一个灵活、现代的Android应用架构

学习Android架构的原则:学习原则,不要盲目遵循规则。
本文旨在通过示例演示实际应用:通过示范Android架构来进行教学。最重要的是,这意味着展示出如何做出各种架构决策。在某些情况下,我们会遇到几个可能的答案,而在每种情况下,我们都会依靠原则而不是机械地记住一套规则。
因此,让我们一起构建一个应用。
介绍我们要构建的应用
我们要为行星观测者构建一个应用。它将大致如下所示:

我们的应用将具有以下功能:
- 已发现的所有行星的列表
- 添加刚刚发现的新行星的方式
- 删除行星的方法(以防你意识到你的发现实际上只是望远镜镜头上的污迹)
- 添加一些示例行星,让用户了解应用的工作方式
它将具有离线数据缓存以及在线访问数据库的功能。
像往常一样,在我的步骤指导中,我鼓励你偏离常规:添加额外的功能,考虑可能的未来规格变化,挑战自己。在这里,学习的重点是代码背后的思考过程,而不仅仅是代码本身。因此,如果你想从这个教程中获得最佳效果,请不要盲目复制代码。
这是我们最终将得到的代码库链接:
https://github.com/tdcolvin/PlanetSpotters
介绍我们将要使用的架构原则
我们将受到SOLID原则、清晰架构原则和谷歌的现代应用架构原则的启发。
我们不会将这些原则视为硬性规则,因为我们足够聪明,可以构建适合我们应用的东西(特别是对应我们预期的应用增长)。例如,如果你对清晰架构如宗教般追随,你会产生稳固、可靠、可扩展的软件,但你的代码可能对于一个单一用途的应用来说会过于复杂。谷歌的原则产生了更简单的代码,但如果某天该应用可能由多个大型开发团队维护,那就不太合适了。
我们将从谷歌的拓扑结构开始,途中会受到清晰架构的启示。
谷歌的拓扑结构如下:
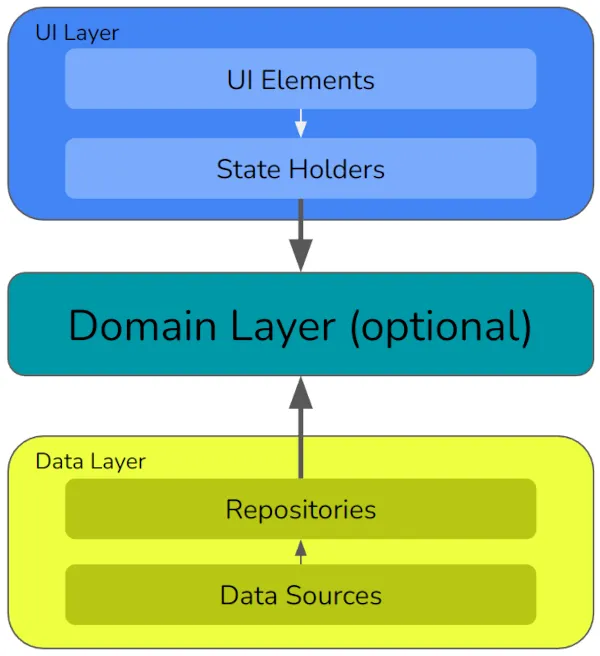
让我们逐步实现这一架构,并且在我最近的一篇文章中,对每个部分进行更深入的探讨。但是作为简要概述:
UI层(UI Layer)
UI层实现了用户界面。它分为:
- UI元素,这是用于在屏幕上绘制内容的所有专有代码。在Android中,主要选择是Jetpack Compose(在这种情况下,
@Composables放在这里)或XML(在这种情况下,这里包含XML文件和资源)。 - 状态持有者,这是您实现首选MVVM / MVC / MVP等拓扑的地方。在这个应用程序中,我们将使用视图模型。
领域层(Domain Layer)
领域层用于包含高级业务逻辑的用例。例如,当我们想要添加一个行星时,AddPlanetUseCase将描述完成此操作所需的步骤。它是一系列的“what”,而不是“how”:例如,我们会说“保存行星对象的数据”。这是一个高级指令。我们不会说“将其保存到本地缓存”,更不用说“使用Room数据库将其保存到本地缓存”——这些较低级别的实现细节放在其他地方。
数据层(Data Layer)
谷歌敦促我们在应用程序中拥有一个数据的单一真相来源;也就是说,获得数据绝对“正确”版本的方法。这就是数据层将为我们提供的内容(除了描述用户刚刚输入的内容的数据结构之外的所有数据)。它分为:
- 存储库,管理数据类型。例如,我们将有一个行星数据的存储库,它将为发现的行星提供CRUD(创建、读取、更新、删除)操作。它还将处理数据存储在本地缓存以及远程访问的情况,选择适当的来源来执行不同种类的操作,并管理两个来源包含不同副本数据的情况。在这里,我们会谈论本地缓存的情况,但我们仍然不会谈论我们将使用什么第三方技术来实现它。
- 数据源,管理数据的存储方式。当存储库要求“远程存储X”时,它会请求数据源执行此操作。数据源仅包含驱动专有技术所需的代码——可能是Firebase,或者是HTTP API,或其他什么技术。
良好的架构允许延迟决策
在这个阶段,我们知道应用程序的功能将是什么,以及它将如何管理其数据的一些基本想法。
还有一些我们尚未决定的事情。我们不知道UI将会是什么样子,或者我们将用什么技术来构建它(Jetpack Compose,XML等)。我们不知道本地缓存将采取什么形式。我们不知道我们将使用什么专有解决方案来访问在线数据。我们不知道我们是否将支持手机、平板电脑或其他形态因素。
问题:我们需要知道上述任何内容来制定我们的架构吗?
答案:不需要!
以上都是低级考虑因素(在清晰架构中,它们的代码将位于最外层)。它们是实现细节,而不是逻辑。SOLID的依赖倒置原则告诉我们,不应该编写依赖于它们的代码。
换句话说,我们应该能够编写(和测试!)其余的应用程序代码,而无需了解上述任何内容。当我们确切了解上述问题的答案时,我们已经编写的任何内容都不需要更改。
这意味着在设计师完成设计和利益相关者决定使用的第三方技术之前,代码生产阶段就可以开始。因此,良好的架构允许延迟决策。(并具有灵活性以在不引起大量代码混乱的情况下撤销任何此类决策)。
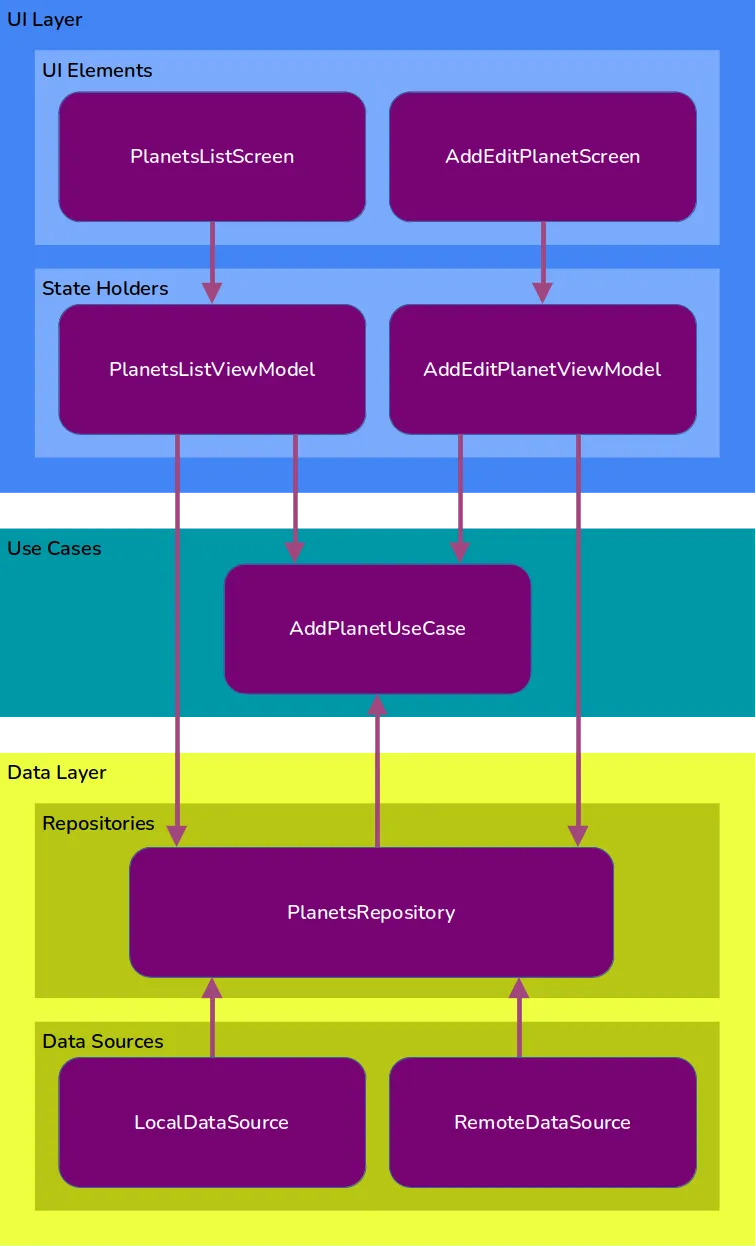
我们项目的架构图
下面是我们将行星观测者应用程序放入谷歌拓扑的第一次尝试。
数据层(Data Layer)
我们将拥有行星数据的存储库,以及两个数据源:一个用于本地缓存,另一个用于远程数据。
UI层(UI Layer)
将有两个状态持有者,一个用于行星列表页,另一个用于添加行星页。每个页面还将有其一组UI元素,使用的技术暂时可以保持不确定。
领域层(Domain layer)
我们有两种完全有效的方式来构建我们的领域层:
我们只在重复业务逻辑的地方添加用例。在我们的应用程序中,唯一重复的逻辑是添加行星的地方:用户在添加示例行星列表时需要它,手动输入自己的行星详细信息时也需要。因此,我们只会创建一个用例:AddPlanetUseCase。在其他情况(例如删除行星)下,状态持有者将直接与存储库交互。
我们将每个与存储库的交互都添加为用例,以便状态持有者和存储库之间永远不会直接联系。在这种情况下,我们将有用于添加行星、删除行星和列出行星的用例。
选项#2的好处是它遵循了清晰架构的规则。但个人认为,对于大多数应用来说,它稍显繁重,所以我倾向于选择选项#1。这也是我们在这里要做的。
这给我们带来了以下的架构图:
从哪里开始编写代码
我们应该从哪些代码开始呢?
规则是:
从高级代码开始,逐步向下编写。
这意味着首先编写用例,因为这样做会告诉我们对存储库层有什么要求。一旦我们知道存储库需要什么,我们就可以写出数据源需要满足的要求,以便进行操作。
同样,由于用例告诉我们用户可能采取的所有行动,我们知道所有输入和输出都来自UI。从这些信息中,我们将了解UI需要包含什么内容,因此可以编写状态持有者(视图模型)。然后,有了状态持有者,我们就知道需要编写哪些UI元素。
当然,我们可以无限期地延迟编写UI元素和数据源(即所有低级代码),直到高级工程师和项目利益相关者就要使用的技术达成一致。
这样就结束了理论部分。现在让我们开始构建应用程序。在进行决策时,我将引导您。
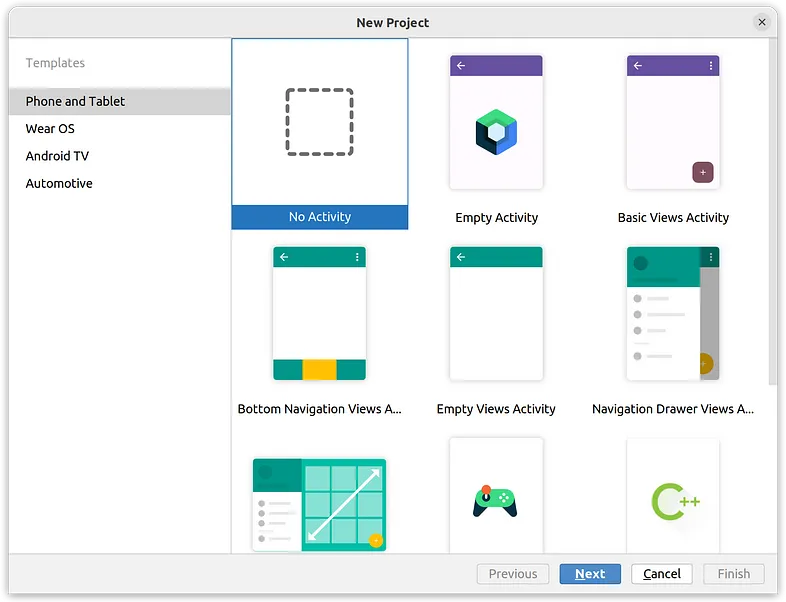
第1步:创建项目
打开Android Studio并创建一个“No Activity”的项目:
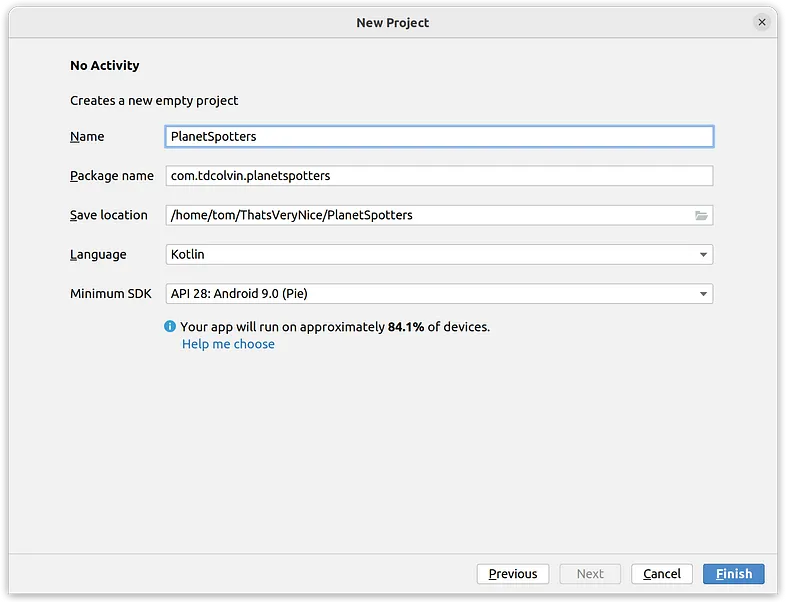
在下一个屏幕上,将其命名为PlanetSpotters,并将其他所有内容保持不变:添加依赖注入
我们将需要一个依赖注入框架,这有助于应用SOLID的依赖反转原则。在这里,我的首选是Hilt,幸运的是,这也是Google专门推荐的选择。
要添加Hilt,请将以下内容添加到根Gradle文件中:然后将其添加到app/build.gradle文件中:(请注意,我们在这里设置兼容性为Java 17,这是Kapt需要的,Hilt使用它。您将需要Android Studio Flamingo或更高版本)。
最后,通过添加@HiltAndroidApp注解来重写Application类。也就是说,在您的应用程序的包文件夹(这里是com.tdcolvin.planetspotters)中创建一个名为PlanetSpottersApplication的文件,并包含以下内容:…然后通过将其添加到清单中,告诉操作系统实例化它:…一旦我们有了主活动,我们将需要向其添加@AndroidEntryPoint。但目前,这完成了我们的Hilt设置。
最后,我们将通过将这些行添加到app/build.gradle来添加对其他有用库的支持:第一步:列出用户可以做和看到的所有内容
在编写用例和存储库之前,需要进行此步骤。回想一下,用例是用户可以执行的单个任务,以高层次(what而不是how)描述。
因此,让我们开始写出这些任务;一份详尽的用户可以在应用程序中执行和查看的所有任务列表。
其中一些任务最终将作为用例编码。(事实上,在Clean Architecture下,所有这些任务都必须作为用例编写)。其他任务将由UI层直接与存储库层交互。
在此需要一份书面规范。不需要UI设计,但如果您有UI设计,这当然有助于可视化。
以下是我们的列表:
-
获取已发现行星的列表,该列表会自动更新
输入:无
输出:Flow<List<Planet>>
动作:从存储库请求当前已发现行星的列表,以在发生更改时保持我们的更新。 -
获取单个已发现行星的详细信息,该信息会自动更新
输入:String-我们要获取的行星的ID
输出:Flow<Planet>
动作:从存储库请求具有给定ID的行星,并要求在发生更改时保持我们的更新。 -
添加/编辑新发现的行星
输入:planetId:String?-如果非空,则为要编辑的行星ID。如果为空,则我们正在添加新行星。name:String-行星的名称distanceLy:Float-行星到地球的距离(光年)discovered:Date-发现日期
输出:无(通过完成没有异常来确定成功)
动作:根据输入创建一个Planet对象,并将其传递给存储库(以添加到其数据源)。
-
添加一些示例行星
输入:无
输出:无
动作:要求存储库添加三个示例行星,发现日期为当前时间:Trenzalore(300光年),Skaro(0.5光年),Gallifrey(40光年)。 -
删除一颗行星
输入:String-要删除的行星的ID
输出:无
动作:要求存储库删除具有给定ID的行星。
现在,我们有了这个列表,我们可以开始编码用例和存储库。
第2步:编写用例
根据第一步,我们有一个用户可以执行的任务列表。之前,我们决定将其中的任务“添加行星”作为用例进行编码。(我们决定仅在应用程序的不同区域重复任务时添加用例)。
这给了我们一个用例
val addPlanetUseCase: AddPlanetUseCase = …//Use our instance as if it were a function:
addPlanetUseCase(…)
下面是AddPlanetUseCase的实现代码:
class AddPlanetUseCase @Inject constructor(private val planetsRepository: PlanetsRepository) {suspend operator fun invoke(planet: Planet) {if (planet.name.isEmpty()) {throw Exception("Please specify a planet name")}if (planet.distanceLy < 0) {throw Exception("Please enter a positive distance")}if (planet.discovered.after(Date())) {throw Exception("Please enter a discovery date in the past")}planetsRepository.addPlanet(planet)}
}
在这里,PlanetsRepository是一个列出存储库将具有的方法的接口。稍后会更多地介绍这一点(特别是为什么我们创建接口而不是类)。但现在让我们创建它,这样我们的代码就可以编译通过:
interface PlanetsRepository {suspend fun addPlanet(planet: Planet)
}
Planet数据类型定义如下:
data class Planet(val planetId: String?,val name: String,val distanceLy: Float,val discovered: Date
)
addPlanet方法(就像在使用案例中的invoke函数一样)被声明为suspend,因为我们知道它将涉及后台工作。我们以后会在这个接口中添加更多的方法,但目前这就足够了。
顺便说一下,你可能会问为什么我们费力地创建了一个如此简单的使用案例。答案在于它未来可能会变得更加复杂,并且外部代码可以与该复杂性隔离开来。
第2.1步:测试使用案例
我们现在已经编写了使用案例,但我们无法运行它。首先,它依赖于PlanetsRepository接口,而我们还没有它的实现。Hilt不知道如何处理它。
但是我们可以编写测试代码,提供一个伪造的PlanetsRepository实例,并使用我们的测试框架运行它。这就是你现在应该做的。
由于这是关于架构的教程,测试的细节不在范围内,所以这一步留给你作为练习。但请注意,良好的架构设计让我们将组件拆分为易于测试的部分。
第3步:数据层,编写PlanetsRepository
记住,仓库的工作是整合不同的数据源,处理它们之间的差异,并提供CRUD操作。
使用依赖倒置和依赖注入
根据干净架构和依赖倒置原则(在我上一篇文章中有更多信息),我们希望避免外部代码依赖于仓库实现内部代码。这样一来,使用案例或视图模型(例如)就不会受到仓库代码的更改影响。
这解释了为什么我们之前将PlanetsRepository创建为接口(而不是类)。调用代码将只依赖于接口,但它将通过依赖注入接收实现。所以现在我们将向接口添加更多方法,并创建其实现,我们将称之为DefaultPlanetsRepository。
(另外:有些开发团队遵循调用实现为<interface name>Impl的约定,例如PlanetsRepositoryImpl。我认为这种约定不利于阅读:类名应该告诉你为什么要实现一个接口。所以我避免使用这种约定。但我提及它是因为它被广泛使用。)
使用Kotlin Flows使数据可用
如果你还没有接触过Kotlin Flows,请停下手头的工作,立即阅读相关资料。它们将改变你的生活。
https://developer.android.com/kotlin/flow
它们提供了一个数据“管道”,随着新的结果变得可用而改变。只要调用方订阅了管道,他们将在有变化时收到更新。因此,现在我们的UI可以在数据更新时自动更新,几乎不需要额外的工作。相比起过去,我们必须手动向UI发出数据已更改的信号。
虽然存在其他类似的解决方案,比如RxJava和MutableLiveData,它们做类似的事情,但它们不如Flows灵活和易于使用。
添加常用的WorkResult类
WorkResult类是数据层常用的返回类型。它允许我们描述一个特定请求是否成功,其定义如下:
//WorkResult.kt
package com.tdcolvin.planetspotters.data.repositorysealed class WorkResult<out R> {data class Success<out T>(val data: T) : WorkResult<T>()data class Error(val exception: Exception) : WorkResult<Nothing>()object Loading : WorkResult<Nothing>()
}
调用代码可以检查给定的WorkResult是Success、Error还是Loading对象(后者表示尚未完成),从而确定请求是否成功。
第4步: 实现Repository接口
让我们把上面的内容整合起来,为构成我们的PlanetsRepository的方法和属性制定规范。
它有两个用于获取行星的方法。第一个方法通过其ID获取单个行星:
fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>>
第二个方法获取表示行星列表的Flow:
fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>>
这些方法都是各自数据的单一来源。每次我们都将返回存储在本地缓存中的数据,因为我们需要处理这些方法被频繁运行的情况,而本地数据比访问远程数据源更快、更便宜。但我们还需要一种方法来刷新本地缓存。这将从远程数据源更新本地数据源:
suspend fun refreshPlanets()
接下来,我们需要添加、更新和删除行星的方法:
suspend fun addPlanet(planet: Planet)suspend fun deletePlanet(planetId: String)
因此,我们的接口现在看起来是这样的:
interface PlanetsRepository {fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>>fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>>suspend fun refreshPlanets()suspend fun addPlanet(planet: Planet)suspend fun deletePlanet(planetId: String)
}
边写代码边编写数据源接口
为了编写实现该接口的类,我们需要注意数据源将需要哪些方法。回想一下,我们有两个数据源:LocalDataSource和RemoteDataSource。我们还没有决定使用哪种第三方技术来实现它们——我们现在也不需要。
让我们现在创建接口定义,准备好在需要时添加方法签名:
//LocalDataSource.kt
package com.tdcolvin.planetspotters.data.source.localinterface LocalDataSource {//Ready to add method signatures here...
}
//RemoteDataSource.kt
package com.tdcolvin.planetspotters.data.source.remoteinterface RemoteDataSource {//Ready to add method signatures here...
}
现在准备填充这些接口,我们可以编写DefaultPlanetsRepository了。让我们逐个方法来看:
编写getPlanetFlow()和getPlanetsFlow()
这两个方法都很简单;我们返回本地源中的数据。(为什么不是远程源?因为本地源的存在是为了快速、资源轻量级地访问数据。远程源可能始终是最新的,但它较慢。如果我们严格需要最新的数据,那么在调用getPlanetsFlow()之前,我们可以使用下面的refreshPlanets()。)
//DefaultPlanetsRepository.kt
override fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>> {return localDataSource.getPlanetsFlow()
}override fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>> {return localDataSource.getPlanetFlow(planetId)
}
因此,这取决于LocalDataSource中的getPlanetFlow()和getPlanetsFlow()函数。我们现在将它们添加到接口中,以便我们的代码可以编译。
//LocalDataSource.kt
interface LocalDataSource {fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>>fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>>
}
编写refreshPlanets()方法
为了更新本地缓存,我们从远程数据源获取当前的行星列表,并将其保存到本地数据源中。(然后,本地数据源可以“感知”到更改,并通过getPlanetsFlow()返回的Flow发出新的行星列表。)
//DefaultPlanetsRepository.kt
override suspend fun refreshPlanets() {val planets = remoteDataSource.getPlanets()localDataSource.setPlanets(planets)
}
这需要在每个数据源接口中添加一个新的方法,现在这些接口如下所示:
//LocalDataSource.kt
interface LocalDataSource {fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>>fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>>suspend fun setPlanets(planets: List<Planet>)
}
//RemoteDataSource.kt
interface RemoteDataSource {suspend fun getPlanets(): List<Planet>
}
编写addPlanet()和deletePlanet()函数时,它们都遵循相同的模式:在远程数据源上执行写操作,如果成功,就将更改反映到本地缓存中。
我们预计远程数据源会为Planet对象分配唯一的ID,一旦它进入数据库,RemoteDataSource的addPlanet()函数将返回带有非空ID的更新后的Planet对象。
//PlanetsRepository.kt
override suspend fun addPlanet(planet: Planet) {val planetWithId = remoteDataSource.addPlanet(planet)localDataSource.addPlanet(planetWithId)
}override suspend fun deletePlanet(planetId: String) {remoteDataSource.deletePlanet(planetId)localDataSource.deletePlanet(planetId)
}
我们最终的数据源接口如下:
//LocalDataSource.kt
interface LocalDataSource {fun getPlanetsFlow(): Flow<WorkResult<List<Planet>>>fun getPlanetFlow(planetId: String): Flow<WorkResult<Planet?>>suspend fun setPlanets(planets: List<Planet>)suspend fun addPlanet(planet: Planet)suspend fun deletePlanet(planetId: String)
}
//RemoteDataSource.kt
interface RemoteDataSource {suspend fun getPlanets(): List<Planet>suspend fun addPlanet(planet: Planet): Planetsuspend fun deletePlanet(planetId: String)
}
第5步:状态持有者,编写PlanetsListViewModel
回想一下,UI层由UI元素和状态持有者层组成:

此时我们仍然不知道我们将使用什么技术来绘制UI,所以我们还不能编写UI元素层。但这没有问题;我们可以继续编写状态持有者,确信一旦我们做出决定,它们就不必改变。这就是优秀架构的更多好处!
编写PlanetsListViewModel的规范
UI将有两个页面,一个用于列出和删除行星,另一个用于添加或编辑行星。 PlanetsListViewModel负责前者。这意味着它需要向行星列表屏幕的UI元素公开数据,并且必须准备好接收来自UI元素的事件,以便用户执行操作。
具体而言,我们的PlanetsListViewModel需要公开:
- 描述页面当前状态的Flow(关键是包括行星列表)
- 刷新列表的方法
- 删除行星的方法
- 添加一些示例行星的方法,以帮助用户了解应用程序的功能
PlanetsListUiState对象:页面的当前状态
我发现将页面的整个状态封装在一个单独的数据类中非常有用:
//PlanetsListViewModel.kt
data class PlanetsListUiState(val planets: List<Planet> = emptyList(),val isLoading: Boolean = false,val isError: Boolean = false
)
注意我已经在与视图模型相同的文件中定义了这个类。它仅包含简单的对象:没有Flows等,只有原始类型,数组和简单的数据类。请注意,所有字段都有默认值-这在后面会有帮助。
(有一些很好的原因,你可能甚至不希望在上面的类中出现Planet对象。Clean Architecture的纯粹主义者会指出,在定义Planet的位置和使用它的位置之间有太多的层级跳转。状态提升原则告诉我们只提供我们需要的确切数据。例如,现在我们只需要Planet的名称和距离,所以我们应该只有这些,而不是整个Planet对象。个人认为这样做会不必要地使代码复杂化,并且会使将来的更改更加困难,但你可以自由选择不同意见!)
因此,定义了这个类后,我们现在可以在视图模型内部创建一个状态变量来公开它:
//PlanetsListViewModel.kt
package com.tdcolvin.planetspotters.ui.planetslist...@HiltViewModel
class PlanetsListViewModel @Inject constructor(planetsRepository: PlanetsRepository
): ViewModel() {private val planets = planetsRepository.getPlanetsFlow()val uiState = planets.map { planets ->when (planets) {is WorkResult.Error -> PlanetsListUiState(isError = true)is WorkResult.Loading -> PlanetsListUiState(isLoading = true)is WorkResult.Success -> PlanetsListUiState(planets = planets.data)}}.stateIn(scope = viewModelScope,started = SharingStarted.WhileSubscribed(5000),initialValue = PlanetsListUiState(isLoading = true))
}
注意在.stateIn(...)中使用的scope和started参数可以安全地限制此StateFlow的生命周期。
添加示例行星
为了添加我们的3个示例行星,我们重复调用了为此目的创建的用例。
//PlanetsListViewModel.kt
fun addSamplePlanets() {viewModelScope.launch {val planets = arrayOf(Planet(name = "Skaro", distanceLy = 0.5F, discovered = Date()),Planet(name = "Trenzalore", distanceLy = 5F, discovered = Date()),Planet(name = "Galifrey", distanceLy = 80F, discovered = Date()),)planets.forEach { addPlanetUseCase(it) }}
}
刷新和删除
刷新和删除函数非常类似,只需调用相应的存储库函数即可。
//PlanetsListViewModel.kt
fun deletePlanet(planetId: String) {viewModelScope.launch {planetsRepository.deletePlanet(planetId)}
}fun refreshPlanetsList() {viewModelScope.launch {planetsRepository.refreshPlanets()}
}
第6步:编写AddEditPlanetViewModel
AddEditPlanetViewModel用于管理用于添加新行星或编辑现有行星的屏幕。
与之前的做法一样——实际上,对于任何视图模型来说,这都是一个很好的实践——我们将为UI显示的所有内容定义一个数据类,并为其创建单一的数据来源。
//AddEditPlanetViewModel.kt
data class AddEditPlanetUiState(val planetName: String = "",val planetDistanceLy: Float = 1.0F,val planetDiscovered: Date = Date(),val isLoading: Boolean = false,val isPlanetSaved: Boolean = false
)@HiltViewModel
class AddEditPlanetViewModel @Inject constructor(): ViewModel() {private val _uiState = MutableStateFlow(AddEditPlanetUiState())val uiState: StateFlow<AddEditPlanetUiState> = _uiState.asStateFlow()
}
如果我们正在编辑一个行星(而不是添加新行星),我们希望视图的初始状态反映该行星的当前状态。
作为良好的实践,这个屏幕只会传递我们要编辑的行星的ID。(我们不传递整个行星对象——它可能会变得过于庞大和复杂)。Android的生命周期组件提供了SavedStateHandle,我们可以从中获取行星ID并加载行星对象。
//AddEditPlanetViewModel.kt
@HiltViewModel
class AddEditPlanetViewModel @Inject constructor(savedStateHandle: SavedStateHandle,private val planetsRepository: PlanetsRepository
): ViewModel() {private val planetId: String? = savedStateHandle[PlanetsDestinationsArgs.PLANET_ID_ARG]private val _uiState = MutableStateFlow(AddEditPlanetUiState())val uiState: StateFlow<AddEditPlanetUiState> = _uiState.asStateFlow()init {if (planetId != null) {loadPlanet(planetId)}}private fun loadPlanet(planetId: String) {_uiState.update { it.copy(isLoading = true) }viewModelScope.launch {val result = planetsRepository.getPlanetFlow(planetId).first()if (result !is WorkResult.Success || result.data == null) {_uiState.update { it.copy(isLoading = false) }}else {val planet = result.data_uiState.update {it.copy(isLoading = false,planetName = planet.name,planetDistanceLy = planet.distanceLy,planetDiscovered = planet.discovered)}}}}
}
注意我们如何使用以下模式更新UI状态:
_uiState.update { it.copy( ... ) }
在一行简单的代码中,它创建一个新的AddEditPlanetUiState,其值是从先前的状态复制过来的,并通过uiState Flow发送出去。
这里是我们用该技术更新行星的各种属性的函数:
//AddEditPlanetViewModel.kt
fun setPlanetName(name: String) {_uiState.update { it.copy(planetName = name) }
}fun setPlanetDistanceLy(distanceLy: Float) {_uiState.update { it.copy(planetDistanceLy = distanceLy) }
}
最后,我们使用AddPlanetUseCase保存行星对象:
//AddEditPlanetViewModel.kt
class AddEditPlanetViewModel @Inject constructor(private val addPlanetUseCase: AddPlanetUseCase,...
): ViewModel() {...fun savePlanet() {viewModelScope.launch {addPlanetUseCase(Planet(planetId = planetId,name = _uiState.value.planetName,distanceLy = uiState.value.planetDistanceLy,discovered = uiState.value.planetDiscovered))_uiState.update { it.copy(isPlanetSaved = true) }}}...}
第7步:编写数据源和UI元素
现在我们已经建立了整个架构,可以编写最低层的代码,即UI元素和数据源。对于UI元素,我们可以选择使用Jetpack Compose来支持手机和平板电脑。对于本地数据源,我们可以编写一个使用Room数据库的缓存,而对于远程数据源,我们可以模拟访问远程API。
这些层应该尽可能保持薄。例如,UI元素的代码不应包含任何计算或逻辑,只需纯粹地将视图模型提供的状态显示在屏幕上。逻辑应该放在视图模型中。
对于数据源,只需编写最少量的代码来实现LocalDataSource和RemoteDataSource接口中的函数。
特定的第三方技术(如Compose和Room)超出了本教程的范围,但您可以在代码存储库中看到这些层的示例实现。
将低级部分留在最后
请注意,我们能够将这些应用的最低级部分留到最后。这非常有益,因为它允许利益相关者有足够的时间来做出关于使用哪些第三方技术以及应用应该如何展示的决策。即使在我们编写了这些代码之后,我们也可以更改这些决策,而不会影响应用的其余部分。
Github地址
完整的代码存储库在:
https://github.com/tdcolvin/PlanetSpotters。










——C语言(进阶))


)
)




