大家好,机器学习模型已经成为多个行业决策过程中的重要组成部分,然而在处理嘈杂或多样化的数据集时,它们往往会遇到困难,这就是集成学习(Ensemble Learning)发挥作用的地方。
本文将揭示集成学习的奥秘,并介绍其强大的随机森林算法,通过本文将全面了解集成学习以及Python中随机森林的工作原理。
集成学习概论
集成学习是一种机器学习方法,它将多个弱模型的预测结果组合在一起,以获得更强的预测结果,集成学习的概念是通过充分利用每个模型的预测能力来减少单个模型的偏差和错误。
为了更好地理解,接下来举一个生活中的例子,假设你看到了一种动物,但不知道它属于哪个物种。因此询问十位专家,然后由他们中的大多数人投票决定,这就是所谓的“硬投票”。
硬投票是指考虑到每个分类器的类别预测,然后根据具有最大投票数的类别将输入进行分类。另一方面,软投票是指考虑每个分类器对每个类别的概率预测,然后根据该类别的平均概率(在分类器概率的平均值上取得)将输入分类到具有最大概率的类别。
集成学习总是用于提高模型性能,包括提高分类准确度和降低回归模型的平均绝对误差。此外,集成学习总能产生更稳定的模型。当模型之间没有相关性时,集成学习的效果最好,因为这样每个模型都可以学习到独特的内容,从而提高整体性能。
集成学习策略
尽管集成学习可以以多种方式应用在很多方面,但在实践中,有三种策略因其易于实施和使用而广受欢迎。这三种策略分别是:
-
装袋法(Bagging):Bagging是bootstrap aggregation的缩写,是一种集成学习策略,它使用数据集的随机样本来训练模型。
-
堆叠法(Stacking):Stacking是堆叠泛化(stacked generalization)的简称,是一种集成学习策略。在这种策略中,我们训练一个模型,将在数据上训练的多个模型结合起来。
-
提升法(Boosting):提升法是一种集成学习技术,重点在于选择被错误分类的数据来训练模型。
接下来深入探讨每种策略,并看看如何使用Python在数据集上训练这些集成模型。
装袋法集成学习
装袋法使用随机样本数据,并使用学习算法和平均值来获取装袋概率,也称为自助聚合,它将多个模型的结果聚合起来得到一个综合的结果。
该方法涉及以下步骤:
-
将原始数据集分割成多个子集,并进行替换。
-
为每个子集开发基础模型。
-
在运行所有预测之前,同时运行所有模型,并将所有预测结果汇总以获得最终预测结果。
Scikit-learn提供了实现BaggingClassifier和BaggingRegressor的能力。BaggingMetaEstimator可以识别原始数据集的随机子集以适应每个基础模型,然后通过投票或平均的方式将各个基础模型的预测结果聚合成最终预测结果,该方法通过随机化构建过程来减少差异。
【Scikit-learn】:https://scikit-learn.org/stable/
接下来本文以一个示例来说明如何使用scikit-learn中的装袋估计器:
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
bagging = BaggingClassifier(base_estimator=DecisionTreeClassifier(),n_estimators=10, max_samples=0.5, max_features=0.5)
装袋分类器需要考虑几个参数:
-
base_estimator:装袋方法中使用的基础模型。这里我们使用决策树分类器。
-
n_estimators:装袋方法中将使用的估计器数量。
-
max_samples:每个基础估计器将从训练集中抽取的样本数。
-
max_features:用于训练每个基础估计器的特征数量。
现在,本文将在训练集上拟合该分类器并进行评分。
bagging.fit(X_train, y_train)
bagging.score(X_test,y_test)
对于回归任务,我们也可以做类似的操作,不同之处在于我们将使用回归估计器。
from sklearn.ensemble import BaggingRegressor
bagging = BaggingRegressor(DecisionTreeRegressor())
bagging.fit(X_train, y_train)
model.score(X_test,y_test)堆叠集成学习
堆叠是一种将多个估计器组合在一起以减小它们的偏差并产生准确预测的技术。然后将每个估计器的预测结果进行组合,并输入到通过交叉验证训练的最终预测元模型中;堆叠可以应用于分类和回归问题。
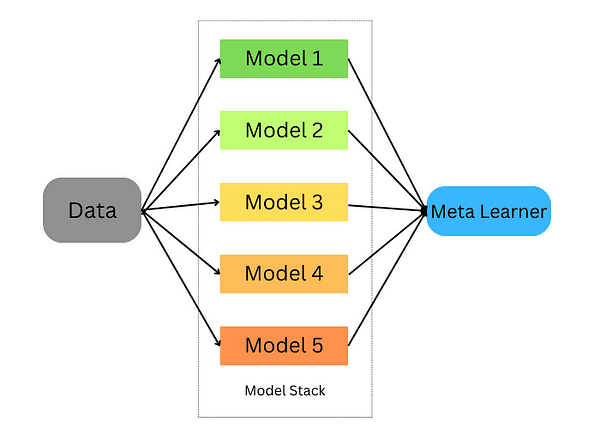
堆叠集成学习
堆叠的步骤如下:
-
将数据分为训练集和验证集。
-
将训练集分为K个折叠。
-
在K-1个折叠上训练基础模型,并在第K个折叠上进行预测。
-
重复步骤3,直到对每个折叠都有一个预测结果。
-
在整个训练集上拟合基础模型。
-
使用该模型对测试集进行预测。
-
对其他基础模型重复步骤3-6。
-
使用测试集的预测结果作为新模型(元模型)的特征。
-
使用元模型对测试集进行最终预测。
在下面的示例中,本文首先创建两个基础分类器(RandomForestClassifier和GradientBoostingClassifier)和一个元分类器(LogisticRegression),然后使用K折交叉验证从这些分类器的预测结果(iris数据集上的训练数据)中提取特征用于元分类器(LogisticRegression)的训练。
在使用K折交叉验证将基础分类器在测试数据集上进行预测,并将这些预测结果作为元分类器的输入特征后,再使用这两者的预测结果进行测试集上的预测,并将其准确性与堆叠集成模型进行比较。
# 加载数据集
data = load_iris()
X, y = data.data, data.target# 将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义基础分类器
base_classifiers = [RandomForestClassifier(n_estimators=100, random_state=42),GradientBoostingClassifier(n_estimators=100, random_state=42)
]# 定义元分类器
meta_classifier = LogisticRegression()# 创建一个数组来保存基础分类器的预测结果
base_classifier_predictions = np.zeros((len(X_train), len(base_classifiers)))# 使用K折交叉验证进行堆叠
kf = KFold(n_splits=5, shuffle=True, random_state=42)
for train_index, val_index in kf.split(X_train):train_fold, val_fold = X_train[train_index], X_train[val_index]train_target, val_target = y_train[train_index], y_train[val_index]for i, clf in enumerate(base_classifiers):cloned_clf = clone(clf)cloned_clf.fit(train_fold, train_target)base_classifier_predictions[val_index, i] = cloned_clf.predict(val_fold)# 在基础分类器预测的基础上训练元分类器
meta_classifier.fit(base_classifier_predictions, y_train)# 使用堆叠集成进行预测
stacked_predictions = np.zeros((len(X_test), len(base_classifiers)))
for i, clf in enumerate(base_classifiers):stacked_predictions[:, i] = clf.predict(X_test)# 使用元分类器进行最终预测
final_predictions = meta_classifier.predict(stacked_predictions)# 评估堆叠集成的性能
accuracy = accuracy_score(y_test, final_predictions)
print(f"Stacked Ensemble Accuracy: {accuracy:.2f}")提升集成学习
提升(Boosting)是一种机器学习的集成技术,通过将弱学习器转化为强学习器来减小偏差和方差。这些弱学习器按顺序应用于数据集,首先创建一个初始模型并将其拟合到训练集上。一旦第一个模型的错误被识别出来,就会设计另一个模型来进行修正。
有一些流行的算法和实现方法用于提升集成学习技术,接下来将探讨其中最著名的几种。
- AdaBoost
AdaBoost是一种有效的集成学习技术,通过按顺序使用弱学习器进行训练。每次迭代都会优先考虑错误的预测结果,同时减小分配给正确预测实例的权重;这种策略性地强调具有挑战性的观察结果,使得AdaBoost随着时间的推移变得越来越准确,其最终的预测结果由弱学习器的多数投票或加权总和决定。
AdaBoost是一种通用的算法,适用于回归和分类任务,但在这里本文更关注它在分类问题上的应用,使用Scikit-learn进行演示。接下来看看如何在下面的示例中将其应用于分类任务:
from sklearn.ensemble import AdaBoostClassifier
model = AdaBoostClassifier(n_estimators=100)
model.fit(X_train, y_train)
model.score(X_test,y_test)
在这个示例中,本文使用了Scikit-learn中的AdaBoostClassifier,并将n_estimators设置为100。默认的学习器是决策树,用户可以进行更改。此外,还可以调整决策树的参数。
-
极限梯度提升(XGBoost)
极限梯度提升(eXtreme Gradient Boosting),更常被称为XGBoost,是提升集成学习算法中最佳的实现之一,由于其并行计算能力,在单台计算机上运行非常高效,可以通过机器学习社区开发的xgboost软件包来使用XGBoost。
import xgboost as xgb
params = {"objective":"binary:logistic",'colsample_bytree': 0.3,'learning_rate': 0.1,'max_depth': 5, 'alpha': 10}
model = xgb.XGBClassifier(**params)
model.fit(X_train, y_train)
model.fit(X_train, y_train)
model.score(X_test,y_test)
- LightGBM
LightGBM是另一种基于树学习的梯度提升算法,但与其他基于树的算法不同的是,它使用基于叶子的树生长方式,这使其收敛更快。
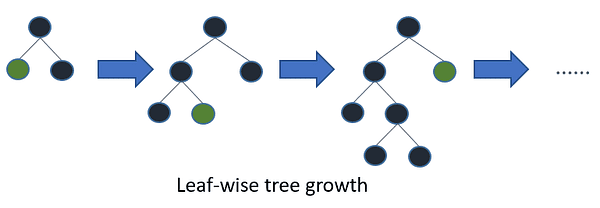
树叶的生长/图片来源:LightGBM
在下面的示例中,本文将使用LightGBM解决一个二元分类问题:
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train)
lgb_eval = lgb.Dataset(X_test, y_test, reference=lgb_train)
params = {'boosting_type': 'gbdt','objective': 'binary','num_leaves': 40,'learning_rate': 0.1,'feature_fraction': 0.9}
gbm = lgb.train(params,lgb_train,num_boost_round=200,valid_sets=[lgb_train, lgb_eval],valid_names=['train','valid'],)综上所述,集成学习和随机森林是强大的机器学习模型,机器学习从业者和数据科学家经常使用它们。本文中介绍了提升集成学习的基本原理、应用场景,并介绍了其中最受欢迎的算法及其在Python中的使用方法。













-开发飞书小程序Demo)





