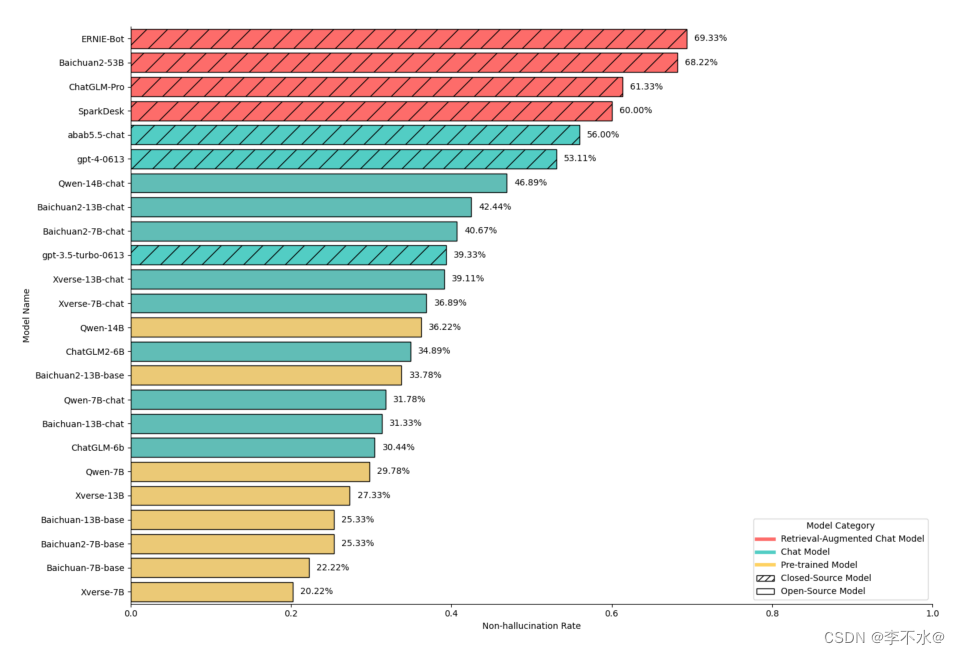
“林黛玉倒拔垂杨柳”、“月球上面有桂树”、“宋江字武松”……相信经常使用大语言模型都会遇到这样“一本正经胡说八道”的情况。这其实是大模型的“幻觉”问题,是大模型行业落地的核心挑战之一。例如幻觉会影响生成内容的可靠性,对于法律、金融、医疗等专业要求高的领域,将难以完成实际场景任务。因此,大模型幻觉问题也被认为是制约大模型广泛应用的一大难题。如何准确评估和解决大语言模型中的幻觉问题已经成为一个至关重要的挑战。近日,复旦大学与上海人工智能实验室构建了针对中文大模型的幻觉评测数据集HalluQA,对业界主流的大模型进行了评估。HalluQA采用无幻觉率来评估大模型的优劣。无幻觉率越高代表模型幻觉越低,事实准确性越高。在评测的24个主流大模型中,包括百度文心一言ERNIE-Bot、百川Baichuan、智谱ChatGLM、阿里通义千问和GPT-4等。
中文大模型幻觉评测数据集
HalluQA对24个主流大模型进行评测从评测结果来看,幻觉问题对大模型来说尚有困难,有18个模型的无幻觉率低于50%。在幻觉消除上,具备检索增强能力的大模型优势明显,在所有模型评测中,文心一言在整体幻觉问题解决方面表现突出,排名第一,整体无幻觉率为69.33%。而GPT-4整体无幻觉率为53.11%,排名第六。
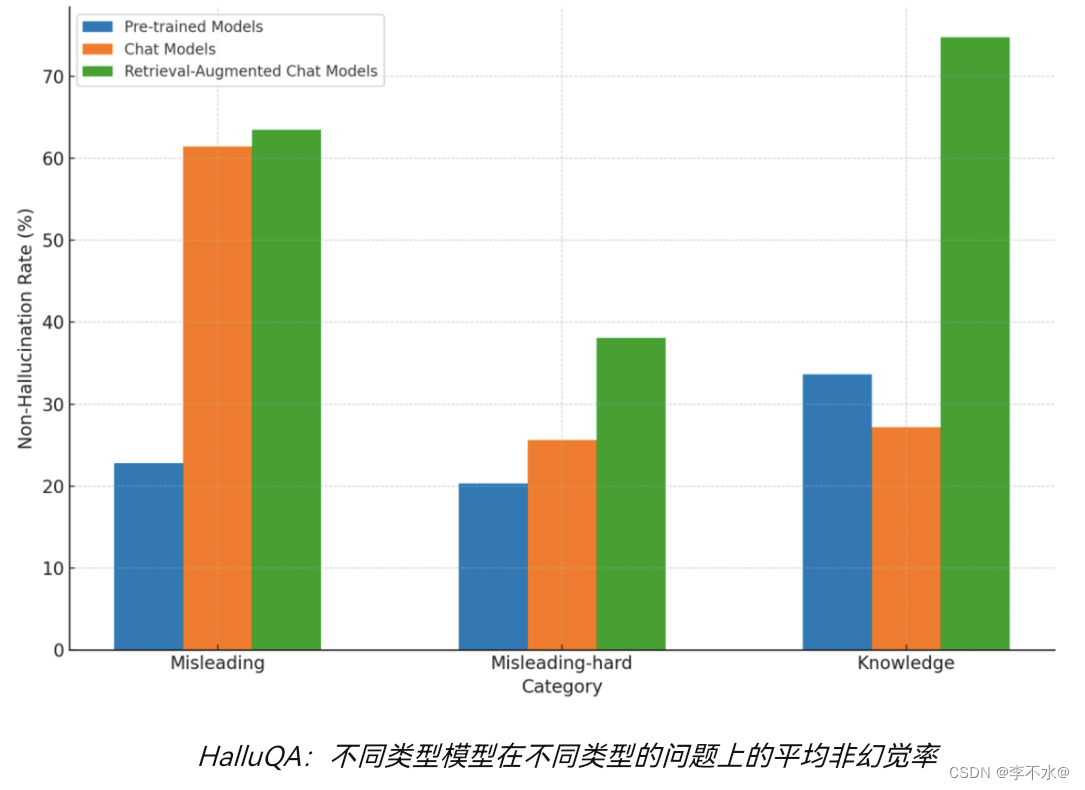
HalluQA:不同类型模型在不同类型的问题上的平均非幻觉率
行业普遍认为,幻觉问题对于大模型在多个领域的落地都可能产生严重影响,包括客户服务、金融服务、法律决策和医疗诊断等。因此解决幻觉问题越好的大模型,才具备更强的产业落地价值。
大模型幻觉成应用落地难题 最新评测文心一言解决幻觉能力最好文心一言解决幻觉能力最好 或成产业应用首选
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.mzph.cn/news/144210.shtml
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

算法-贪心算法-简单-买卖股票的最佳时机
记录一下算法题的学习4
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这…

预览PDF并显示当前页数
这里写目录标题 步骤实例实例效果图 步骤
1.安装依赖
npm install --save vue-pdf2.在需要的页面,引入插件
import pdf from vue-pdf3.使用 单页pdf可以直接使用
<pdf :src"获取到的pdf地址"></pdf>多页pdf通过循环实现 html标签部分
&l…
)
【机器学习基础】机器学习入门(1)
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!后面的内容会越来越有意思~ 💡专栏介绍: 本专栏的第一篇文章,当然要介绍一下了~来说一下这个专栏的开…

EDMA的组成及其作用简介
EDMA是什么?
答:EDMA(Enhanced Direct Memory Access)是一种增强型的直接内存访问技术,用于高效地实现数据传输和处理。它是在传统的DMA(Direct Memory Access)基础上进行改进和扩展的。DMA是一…

大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
说明:每次加载LLM示例后,建议清除缓存,以…
什么是Vite——冷启动时vite做了什么(源码、middlewares))
(四)什么是Vite——冷启动时vite做了什么(源码、middlewares)
vite分享ppt,感兴趣的可以下载:
Vite分享、原理介绍ppt 什么是vite系列目录:
(一)什么是Vite——vite介绍与使用-CSDN博客
(二)什么是Vite——Vite 和 Webpack 区别࿰…
-------连载(32))
Java面试题(每天10题)-------连载(32)
目录
设计模式篇
1、工厂方法模式(利用创建同一接口的不同实例):
2、抽象工厂模式(多个工厂)
3、单例模式(保证对象只有一个实例)
4、原型模式(对一个原型进行复制、克隆产生类…

芯科科技推出新的8位MCU系列产品,扩展其强大的MCU平台
新的BB5系列为简单应用提供更多开发选择
中国,北京 - 2023年11月14日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ:SLAB),今日宣布…

DataCamp在线学习平台
DataCamp(https://www.datacamp.com/blog)是一个在线学习平台,专注于数据科学和分析领域的教育。该平台提供丰富的课程,涵盖了从数据处理到机器学习和深度学习的各个方面。以下是DataCamp的主要特点:
互动学习&#x…

Redis配置、Redis类型
系列文章目录
第一章 Java线程池技术应用 第二章 CountDownLatch和Semaphone的应用 第三章 Spring Cloud 简介 第四章 Spring Cloud Netflix 之 Eureka 第五章 Spring Cloud Netflix 之 Ribbon 第六章 Spring Cloud 之 OpenFeign 第七章 Spring Cloud 之 GateWay 第八章 Sprin…

代码随想录算法训练营第五十五天丨 动态规划part16
583. 两个字符串的删除操作
思路
#动态规划一
本题和动态规划:115.不同的子序列 (opens new window)相比,其实就是两个字符串都可以删除了,情况虽说复杂一些,但整体思路是不变的。
这次是两个字符串可以相互删了,这…

智慧工地AI视频管理平台源码
智慧工地是指以物联网、移动互联网技术为基础,充分应用人工智能等信息技术,通过AI赋能建筑行业,对住建项目内人员、车辆、安全、设备、材料等进行智能化管理,实现工地现场生产作业协调、智能处理和科学管理。智慧工地的核心是以一…

利用EXCEL中的VBA对同一文件夹下的多个数据文件进行特定提取
Sub CopyFilesBasedOnCriteria()Dim fso As ObjectDim sourceFolder As StringDim destinationFolder As String 设置源文件夹路径和目标文件夹路径sourceFolder "C:\\test\\全波段模拟_Nimbostratus cloud - 副本"destinationFolder "C:\\Desktop\\MOD02数据…

RabbitMQ之死信队列
文章目录 一、死信的概念二、死信的来源三、实战1、消息 TTL 过期2、队列达到最大长度3、消息被拒 总结 一、死信的概念
先从概念解释上搞清楚这个定义,死信,顾名思义就是无法被消费的消息,字面意思可以这样理解,一般来说&#x…
---好理解)
工作记录-------java文件的JVM之旅(学习篇)---好理解
一个java文件,如何实现功能呢?需要去JVM这个地方。
java文件高高兴兴的来到JVM,想要开始JVM之旅,它确说:“现在的我还不能进去,需要做一次转换,生成class文件才行”。为什么这样呢?…

AI智能机器人有什么特点,ai外呼系统的作用
人工智能机器人早已活动在人们的日常生活和工作中,它们有些是虚拟的,有些是有实体的,当然可不是类似于变形金刚中机器人的样子。而研究人工智能技术的侧重点不同,所研究出的产品也各有不同。
电销机器人就是人工智能众多副产物的…
File的导出)
MATLAB中Filter Designer的使用以及XILINX Coefficient(.coe)File的导出
文章目录 Filter Designer的打开滤波器参数设置生成matlab代码生成XILINX Coefficient(.COE) File实际浮点数的导出官方使用教程 Filter Designer的打开
打开Filter Designer:
方法一:命令行中输入Filter Designer,再回车打开。 方法二&…
)
@Version乐观锁配置mybatis-plus使用(version)
1:首先在实体类的属性注解上使用Version
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import com.baomidou.mybatisplus.annotation.Versio…
)
Google codelab WebGPU入门教程源码<5> - 使用Storage类型对象给着色器传数据(源码)
对应的教程文章:
https://codelabs.developers.google.com/your-first-webgpu-app?hlzh-cn#5
对应的源码执行效果: 对应的教程源码:
此处源码和教程本身提供的部分代码可能存在一点差异。运行的时候,点击画面可以切换效果。
class Color4 {r: number;g: numb…

WPF xmal中的Color的常用写法
在WPF的XAML中,Color的表示方法有多种,以下是一些常见的表示方法:
预定义颜色名称:使用预定义的颜色名称。XAML支持所有Web颜色的名称。例如,Red、Blue、Green等。
<Window Background"Red">
</W…