调度
- 一、Kurbernetes的list-watch机制
- 1.1 list-watch机制简介
- 1.2 创建pod的流程(结合list-watch机制)
- 二、Scheduler的调度策略
- 2.1 简介
- 2.2 预选策略(predicate)
- 2.3 优选策略(priorities)
- 三、标签管理
- 3.1 查看标签的帮助信息
- 3.2 查看标签信息
- 3.3 添加标签
- 3.4 修改标签
- 3.5 删除标签
- 3.6 根据标签值查找资源对象
- 四、kubernetes对Pod的调度策略
- 五、定向调度
- 5.1 调度策略简介
- 5.2 调度实例
- 5.2.1 通过nodeName字段
- 5.2.2 通过nodeSelector字段
- 配置
- 测试
- 六、亲和性调度
- 6.1 Node亲和性
- 6.2 Pod亲和性
- 6.3 Pod反亲和性
- 6.4 拓扑域
- 6.4.1 拓扑域的定义
- 6.4.2 如何判断是否在同一个拓扑域?
- 6.5 亲和性的策略
- 6.6 亲和性调度实例
- 6.6.1 node亲和性
- 6.6.2 Pod亲和性
- 6.6.3 Pod反亲和性
- 六、污点和容忍
- 7.1 节点设置污点
- 7.2 Pod设置容忍
- 7.3 调度实例
- 八、Pod启动阶段
- 8.1 Pod启动过程
- 8.2 Pod生命周期的5种状态
- 九、小结
- 9.1 理论部分
- 9.2 K8s常用故障排错流程/手段
一、Kurbernetes的list-watch机制
1.1 list-watch机制简介
Kubernetes 通过 List-Watch 的机制进行每个组件的协作,保持数据同步,每个组件之间的设计实现了解耦。
list 机制,通过调用资源的list API罗列资源,基于HTTP短链接实现;
watch机制,通过调用资源的watch API监听资源变更事件,基于HTTP 长链接实现
这种机制对于需要持续跟踪 Kubernetes 集群中资源的状态变化的应用程序非常有用,例如自动伸缩、监控、日志收集等。
1.2 创建pod的流程(结合list-watch机制)
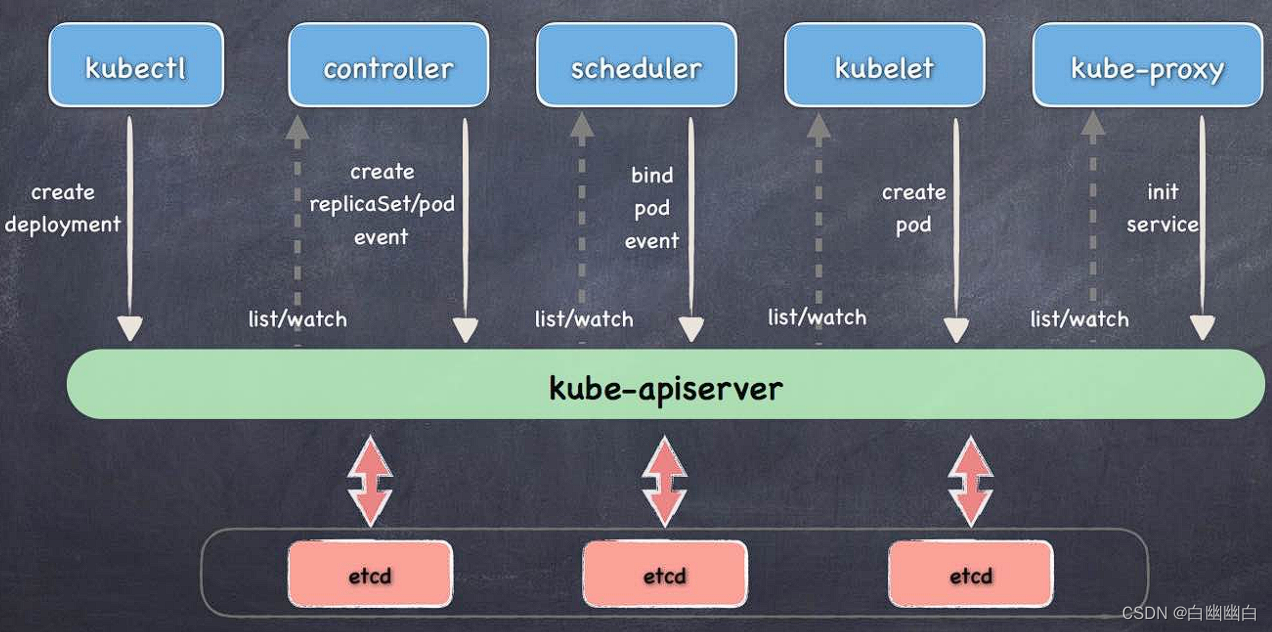
1)客户端向apiserver发送创建Pod的请求,然后apiserver将请求信息存入到etcd中;
2)存入完成后,etcd会通过apiserver发送创建Pod资源的事件;
3)controller manager通过list-watch机制监听apiserver发送出来的事件,并创建相关的Pod资源,创建完成后,通过apiserver将信存入到etcd中
4) etcd存入更新信息之后,再次通过apiserver发送调度Pod资源的事件;
5)scheduler通过list-watch机制监听到apiserver发出的调度事件,通过调度算法,将Pod资源调度到合适的node节点上,调度完成后通过apiserver将调度完成后的信息更新到etcd中;
6)etcd收到更新信息后,再次向apiserver发送创建Pod的事件;
7)kubelet通过list-watch机制监听apiserver发出的创建Pod的事件,然后根据事件信息,在相应的node节点完成Pod的创建。
二、Scheduler的调度策略
2.1 简介
Scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。
Sheduler 是作为单独的程序运行的,启动之后会一直监听 APIServer,获取 spec.nodeName 为空的 pod,对每个 pod 都会创建一个 binding,表明该 pod 应该放到哪个节点上。
调度规则
1)公平:如何保证每个节点都能被分配资源
2)资源高效利用:集群所有资源最大化被使用
3)效率:调度的性能要好,能够尽快地对大批量的 pod 完成调度工作
4)灵活:允许用户根据自己的需求控制调度的逻辑
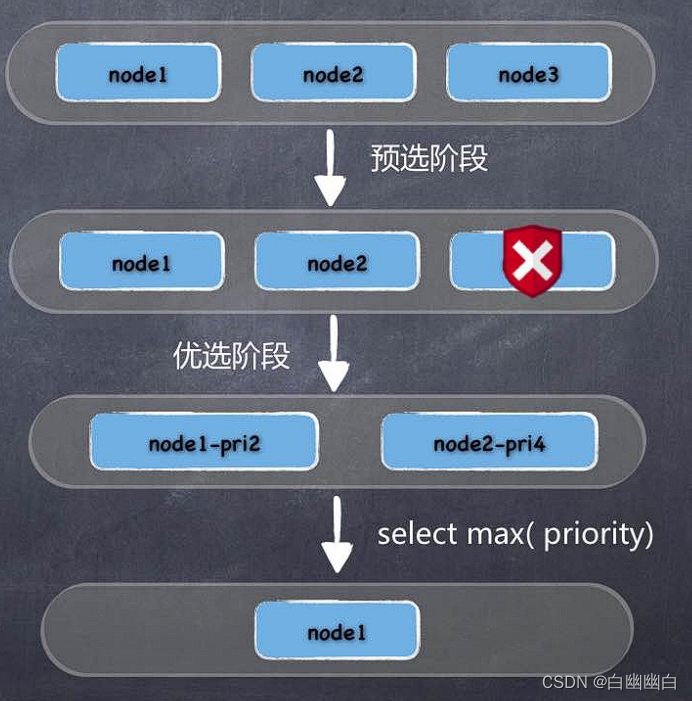
调度的流程
1)首先是过滤掉不满足条件的节点,这个过程称为预算策略(predicate);
2)然后对通过的节点按照优先级排序,这个是优选策略(priorities);
3)最后从中选择优先级最高的节点。如果中间任何一步骤有错误,就直接返回错误。
2.2 预选策略(predicate)
预选策略:过滤掉不满足条件的节点的过程。
| 常见的算法 | 描述 |
|---|---|
PodFitsResources | 节点上剩余的资源是否大于 pod 请求的资源。 |
PodFitsHost | 如果 pod 指定了 NodeName,检查节点名称是否和 NodeName 匹配。 |
PodFitsHostPorts | 节点上已经使用的 port 是否和 pod 申请的 port 冲突。 |
PodSelectorMatches | 过滤掉和 pod 指定的 label 不匹配的节点。 |
NoDiskConflict | 已经 mount 的 volume 和 pod 指定的 volume 不冲突,除非它们都是只读。 |
如果在 predicate 过程中没有合适的节点,pod 会一直在 Pending 状态`,不断重试调度,直到有节点满足条件。
2.3 优选策略(priorities)
**优选策略:**对通过的节点按照优先级排序。
优先级由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。
| 常见的优先级选项 | 描述 |
|---|---|
LeastRequestedPriority | 通过计算CPU和Memory的使用率来决定权重,使用率越低权重越高。也就是说,这个优先级指标倾向于资源使用比例更低的节点。 |
BalancedResourceAllocation | 节点上 CPU 和 Memory 使用率越接近,权重越高。这个一般和上面的一起使用,不单独使用。比如 node01 的 CPU 和 Memory 使用率 20:60,node02 的 CPU 和 Memory 使用率 50:50,虽然 node01 的总使用率比 node02 低,但 node02 的 CPU 和 Memory 使用率更接近,从而调度时会优选 node02。 |
ImageLocalityPriority | 倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高。 |
通过算法对所有的优先级项目和权重进行计算,得出最终的结果。
三、标签管理
#基本语法
kubectl label <资源类型> <资源名称> <标签键>=<标签值> [options]
| 字段 | 功能 | |
|---|---|---|
<资源类型> | 要添加或修改标签的资源类型 | 如 pod、deployment、service 等 |
<资源名称> | 要添加或修改标签的资源对象的名称 | |
<标签键>=<标签值> | 要添加或修改的标签及其对应的值 |
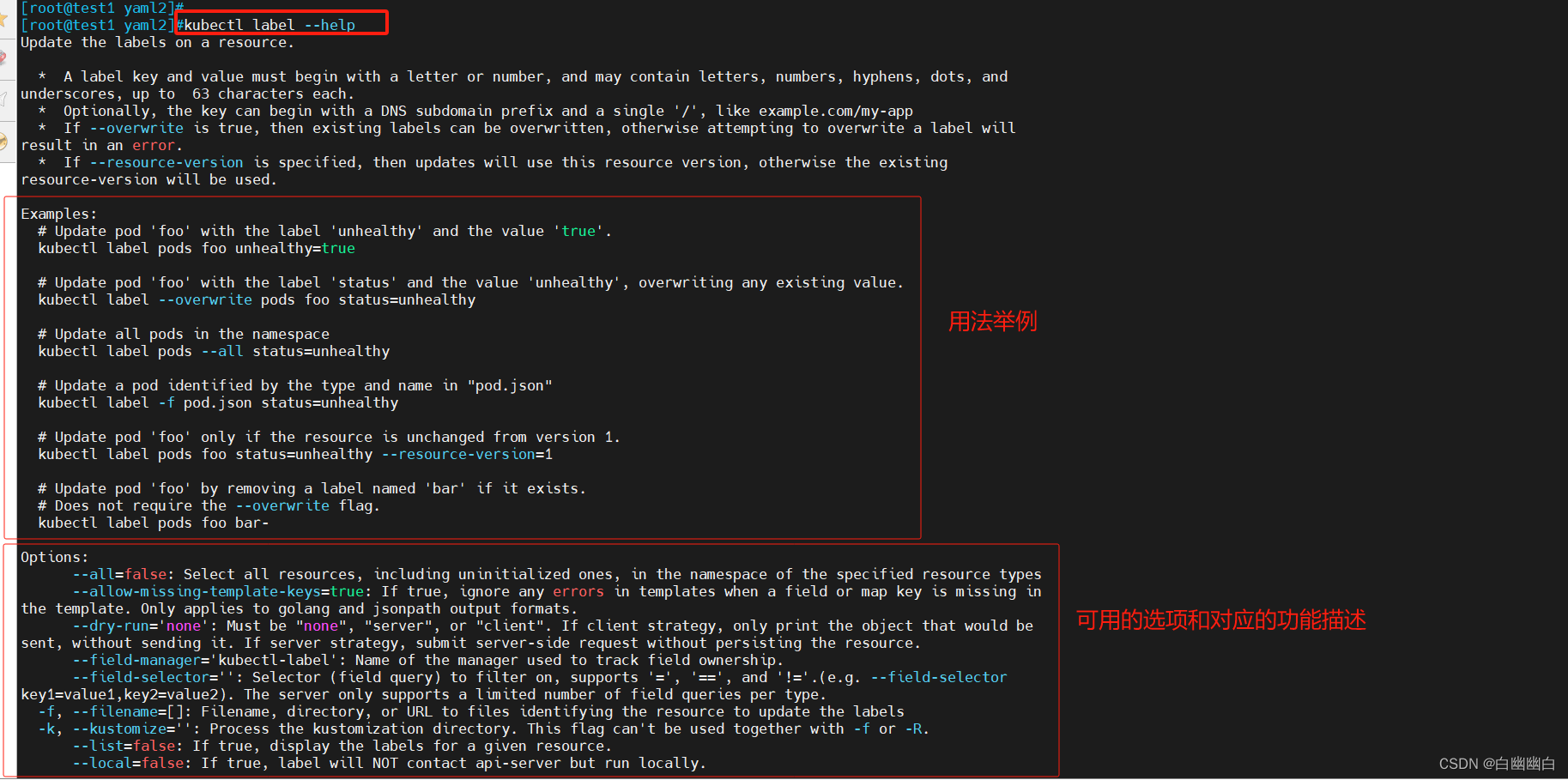
3.1 查看标签的帮助信息
kubectl label --help
3.2 查看标签信息
--show-labels选项
#基本语法
kubectl get <资源类型> [<资源名称>] [-n namespace] --show-labels
举个例子
#查看指定命名空间中所有pod的标签
kubectl get pods -n my-ns --show-labels

3.3 添加标签
使用 kubectl label 命令可以为资源对象添加标签,在命令中指定资源类型、名称和要添加的标签及其值。
kubectl label <资源类型> <资源名称> [-n namespce] key=value
key=value 表示要添加或修改的标签键值对。
键(key)是一个字符串,可以是任何你指定的名字;
值(value)是一个字符串,可以是任何你指定的值。
键和值之间使用等号(=)连接。
举个例子
#为名为 nginx-test1 的 Pod 添加app=backend 和 version=1.15 两个标签
kubectl label pod nginx-test1 -n my-ns app=backend version=1.15

3.4 修改标签
使用--overwrite选项 可以修改已存在的标签值。
如果不使用该选项,则只会添加新标签或更新值不同的标签。
#基本格式
kubectl label <资源类型> <资源名称> <标签键>=<新标签值> --overwrite
举个例子
kubectl label pod nginx-test1 -n my-ns app=1234 version=1222 --overwrite

3.5 删除标签
要删除 Kubernetes 资源对象的标签,可以使用 kubectl label 命令,将标签值设置为空。
#基本格式
kubectl label <资源类型> <资源名称> <标签键>-
使用 -(减号)指示要删除标签。
删除标签不会删除整个资源对象,只会删除指定的标签键和值。
举个例子
#删除app标签
kubectl label pod nginx-test1 -n my-ns app-

3.6 根据标签值查找资源对象
-l选项,根据标签值查找 Kubernetes 资源对象。
标签选择器支持逻辑操作符(例如逗号表示逻辑与)和等价性操作符(= 表示等于)。
#基本格式
kubectl get/describe <资源类型> -l key[=value]
使用 kubectl get 命令和自定义选择器查询语句来进行更复杂的标签筛选。
使用 kubectl describe 命令查找具有指定标签的资源对象的详细信息。
举个例子
kubectl get pod -n my-ns -l app
kubectl get pod -n my-ns -l version
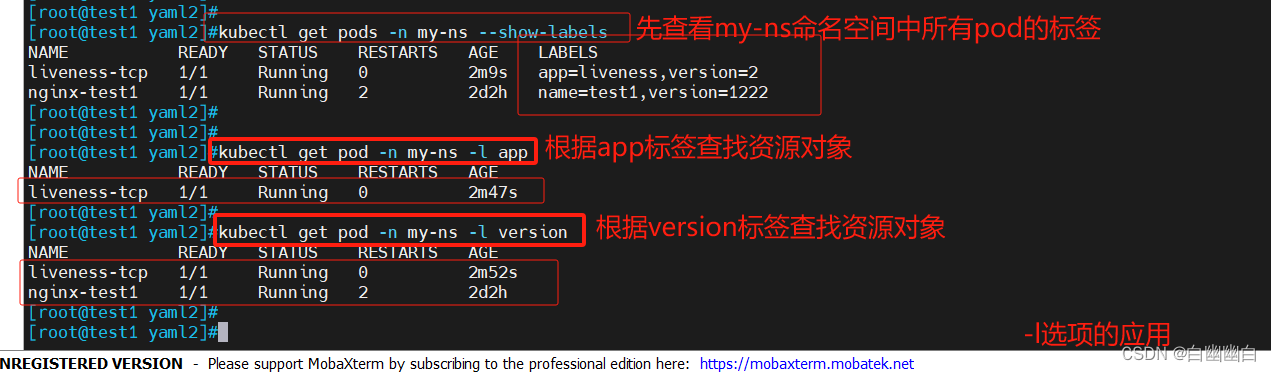
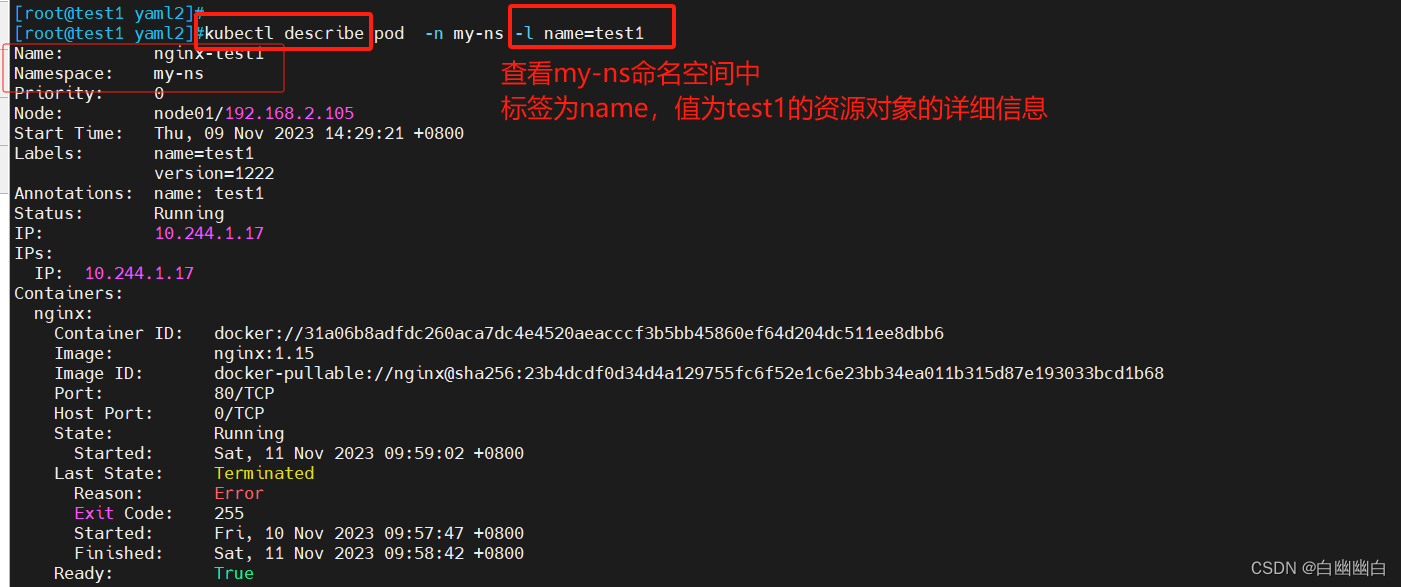
kubectl describe pod -n my-ns -l name=test1
四、kubernetes对Pod的调度策略
在 Kubernetes 中,调度 是指将 Pod 放置到合适的节点上,以便对应节点上的 Kubelet 能够运行这些 Pod。
1)定向调度: 使用 nodeName 字段指定node节点名称;使用 nodeSelector 字段指定node节点的标签;
2)亲和性调度: 使用 节点/Pod 亲和性(NodeAffinity、PodAffinity、PodAntiAffinity);
3)污点与容忍: 使用 节点设置污点,结合 Pod设置容忍。
4)全自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出;
#补充,Pod和node的关系
Node 是 Kubernetes 集群中的工作节点
一个 Node 可以运行多个 Pod,而一个 Pod 只能运行在一个 Node 上
使用标签和选择器可以管理 Node 和 Pod 之间的关系,从而实现灵活的调度和管理。
五、定向调度
5.1 调度策略简介
nodeName:指定节点名称,用于将Pod调度到指定的Node上,不经过调度器。
nodeSelector:在 Pod 定义文件的 spec 下的 nodeSelector 字段中设置一个标签选择器,在 Pod 调度的时候,只有具有这些标签的 Node 才会被考虑用来运行这个 Pod。
5.2 调度实例
5.2.1 通过nodeName字段
配置清单文件
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:nodeName: node02containers:- name: my-containerimage: nginx
创建与测试
kubectl apply -f test2.yamlkubectl get pods

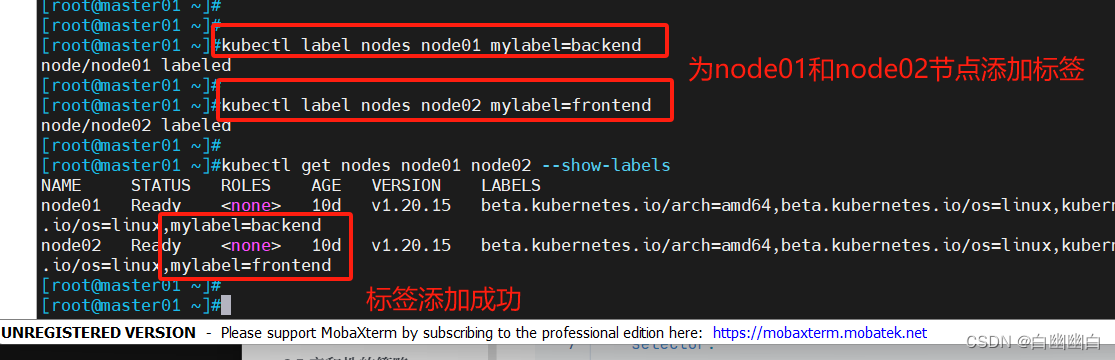
5.2.2 通过nodeSelector字段
配置
1.为在 Kubernetes 集群的节点设置标签
kubectl label nodes node01 mylabel=backend
kubectl label nodes node02 mylabel=frontend
2.创建一个 Deployment
定义 Pod 调度策略为使用 NodeSelector,在创建时选择具有 mylabel=backend 的节点上运行。
apiVersion: apps/v1
kind: Deployment
metadata:name: myapp
spec:replicas: 3selector:matchLabels:app: myapptemplate:metadata:labels:app: myappspec:nodeSelector:mylabel: backendcontainers:- name: myapp-containerimage: nginx
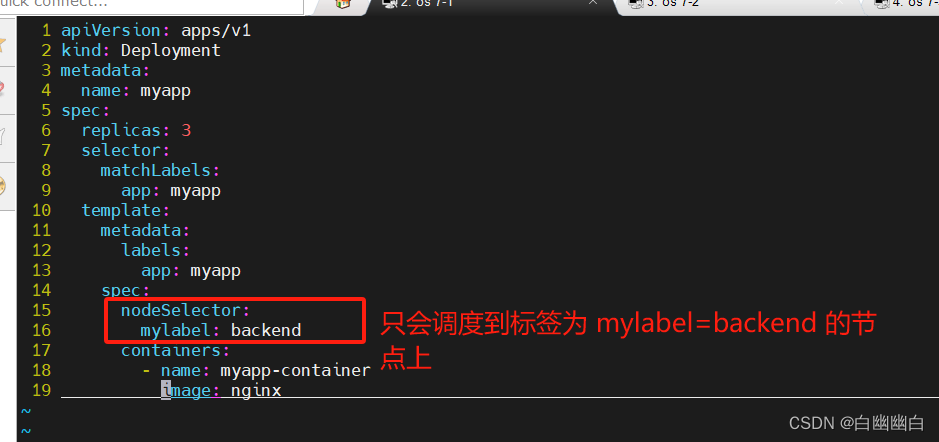
kubectl apply -f test1.yaml
测试
kubectl get pods -o wide

所有的 Pod 都运行在具有 mylabel=backend 的节点上。
六、亲和性调度
官方文档:将 Pod 指派给节点 | Kubernetes
kubectl explain pod.spec.affinity
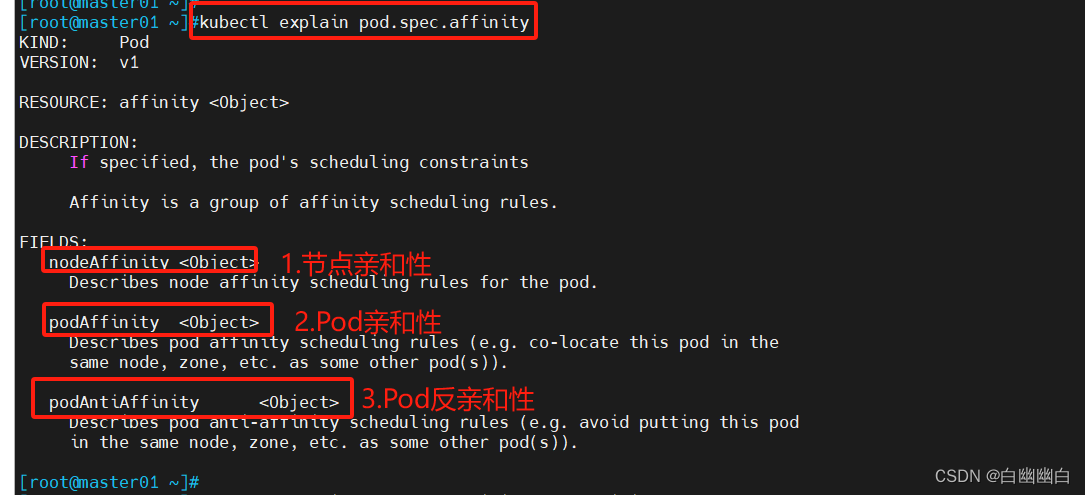
| 键值运算关系 | 描述 |
|---|---|
| In | label 的值在某个列表中 |
| NotIn | label 的值不在某个列表中 |
| Gt | label 的值大于某个值 |
| Lt | label 的值小于某个值 |
| Exists | 某个 label 存在 |
| DoesNotExist | 某个 label 不存在 |
6.1 Node亲和性
节点亲和性(nodeAffinity):匹配指定node节点的标签,将要部署的Pod调度到满足条件的node节点上
6.2 Pod亲和性
Pod亲和性(podAffinity):匹配指定的Pod的标签,将要部署的Pod调度到与指定Pod所在的node节点处于同一个拓扑域的node节点上。
如果有多个node节点属于同一个拓扑域,通过Pod亲和性部署多个Pod时则调度器会试图将Pod均衡的调度到处于同一个拓扑域的node节点上
6.3 Pod反亲和性
Pod反亲和性(podAntiAffinity):匹配指定的Pod的标签,将要部署的Pod调度到与指定Pod所在的node节点处于不同的拓扑域的node节点上
如果有多个node节点不在同一个拓扑域,通过Pod反亲和性部署多个Pod时则调度器会试图将Pod均衡的调度到不在同一个拓扑域的node节点上
6.4 拓扑域
6.4.1 拓扑域的定义
拓扑域(Topology Domain)是用于描述和控制Pod调度和部署的一种机制,它基于节点的拓扑信息来限制Pod的调度位置,以满足用户定义的性能和资源需求。
使用拓扑域特性,可以在Pod的调度过程中指定节点的拓扑约束,这意味着可以定义一个Pod只能被调度到带有某些特定标签的节点上,或者避免被调度到具有某些标签的节点上。
例如,可以指定要求一个Pod只能调度到同一个机架或同一个区域中的节点上,以满足高可用性或数据局部性的需求。
6.4.2 如何判断是否在同一个拓扑域?
通过拓扑域key(topologyKey)判断。
如果有其它node节点拥有,和指定Pod所在的node节点,相同的拓扑域key的标签key和值,那么它们就属于同一个拓扑域。
6.5 亲和性的策略
#查看字段信息
kubectl explain pod.spec.affinity.xxAffinity
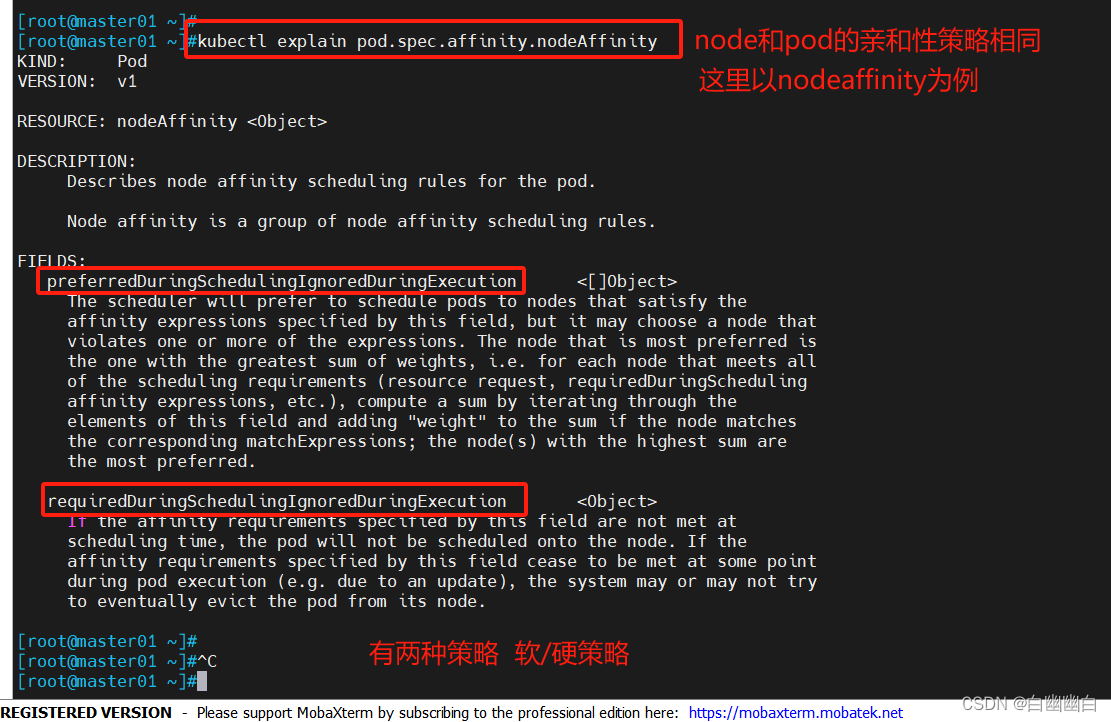
| 字段 | 字段名 | 描述 |
|---|---|---|
| required… | 硬策略 | 强制性的满足条件 如果没有满足条件的node节点,Pod会处于 Pending状态,直到有符合条件的node节点出现 |
| preferred… | 软策略 | 非强制性的,会优先选择满足条件的node节点进行调度 即使没有满足条件的node节点,Pod依然会完成调度 |
如果有多个软策略选项的话,权重越大,优先级越高。
如果把硬策略和软策略合在一起使用,则要先满足硬策略之后才会满足软策略。
6.6 亲和性调度实例
6.6.1 node亲和性
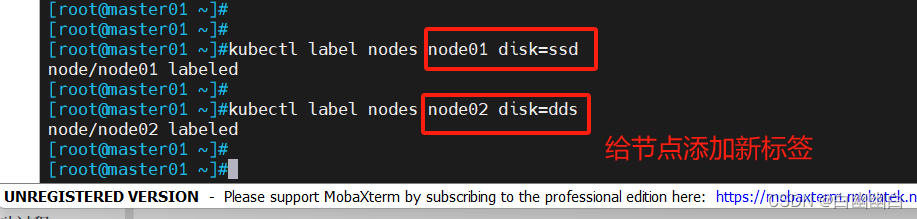
1.添加标签
kubectl label nodes node01 disk=ssd
kubectl label nodes node02 disk=dds
配置清单文件
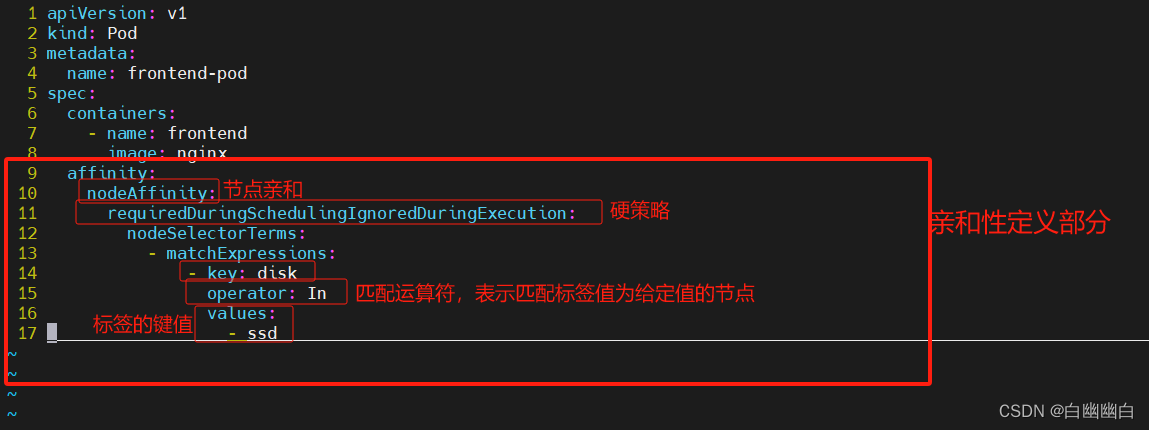
使用节点亲和性调度规则,要求将 Pod 调度到标签为 “disk=ssd” 的节点。
vim pod1.yamlapiVersion: v1
kind: Pod
metadata:name: frontend-pod
spec:containers:- name: frontendimage: nginxaffinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: diskoperator: Invalues:- ssd
创建并测试
kubectl apply -f pod1.yaml -n my-ns
kubectl get pods -n my-ns -o wide

6.6.2 Pod亲和性
多个pod在一个节点
添加标签
kubectl label nodes node01 app=backend
kubectl label nodes node02 app=frontend
配置清单文件
apiVersion: v1
kind: Pod
metadata:name: frontend-pod
spec:containers:- name: frontendimage: nginxaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: NotInvalues:- frontendtopologyKey: "kubernetes.io/hostname"
---
apiVersion: v1
kind: Pod
metadata:name: backend-pod
spec:containers:- name: backendimage: mysqlaffinity:podAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: NotInvalues:- backendtopologyKey: "kubernetes.io/hostname"
创建并测试
kubectl apply -f pod2.yaml -n my-ns
kubectl get pods -n my-ns -o wide

Kubernetes 将会创建一个具有 Pod Anti-Affinity 配置的 Deployment,确保这三个 Pod 尽量运行在不同的节点上。
6.6.3 Pod反亲和性
多个pod不在同一个节点
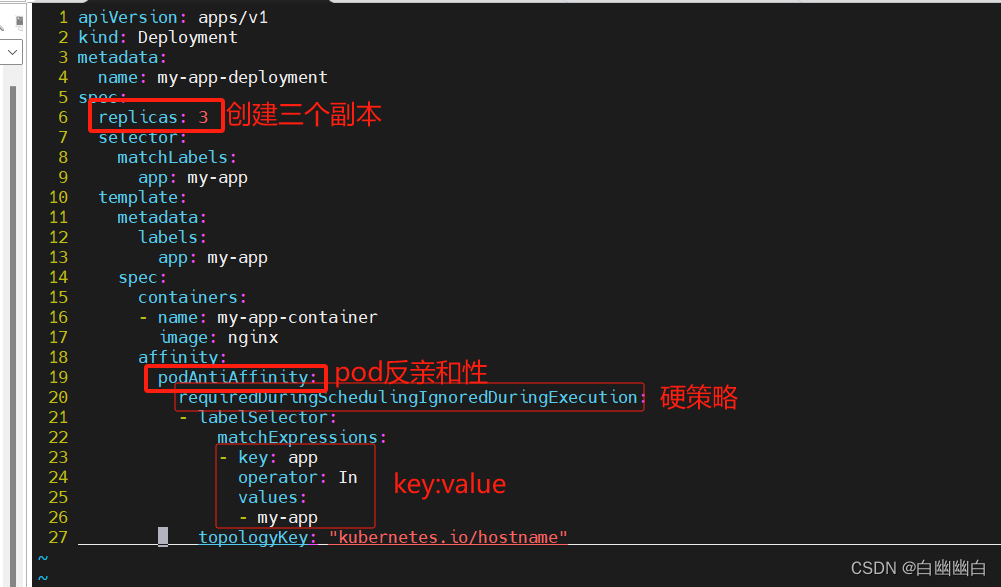
配置清单文件
apiVersion: apps/v1
kind: Deployment
metadata:name: my-app-deployment
spec:replicas: 3selector:matchLabels:app: my-apptemplate:metadata:labels:app: my-appspec:containers:- name: my-app-containerimage: my-app-imageaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: appoperator: Invalues:- my-apptopologyKey: "kubernetes.io/hostname"
创建并测试
kubectl apply -f pod3.yaml -n my-ns
kubectl get pods -n my-ns -o wide

六、污点和容忍
通过使用污点和容忍机制,可以更精确地控制Pod的调度行为,确保Pod被调度到满足特定条件的节点上。
7.1 节点设置污点
基本概念
在 Kubernetes 中,Node(节点)上的污点(Taint)是用于标记节点的属性,以控制 Pod(容器)在节点上的调度行为。
通过给节点打上污点,可以限制节点上可以调度的 Pod,从而实现更精细的调度策略。
污点由三个部分组成:
- Key(键):标记的名称。
- Value(值):标记的值,可选。
- Effect(作用):标记的作用。
污点的组成格式如下:
key=value:effect
| taint effect 支持的选项 | 描述 | |
|---|---|---|
NoSchedule | 一定不会被调度 | 表示 k8s 将不会将 Pod 调度到具有该污点的 Node 上 |
PreferNoSchedule | 尽量不被调度 | 表示 k8s 将尽量避免将 Pod 调度到具有该污点的 Node 上 |
NoExecute | 不会被调度,并驱逐Pod | 表示 k8s 将不会将 Pod 调度到具有该污点 |
相关命令
#给节点打上污点
kubectl taint node <node名称> key=[value]:effect#覆盖现有的污点
kubectl taint node <node名称> key=[value]:effect --overwrite#删除
kubectl taint node <node名称> key[=value:effect]-kubectl describe nodes <node名称> | grep Taints
##举个例子##
#给名为 `node-1` 的节点打上键为 `special`,值为 `true` 的污点,并设置作用为 `NoSchedule`:
kubectl taint node node-1 special=true:NoSchedule这将导致 Pod 除非声明容忍该污点,否则不会被调度到 `node-1` 节点上。
7.2 Pod设置容忍
Pod 可以使用容忍(Toleration)来声明对污点的容忍,以允许在具有相应污点的节点上调度。
配置清单格式
#Pod设置容忍 toleration
spec:tolerations:- key: 污点键名operator: Equal|Existsvalue: 污点键值effect: NoSchedule|PreferNoSchedule|NoExecute
相关命令
设置node节点不可调用
kubectl cordon <node名称>
kubectl uncordon <node名称>设置node节点不可调用并驱逐Pod
kubectl drain <node名称> --ignore-daemonsets --force --delete-emptydir-data
7.3 调度实例
1.打上污点
kubectl taint node node01 key1=value1:NoSchedule


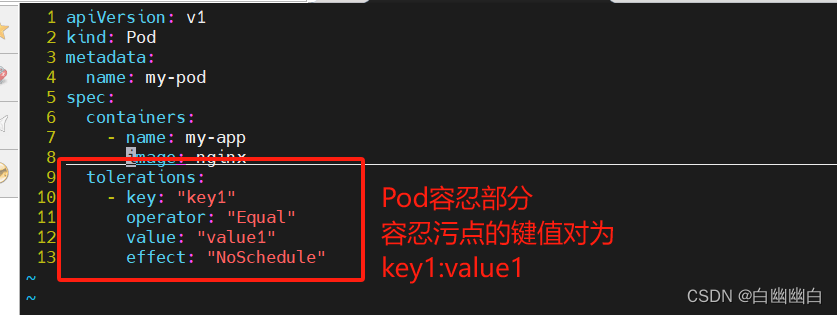
2.编写测试清单文件
apiVersion: v1
kind: Pod
metadata:name: my-pod
spec:containers:- name: my-appimage: my-app-imagetolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"
3.测试
kubectl apply -f pod4.yaml -n my-nskubectl get pod -o wide -n my-ns

八、Pod启动阶段
8.1 Pod启动过程
0)控制器创建Pod副本;
1)调度器scheduler根据调度算法选择一台最适合的node节点调度Pod;
2)kubelet拉取镜像;
3)kubelet挂载存储卷等;
4)kubelet创建并运行容器;
5)kubelet根据容器的探针探测结果设置Pod状态。
8.2 Pod生命周期的5种状态
| 状态 | 描述 |
|---|---|
| Pending | Pod已经创建,但是Pod还处于包括未完成调度到node节点的过程或者还处于在镜像拉取过程中、存储卷挂载失败的情况 |
| Running | Pod所有容器已被创建,且至少有一个容器正在运行 |
| Succeeded | Pod所有容器都已经成功退出,且不再重启。(completed) |
| Failed | Pod所有容器都退出,且至少有一个容器是异常退出的。(error) |
| Unknown | master节点的controller manager无法获取到Pod状态 通常是因为master节点的apiserver与Pod所在node节点的kubelet通信失联导致的 |
九、小结
9.1 理论部分
K8S是通过 List-Watch 机制实现每个组件的协作
controller manager、scheduler、kubelet 通过 List-Watch 机制监听 apiserver 发出的事件,apiserver 通过 List-Watch 机制监听 etcd 发出的事件scheduler的调度策略:
预选策略/预算策略:通过调度算法过滤掉不满足条件的node节点;如果没有满足条件的node节点,Pod会处于Pending状态,直到有符合条件的node节点出现
PodFitsResources、PodFitsHost、PodFitsHostPorts、PodSelectorMatches、NoDiskConflict优选策略:根据优先级选项为满足预选策略条件的node节点进行优先级权重排序,最终选择优先级最高的node节点来调度Pod
LeastRequestedPriority、BalancedResourceAllocation、ImageLocalityPriority标签的管理操作:
kubectl label <资源类型> <资源名称> 标签key=标签value
kubectl label <资源类型> <资源名称> 标签key=标签value --overwrite
kubectl label <资源类型> <资源名称> 标签key-kubectl get <资源类型> [资源名称] --show-labels
kubectl get <资源类型> -l 标签key[=标签value]指定node节点调度Pod的方式:
1)使用 nodeName 字段指定node节点名称
2)使用 nodeSelector 字段指定node节点的标签
3)使用 节点/Pod 亲和性
4)使用 节点设置污点 + Pod设置容忍亲和性:
节点亲和性(nodeAffinity):匹配指定node节点的标签,将要部署的Pod调度到满足条件的node节点上Pod亲和性(podAffinity):匹配指定的Pod的标签,将要部署的Pod调度到与指定Pod所在的node节点处于同一个拓扑域的node节点上如果有多个node节点属于同一个拓扑域,通过Pod亲和性部署多个Pod时则调度器会试图将Pod均衡的调度到处于同一个拓扑域的node节点上Pod反亲和性(podAntiAffinity):匹配指定的Pod的标签,将要部署的Pod调度到与指定Pod所在的node节点处于不同的拓扑域的node节点上如果有多个node节点不在同一个拓扑域,通过Pod反亲和性部署多个Pod时则调度器会试图将Pod均衡的调度到不在同一个拓扑域的node节点上如何判断是否在同一个拓扑域?
通过拓扑域key(topologyKey)判断,如果有其它node节点拥有与指定Pod所在的node节点相同的拓扑域key的标签key和值,那么它们就属于同一个拓扑域亲和性的策略:
硬策略(required....):要强制性的满足条件,如果没有满足条件的node节点,Pod会处于Pending状态,直到有符合条件的node节点出现软策略(preferred....):非强制性的,会优先选择满足条件的node节点进行调度,即使没有满足条件的node节点,Pod依然会完成调度节点设置污点 taint
kubectl taint node <node名称> key=[value]:effectNoSchedule(一定不会被调度) PreferNoSchedule(尽量不被调度) NoExecute(不会被调度,并驱逐Pod)kubectl taint node <node名称> key=[value]:effect --overwritekubectl taint node <node名称> key[=value:effect]-kubectl describe nodes <node名称> | grep TaintsPod设置容忍 toleration
spec:tolerations:- key: 污点键名operator: Equal|Existsvalue: 污点键值effect: NoSchedule|PreferNoSchedule|NoExecute设置node节点不可调用
kubectl cordon <node名称>
kubectl uncordon <node名称>设置node节点不可调用并驱逐Pod
kubectl drain <node名称> --ignore-daemonsets --force --delete-emptydir-dataPod的启动过程:
0)控制器创建Pod副本
1)调度器scheduler根据调度算法选择一台最适合的node节点调度Pod
2)kubelet拉取镜像
3)kubelet挂载存储卷等
4)kubelet创建并运行容器
5)kubelet根据容器的探针探测结果设置Pod状态Pod生命周期的5种状态
Pending Pod已经创建,但是Pod还处于包括未完成调度到node节点的过程或者还处于在镜像拉取过程中、存储卷挂载失败的情况
Running Pod所有容器已被创建,且至少有一个容器正在运行
Succeeded Pod所有容器都已经成功退出,且不再重启。(completed)
Failed Pod所有容器都退出,且至少有一个容器是异常退出的。(error)
Unknown master节点的controller manager无法获取到Pod状态,通常是因为master节点的apiserver与Pod所在node节点的kubelet通信失联导致的(比如kubelet本身出故障)
总结:Pod遵循预定义的生命周期,起始于Pending阶段,如果至少其中有一个主容器正常运行,则进入Running阶段,之后取决于Pod是否有容器以失败状态退出而进入Succeeded或者Failed阶段。9.2 K8s常用故障排错流程/手段
kubectl get pods 查看Pod的运行状态和就绪状态
kubectl describe <资源类型|pods> <资源名称> 查看资源的详细信息和事件描述,主要是针对没有进入Running阶段的排查手段
kubectl logs <pod名称> -c <容器名称> [-p] 查看Pod容器的进程日志,主要是针对进入Running阶段后的排查手段
kubectl exec -it <pod名称> -c <容器名称> sh|bash 进入Pod容器查看容器内部相关的(进程、端口、文件等)状态信息
kubectl debug -it <pod名称> --image=<临时容器的镜像名> --target=<目标容器> 在Pod中创建临时容器进入目标容器进行调试,主要是针对没有调试工具的容器使用
nsenter -n --target <容器pid> 在Pod容器的宿主机使用nsenter转换网络命名空间,直接在宿主机进入目标容器的网络命名空间进行抓包等调试kubectl get nodes 查看node节点运行状态
kubectl describe nodes 查看node节点详细信息和资源描述
kubectl get cs 查看master组件的健康状态
kubectl cluster-info 查看集群信息journalctl -u kubelet -f 跟踪查看kubelet进程日志