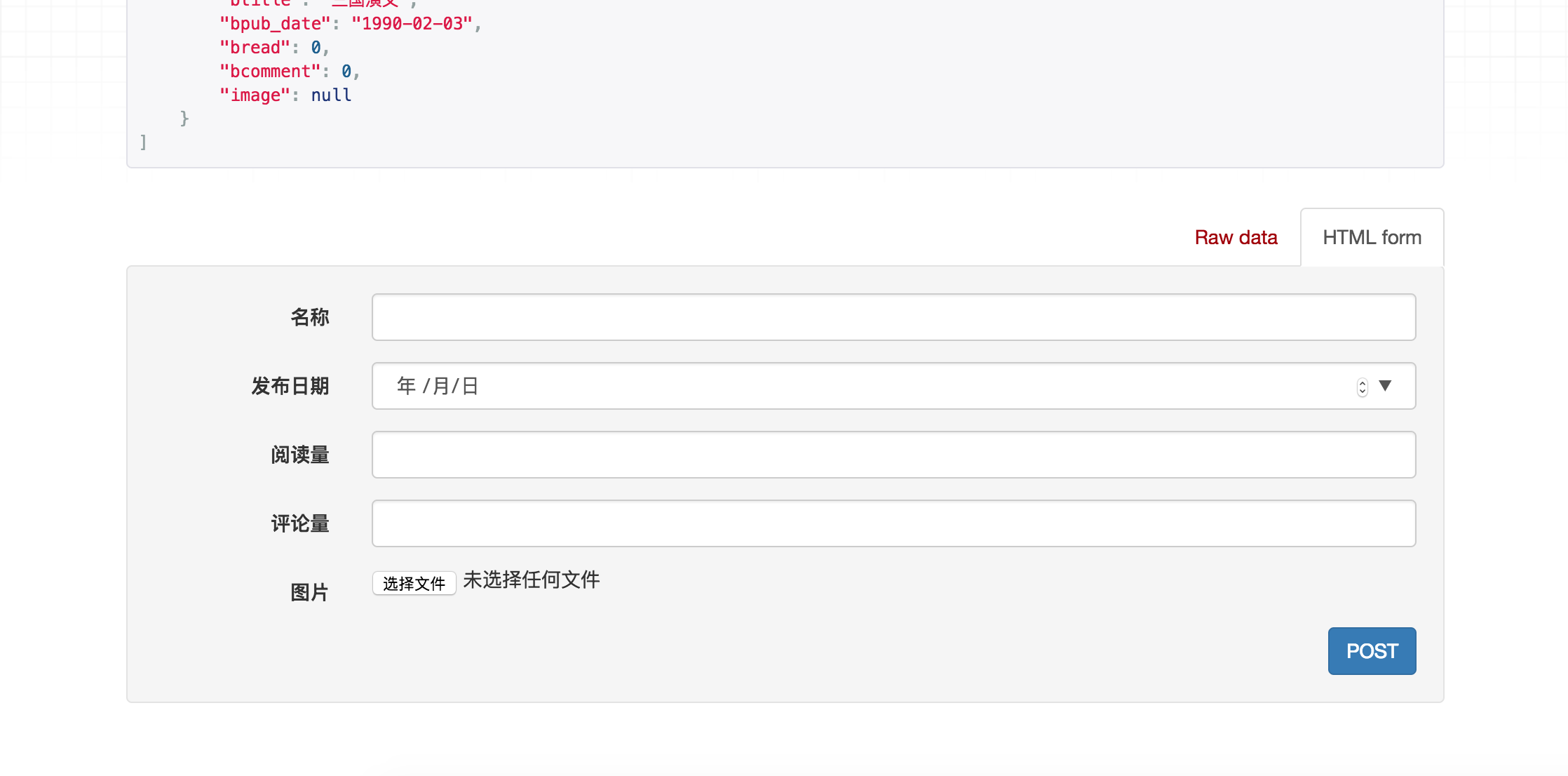
2)在页面底下表单部分填写图书信息,可以访问添加新图书的接口,保存新书:
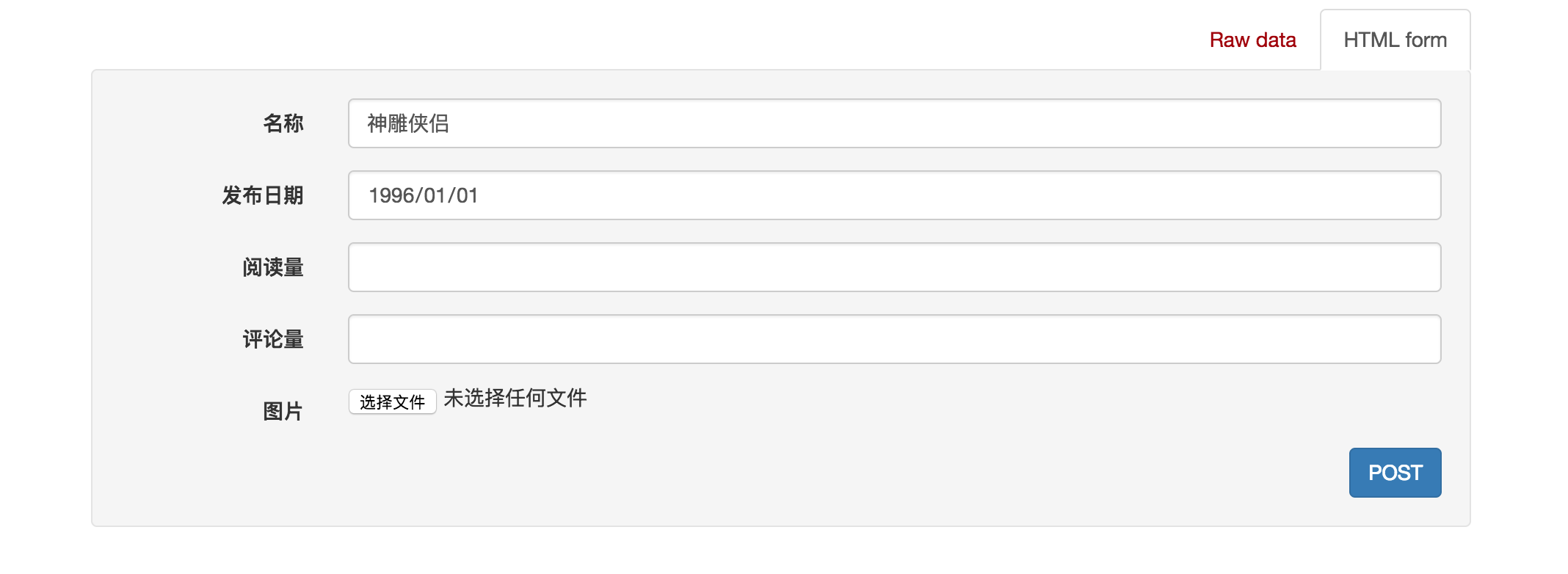
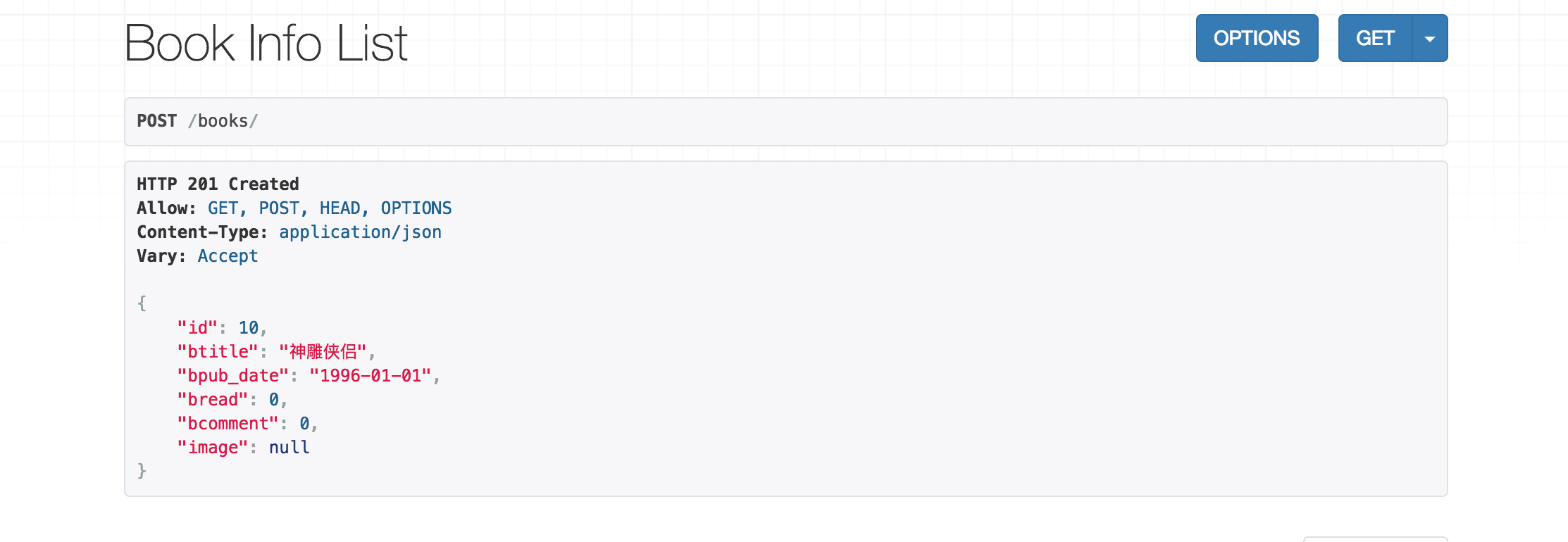
点击POST后,返回如下页面信息:
3)在浏览器中输入网址127.0.0.1:8000/books/1/,可以访问单一图书信息的接口(id为1的图书),呈现如下页面:

4)在页面底部表单中填写图书信息,可以访问修改图书的接口:
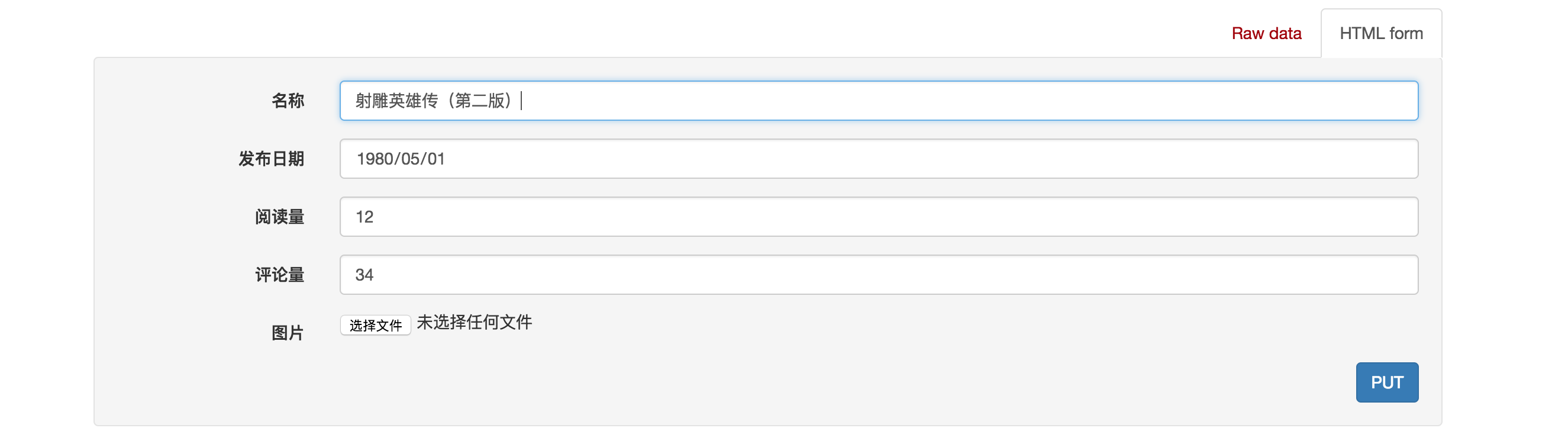
点击PUT,返回如下页面信息:
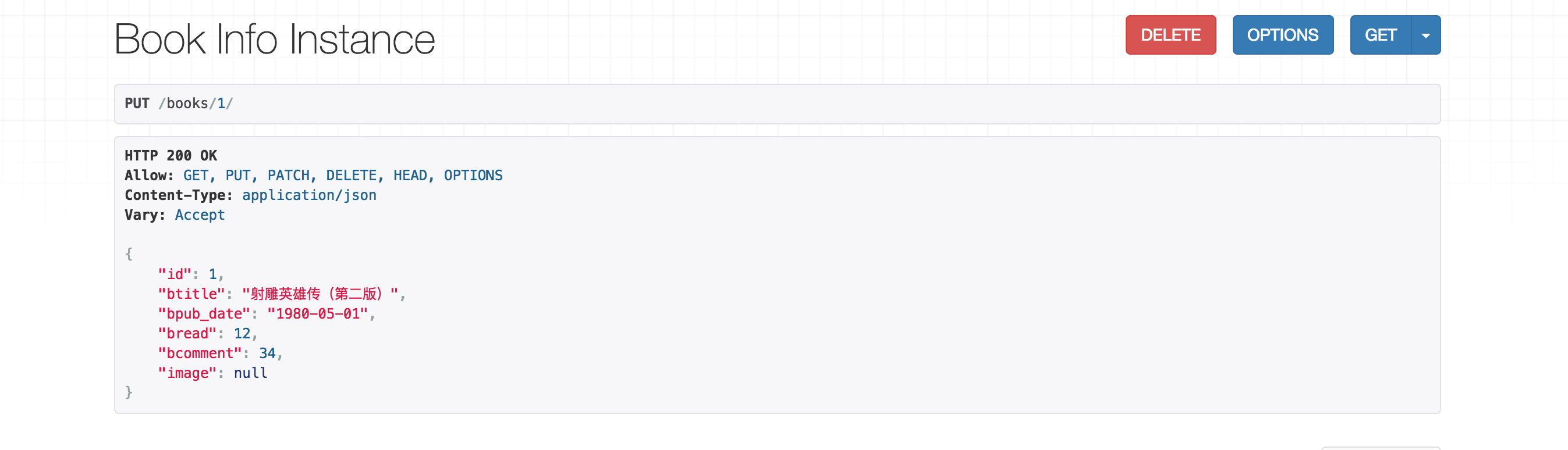
5)点击DELETE按钮,可以访问删除图书的接口:

返回,如下页面:

至此,是不是发现Django REST framework很好用!
Serializer序列化器
序列化器的作用:
- 进行数据的校验
- 对数据对象进行转换
定义Serializer
1. 定义方法
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
例如,我们已有了一个数据库模型类BookInfo
class BookInfo(models.Model):btitle = models.CharField(max_length=20, verbose_name='名称')bpub_date = models.DateField(verbose_name='发布日期', null=True)bread = models.IntegerField(default=0, verbose_name='阅读量')bcomment = models.IntegerField(default=0, verbose_name='评论量')image = models.ImageField(upload_to='booktest', verbose_name='图片', null=True)
我们想为这个模型类提供一个序列化器,可以定义如下:
class BookInfoSerializer(serializers.Serializer):"""图书数据序列化器"""id = serializers.IntegerField(label='ID', read_only=True)btitle = serializers.CharField(label='名称', max_length=20)bpub_date = serializers.DateField(label='发布日期', required=False)bread = serializers.IntegerField(label='阅读量', required=False)bcomment = serializers.IntegerField(label='评论量', required=False)image = serializers.ImageField(label='图片', required=False)
**注意:serializer不是只能为数据库模型类定义,也可以为非数据库模型类的数据定义。**serializer是独立于数据库之外的存在。
2. 字段与选项
常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| **BooleanField** | BooleanField() |
| **NullBooleanField** | NullBooleanField() |
| **CharField** | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| **EmailField** | EmailField(max_length=None, min_length=None, allow_blank=False) |
| **RegexField** | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| **SlugField** | SlugField(max_length=50, min*length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9*-]+ |
| **URLField** | URLField(max_length=200, min_length=None, allow_blank=False) |
| **UUIDField** | UUIDField(format='hex_verbose') format: 1) `'hex_verbose'` 如`"5ce0e9a5-5ffa-654b-cee0-1238041fb31a"` 2) `'hex'` 如 `"5ce0e9a55ffa654bcee01238041fb31a"` 3)`'int'` - 如: `"123456789012312313134124512351145145114"` 4)`'urn'` 如: `"urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a"` |
| **IPAddressField** | IPAddressField(protocol='both', unpack_ipv4=False, **options) |
| **IntegerField** | IntegerField(max_value=None, min_value=None) |
| **FloatField** | FloatField(max_value=None, min_value=None) |
| **DecimalField** | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| **DateTimeField** | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| **DateField** | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| **TimeField** | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| **DurationField** | DurationField() |
| **ChoiceField** | ChoiceField(choices) choices与Django的用法相同 |
| **MultipleChoiceField** | MultipleChoiceField(choices) |
| **FileField** | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| **ImageField** | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| **ListField** | ListField(child=, min_length=None, max_length=None) |
| **DictField** | DictField(child=) |
选项参数:
| 参数名称 | 作用 |
|---|---|
| **max_length** | 最大长度 |
| **min_lenght** | 最小长度 |
| **allow_blank** | 是否允许为空 |
| **trim_whitespace** | 是否截断空白字符 |
| **max_value** | 最小值 |
| **min_value** | 最大值 |
通用参数:
| 参数名称 | 说明 |
|---|---|
| **read_only** | 表明该字段仅用于序列化输出,默认False |
| **write_only** | 表明该字段仅用于反序列化输入,默认False |
| **required** | 表明该字段在反序列化时必须输入,默认True |
| **default** | 反序列化时使用的默认值 |
| **allow_null** | 表明该字段是否允许传入None,默认False |
| **validators** | 该字段使用的验证器 |
| **error_messages** | 包含错误编号与错误信息的字典 |
| **label** | 用于HTML展示API页面时,显示的字段名称 |
| **help_text** | 用于HTML展示API页面时,显示的字段帮助提示信息 |
3. 创建Serializer对象
定义好Serializer类后,就可以创建Serializer对象了。
Serializer的构造方法为:
Serializer(instance=None, data=empty, **kwarg)
说明:
1)用于序列化时,将模型类对象传入instance参数
2)用于反序列化时,将要被反序列化的数据传入data参数
3)除了instance和data参数外,在构造Serializer对象时,还可通过context参数额外添加数据,如
serializer = AccountSerializer(account, context={'request': request})
通过context参数附加的数据,可以通过Serializer对象的context属性。
序列化使用
我们在django shell中来学习序列化器的使用。
python manage.py shell
1 基本使用
1) 先查询出一个图书对象
from booktest.models import BookInfobook = BookInfo.objects.get(id=2)
2) 构造序列化器对象
from booktest.serializers import BookInfoSerializerserializer = BookInfoSerializer(book)
3)序列化数据
通过data属性可以序列化后的数据
serializer.data# {'id': 2, 'btitle': '天龙八部', 'bpub_date': '1986-07-24', 'bread': 36, 'bcomment': 40, 'image': None}4)如果要被序列化的是包含多条数据的查询集QuerySet,可以通过添加many=True参数补充说明
book_qs = BookInfo.objects.all()
serializer = BookInfoSerializer(book_qs, many=True)
serializer.data# [OrderedDict([('id', 2), ('btitle', '天龙八部'), ('bpub_date', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('image', N]), OrderedDict([('id', 3), ('btitle', '笑傲江湖'), ('bpub_date', '1995-12-24'), ('bread', 20), ('bcomment', 80), ('image'ne)]), OrderedDict([('id', 4), ('btitle', '雪山飞狐'), ('bpub_date', '1987-11-11'), ('bread', 58), ('bcomment', 24), ('ima None)]), OrderedDict([('id', 5), ('btitle', '西游记'), ('bpub_date', '1988-01-01'), ('bread', 10), ('bcomment', 10), ('im', 'booktest/xiyouji.png')])]2 关联对象嵌套序列化
如果需要序列化的数据中包含有其他关联对象,则对关联对象数据的序列化需要指明。
例如,在定义英雄数据的序列化器时,外键hbook(即所属的图书)字段如何序列化?
我们先定义HeroInfoSerialzier除外键字段外的其他部分
class HeroInfoSerializer(serializers.Serializer):"""英雄数据序列化器"""GENDER_CHOICES = ((0, 'male'),(1, 'female'))id = serializers.IntegerField(label='ID', read_only=True)hname = serializers.CharField(label='名字', max_length=20)hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性别', required=False)hcomment = serializers.CharField(label='描述信息', max_length=200, required=False, allow_null=True)
对于关联字段,可以采用以下几种方式:
1) PrimaryKeyRelatedField
此字段将被序列化为关联对象的主键。
hbook = serializers.PrimaryKeyRelatedField(label='图书', read_only=True)
或
hbook = serializers.PrimaryKeyRelatedField(label='图书', queryset=BookInfo.objects.all())
指明字段时需要包含read_only=True或者queryset参数:
- 包含read_only=True参数时,该字段将不能用作反序列化使用
- 包含queryset参数时,将被用作反序列化时参数校验使用
使用效果:
from booktest.serializers import HeroInfoSerializer
from booktest.models import HeroInfo
hero = HeroInfo.objects.get(id=6)
serializer = HeroInfoSerializer(hero)
serializer.data# {'id': 6, 'hname': '乔峰', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': 2}2)使用关联对象的序列化器
hbook = BookInfoSerializer()
使用效果
{'id': 6, 'hname': '乔峰', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': OrderedDict([('id', 2), ('btitle', '天龙八部')te', '1986-07-24'), ('bread', 36), ('bcomment', 40), ('image', None)])}
3) StringRelatedField
此字段将被序列化为关联对象的字符串表示方式(即__str__方法的返回值)
hbook = serializers.StringRelatedField(label='图书')
使用效果
{'id': 6, 'hname': '乔峰', 'hgender': 1, 'hcomment': '降龙十八掌', 'hbook': '天龙八部'}
3 many参数
如果关联的对象数据不是只有一个,而是包含多个数据,如想序列化图书BookInfo数据,每个BookInfo对象关联的英雄HeroInfo对象可能有多个,此时关联字段类型的指明仍可使用上述几种方式,只是在声明关联字段时,多补充一个many=True参数即可。
此处仅拿PrimaryKeyRelatedField类型来举例,其他相同。
在BookInfoSerializer中添加关联字段:
class BookInfoSerializer(serializers.Serializer):"""图书数据序列化器"""id = serializers.IntegerField(label='ID', read_only=True)btitle = serializers.CharField(label='名称', max_length=20)bpub_date = serializers.DateField(label='发布日期', required=False)bread = serializers.IntegerField(label='阅读量', required=False)bcomment = serializers.IntegerField(label='评论量', required=False)image = serializers.ImageField(label='图片', required=False)heroinfo_set = serializers.PrimaryKeyRelatedField(read_only=True, many=True) # 新增
使用效果:
from booktest.serializers import BookInfoSerializer
from booktest.models import BookInfo
book = BookInfo.objects.get(id=2)
serializer = BookInfoSerializer(book)
serializer.data# {'id': 2, 'btitle': '天龙八部', 'bpub_date': '1986-07-24', 'bread': 36, 'bcomment': 40, 'image': None, 'heroinfo_set': [6,8, 9]}







$/i ”这个正则表达式的理解)










