1、启动Flink SQL
首先启动Flink的集群,选择独立集群模式或者是session的模式。此处选择是时session的模式:yarn-session.sh -d 在启动Flink SQL的client:
sql-client.sh2、kafka SQL 连接器
在使用kafka作为数据源的时候需要上传jar包到flnik的lib下:/usr/local/soft/flink-1.15.2/lib可以去官网找对应的版本下载上传。
1、创建表:再流上定义表
再flink中创建表相当于创建一个视图(视图中不存数据,只有查询视图时才会去原表中读取数据)CREATE TABLE students (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'student','properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'csv'
)2、查询数据(连续查询):select clazz,count(1) as c from students group by clazz;3、客户端为维护和可视化结果提供了三种的模式:
1、表格模式(默认使用的模式),(table mode),在内存中实体化结果,并将结果用规则的分页表格可视化展示出来
SET 'sql-client.execution.result-mode' = 'table';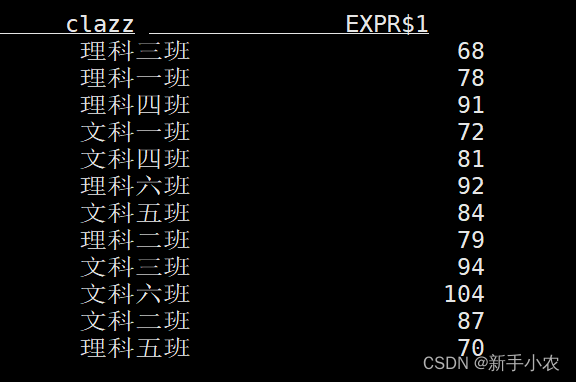
2、变更日志模式,(changelog mode),不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET 'sql-client.execution.result-mode' = 'changelog';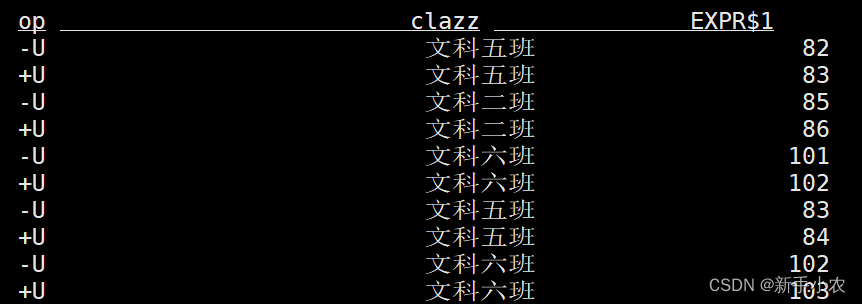
3、Tableau模式(tableau mode)更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';
4、 Flink SQL流批一体:
1、流处理:
a、流处理即可以处理有界流也可以处理无界流
b、流处理的输出的结果是连续的结果
c、流处理的底层是持续流的模型,上游的Task和下游的Task同时启动等待数据的到达
SET 'execution.runtime-mode' = 'streaming'; 2、批处理:
a、批处理只能用于处理有界流
b、输出的是最终的结果
c、批处理的底层是MapReduce模型,会先执行上游的Task,在执行下游的Task
SET 'execution.runtime-mode' = 'batch';Flink做批处理,读取一个文件:-- 创建一个有界流的表
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/spark/stu/students.txt', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);select clazz,count(1) as c from
students_hdfs
group by clazz5、Flink SQL的连接器:
1、kafka SQL 连接器
对于一些参数需要从官网进行了解。
1、kafka source
-- 创建kafka 表
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);2、kafka sink
-- 创建kafka 表
CREATE TABLE students_kafka_sink (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students_sink', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 将查询结果保存到kafka中
insert into students_kafka_sink
select * from students_hdfs;kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic students_sink3、将更新的流写入到kafka中
因为在Kafka是一个消息队列,是不会去重的。所以只需要将读取数据的格式改成canal-json。当数据被读取回来还是原来的流模式。
CREATE TABLE clazz_num_kafka (clazz STRING,num BIGINT
) WITH ('connector' = 'kafka','topic' = 'clazz_num', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'canal-json' -- 读取数据的格式
);-- 将更新的数据写入kafka需要使用canal-json格式,数据中会带上操作类型
{"data":[{"clazz":"文科一班","num":71}],"type":"INSERT"}
{"data":[{"clazz":"理科三班","num":67}],"type":"DELETE"}insert into clazz_num_kafka
select clazz,count(1) as num from
students
group by clazz;kafka-console-consumer.sh --bootstrap-server master:9092,node1:9092,node2:9092 --from-beginning --topic clazz_num2、 hdfs SQL 连接器
1、hdfs source
Flink读取文件可以使用有界流的方式,也可以是无界流方式。
-- 有界流
CREATE TABLE students_hdfs_batch (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);select * from students_hdfs_batch;-- 无界流
-- 基于hdfs做流处理,读取数据是以文件为单位,延迟比kafka大
CREATE TABLE students_hdfs_stream (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' , -- 必选:文件系统连接器指定 format'source.monitor-interval' = '5000' -- 每隔一段时间扫描目录,生成一个无界流
);select * from students_hdfs_stream;2、hdfs sink
-- 1、批处理模式(使用方式和底层原理和hive类似)
SET 'execution.runtime-mode' = 'batch';-- 创建表
CREATE TABLE clazz_num_hdfs (clazz STRING,num BIGINT
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/clazz_num', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);
-- 将查询结果保存到表中
insert into clazz_num_hdfs
select clazz,count(1) as num
from students_hdfs_batch
group by clazz;-- 2、流处理模式
SET 'execution.runtime-mode' = 'streaming'; -- 创建表,如果查询数据返回的十更新更改的流需要使用canal-json格式
CREATE TABLE clazz_num_hdfs_canal_json (clazz STRING,num BIGINT
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/clazz_num_canal_json', -- 必选:指定路径'format' = 'canal-json' -- 必选:文件系统连接器指定 format
);insert into clazz_num_hdfs_canal_json
select clazz,count(1) as num
from students_hdfs_stream
group by clazz;3、MySQL SQL 连接器
1、整合:
# 1、上传依赖包到flink 的lib目录下/usr/local/soft/flink-1.15.2/lib
flink-connector-jdbc-1.15.2.jar
mysql-connector-java-5.1.49.jar# 2、需要重启flink集群
yarn application -kill [appid]
yarn-session.sh -d# 3、重新进入sql命令行
sql-client.sh![]()
![]() 2、mysql source
2、mysql source
-- 有界流
-- flink中表的字段类型和字段名需要和mysql保持一致
CREATE TABLE students_jdbc (id BIGINT,name STRING,age BIGINT,gender STRING,clazz STRING,PRIMARY KEY (id) NOT ENFORCED -- 主键
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/student','table-name' = 'students','username' ='root','password' ='123456'
);select * from students_jdbc;3、mysql sink
-- 创建kafka 表
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'earliest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 创建mysql sink表
CREATE TABLE clazz_num_mysql (clazz STRING,num BIGINT,PRIMARY KEY (clazz) NOT ENFORCED -- 主键
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://master:3306/student','table-name' = 'clazz_num','username' ='root','password' ='123456'
);--- 再mysql创建接收表
CREATE TABLE clazz_num (clazz varchar(10),num BIGINT,PRIMARY KEY (clazz) -- 主键
) ;-- 将sql查询结果实时写入mysql
-- 将更新更改的流写入mysql,flink会自动按照主键更新数据
insert into clazz_num_mysql
select
clazz,
count(1) as num from
students_kafka
group by clazz;kafka-console-producer.sh --broker-list master:9092,node1:9092,node2:9092 --topic students 插入一条数据4、DataGen:用于生成随机数据,一般用在高性能测试上
-- 创建包(只能用于source表)
CREATE TABLE students_datagen (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'datagen','rows-per-second'='5', -- 每秒随机生成的数据量'fields.age.min'='1','fields.age.max'='100','fields.sid.length'='10','fields.name.length'='2','fields.sex.length'='1','fields.clazz.length'='4'
);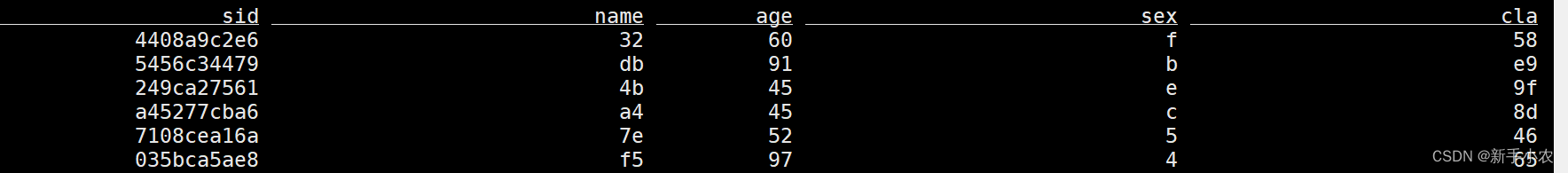
5、print:用于高性能测试 只能用于sink表
CREATE TABLE print_table (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'print'
);insert into print_table
select * from students_datagen;结果需要在提交的任务中查看。6、BlackHole :是用于高性能测试使用,在后面可以用于Flink的反压的测试。
CREATE TABLE blackhole_table (sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'blackhole'
);insert into blackhole_table
select * from students_datagen;6、SQL 语法
1、Hints:
用于提示执行,在Flink中可以动态的修改表中的属性,在Spark中可以用于广播。在修改动态表中属性后,不需要在重新建表,就可以读取修改后的需求。
CREATE TABLE students_kafka (`offset` BIGINT METADATA VIRTUAL, -- 偏移量`event_time` TIMESTAMP(3) METADATA FROM 'timestamp', --数据进入kafka的时间,可以当作事件时间使用sid STRING,name STRING,age INT,sex STRING,clazz STRING
) WITH ('connector' = 'kafka','topic' = 'students', -- 数据的topic'properties.bootstrap.servers' = 'master:9092,node1:9092,node2:9092', -- broker 列表'properties.group.id' = 'testGroup', -- 消费者组'scan.startup.mode' = 'latest-offset', -- 读取数据的位置earliest-offset latest-offset'format' = 'csv' -- 读取数据的格式
);-- 动态修改表属性,可以在查询数据时修改读取kafka数据的位置,不需要重新创建表
select * from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */;-- 有界流
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);-- 可以在查询hdfs时,不需要再重新的创建表就可以动态改成无界流
select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */;2、WITH:
当一段SQL语句在被多次使用的时候,就将通过with给这个SQL起一个别名,类似于封装起来,就是为这个SQL创建一个临时的视图(并不是真正的视图),方便下次使用。
CREATE TABLE students_hdfs (sid STRING,name STRING,age INT,sex STRING,clazz STRING
)WITH ('connector' = 'filesystem', -- 必选:指定连接器类型'path' = 'hdfs://master:9000/data/student', -- 必选:指定路径'format' = 'csv' -- 必选:文件系统连接器指定 format
);-- 可以在查询hdfs时,不需要再重新的创建表就可以动态改成无界流
select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */;-- tmp别名代表的时子查询的sql,可以在后面的sql中多次使用
with tmp as (select * from students_hdfs /*+ OPTIONS('source.monitor-interval' = '5000' ) */where clazz='文科一班'
)
select * from tmp
union all
select * from tmp;3、DISTINCT:
在flink 的流处理中,使用distinct,flink需要将之前的数据保存在状态中,如果数据一直增加,状态会越来越大 状态越来越大,checkpoint时间会增加,最终会导致flink任务出问题
select
count(distinct sid)
from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */;select count(sid)
from (select distinct *from students_kafka /*+ OPTIONS('scan.startup.mode' = 'earliest-offset') */
);注意事项:
1、 当Flink Client客户端退出来以后,里面创建的动态表就不存在了。这些表结构是元数据,是存储在内存中的。
2、当在进行where过滤的时候,字符串会出现三种情况:空的字符串、空格字符串、null的字符串,三者是有区别的:
这三者是不同的概念,在进行where过滤的时候过滤的条件是不同的。
1、过滤空的字符串:where s!= ‘空字符串’2、过滤空格字符串:where s!= ‘空格’3、过滤null字符串:where s!= nullFlink SQL中常见的函数:from_unixtime: 以字符串格式 string 返回数字参数 numberic 的表示形式(默认为 ‘yyyy-MM-dd HH:mm:ss’to_timestamp: 将格式为 string2(默认为:‘yyyy-MM-dd HH:mm:ss’)的字符串 string1 转换为 timestamp 安装 libssl1.1)



】C/C++内存管理详解)




)
![[Android]修改应用包名、名称、版本号、Icon以及环境判断和打包](http://pic.xiahunao.cn/[Android]修改应用包名、名称、版本号、Icon以及环境判断和打包)








