
image.png
ChatGPT用它自己的方式来理解世界,类似的技术是否也能用来学习动物的语言?
所罗门能够与动物交流并不是因为他拥有魔法物品,而是因为他有观察的天赋。 ——康拉德・劳伦兹《所罗门王的指环》
在《狮子王》、《疯狂动物城》等以动物为中心的作品中,作者经常会将角色拟人化,用人类的思考和交流方式来推进剧情。
不过,这类作品也会导致认知失调,当我们与动物进行交流时,可能会把自己的想法和偏见投射到动物身上,例如「羊羔跪乳」与感恩、孝道无关,而是因为羊特殊的胃部构造,但人类会把自身投射到羊羔的行为上。

图片
传统的动物认知工作主要是建立一个词汇表,但比如「水」、「喝」、「干燥」等概念在水生生物的世界中可能不存在或没有意义,在动物交流中也就不存在和人类概念之间的对应;并且动物之间的交流也并不一定通过发声,还包括手势、动作序列或皮肤纹理的变化等。
从理论上讲,机器学习模型要比人类要更擅长总结出词汇之间松散的相关性,神经网络的输入不对输入数据的性质做任何假设,只要某种模式频繁出现,就有可能发现动物交流中蕴含的信息。
由纽约城市大学、、UC伯克利、MIT、哈佛、谷歌研究院和《国家地理》等研究机构发起的鲸语翻译计划(Cetacean Translation Initiative, CETI),使用自然语言处理系统分析海量抹香鲸数据,并计划未来与野外抹香鲸直接对话。
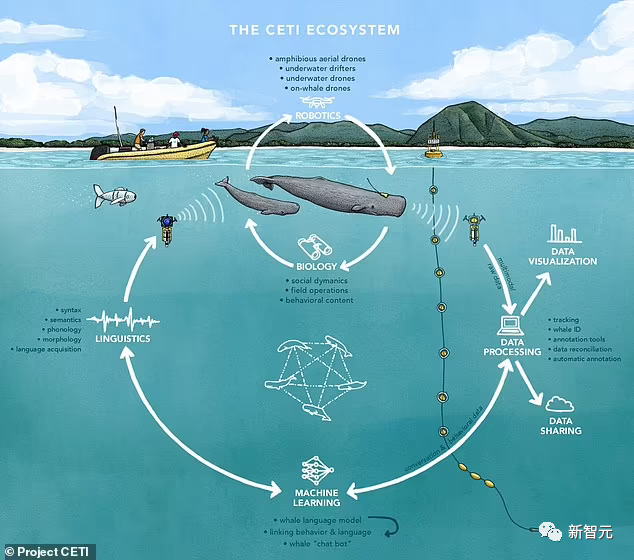
图片
Aza Raskin等人联合创立的地球物种项目(Earth Species Project,ESP)开源了首个动物发声基准BEANS,可以测量机器学习算法在生物声学数据上的性能;还开发了首个用于动物发声的基础模型AVES,可用于如信号检测和分类等各种任务。
随着生成式AI技术的进步,或许某天我们真有可能揭开动物交流背后的真正含义。
复杂的动物王国
1974年,哲学家托马斯·内格尔发表了一篇开创性的论文,名为《当蝙蝠是什么感觉?》(What Is It Like to Be a Bat?”),他认为,蝙蝠的生活与人类的生活有着非常大的差异,以至于人类可能永远无法真正知道这个问题的答案。
我们对世界的理解是由人类的概念塑造的,想要知道蝙蝠是什么样子的唯一方法就是成为蝙蝠,并拥有蝙蝠的概念。
不过,我们还是可以推测出蝙蝠的部分思维方式,比如蝙蝠生活在高处,可能上下的概念是颠倒的,通过回声定位等,但我们无法拥有蝙蝠的生活体验。
如果狮子会说话,我们也无法理解它,因为人类的大脑无法共情狮子语言中所传达的感受和概念。——Ludwig Wittgenstein

图片
但并非所有动物的思维都与人类迥然不同,从心理上讲,人类与其他灵长类动物的共同点比章鱼和鱿鱼更多:人类与黑猩猩的最后一个共同祖先生活在600万到800万年前,而与章鱼的最后一个共同祖先生活在大约6亿年前的前寒武纪海洋中。
经过教导后,黑猩猩可以学会人类的手语,甚至能够理解复杂的人类指令,并使用键盘符号进行交流,但也正如开头所说的,我们可能也过度拟人化地理解了猩猩的行为。
对于与人类关系更远的物种,理解他们的交流方式则变得更困难,例如蜜蜂和一些鸟类可以看到可见光谱中的紫外线,蝙蝠、海豚、狗和猫能听到超声波等,每个物种都有其独特性。
用AI理解动物
地球物种项目(Earth Species Project)的计算机科学家Britt Selvitelle表示,他们正在努力破译第一种非人类语言,并且有可能在五到十年内实现。
在动物语言领域,虽然研究人员数十年来已经积累了大量知识,但世界上还并不存在一块能够翻译人类语言和动物语言的「罗塞塔石碑」,也就不存在「动物语言」的标注金标准。
从根本上说,人工智能是一种数据驱动的工具,预训练语言模型可以通过海量数据,以无监督的形式学习到数据的内部表征。
从ChatGPT强大的表现来看,生成式AI技术可能有自己独特的内部表征方法,而非套用人类的概念,所以研究人员开始转向AI技术来分析数据,获取对动物有意义的术语。

图片
在地球物种项目中,收集的数据形式包括声音、运动和视频,涵盖野外或圈养环境中的动物,数据中还附有生物学家对动物当时在做什么和在什么背景下做什么的注释。
随着物联网的成熟,将廉价可靠的记录设备(如麦克风或生物记录仪)放在野外动物身上也越来越容易,可以提供大量数据供人工智能工具进行组织和分析,以帮助发现数据背后的意义,然后使用生成式方法进行测试,最终实现重新创建动物的声音,进行双向交流。
动物声音基准BEANS
在生物声学领域,基于机器学习技术的成功应用需要在特定任务上精心策划出一组高质量数据,但在此之前还不存在一个涵盖多任务、多物种的公共基准,无法以受控和标准化的方式测量机器学习技术的性能并将新提出的技术与现有技术进行基准测试。

image.png
论文链接:https://arxiv.org/pdf/2210.12300.pdf
数据链接:GitHub - earthspecies/beans: BEANS: The Benchmark of Animal Sounds
BEANS((the BEnchmark of ANimal Sounds,动物声音的基准)是一个生物声学任务和公共数据集的集合,专门用于测量生物声学领域机器学习算法的性能,包括生物声学中的两个常见任务:分类和检测。
BEANS中包括12个数据集,涵盖多个物种,包括鸟类、陆地和海洋哺乳动物、无尾两栖动物和昆虫。
除了数据集,文中还提出了一组标准机器学习方法的性能作为任务性能的基线。
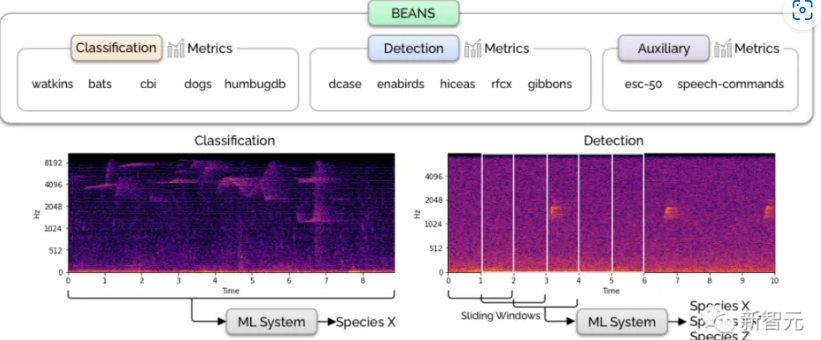
image.png
基准和基线代码都已开源公开,研究人员希望BEANS可以为基于机器学习的生物声学研究建立一个新的标准数据集。
动物发声大模型AVES
在生物声学领域,由于缺乏标注好的训练数据,极大阻碍了该领域以有监督方式训练的大规模神经网络模型的使用。
为了利用大量未标注的音频数据,研究人员提出了AVES(Animal Vocalization Encoder based on Self-Supervision,基于自我监督的动物发声编码器),一种自监督的、基于Transformer模型的音频表征模型,可用于编码动物发声。
论文链接:https://arxiv.org/pdf/2210.14493.pdf
模型链接:GitHub - earthspecies/aves: AVES: Animal Vocalization Encoder based on Self-Supervision
研究人员在一组不同的无标注音频数据集上对AVES模型进行预训练,并针对下游生物声学任务对模型进行微调。
分类和检测任务的综合实验表明,AVES优于所有强基线,甚至优于在带注释的音频分类数据集上训练的有监督topline模型。
实验结果还表明,精心设计出一个与下游任务相关的小训练子集是训练高质量音频表示模型的有效方法。
伦理问题
1970年代,当西方社会第一次发现鲸鱼的歌声后,人类社会暂停了对深海鲸鱼的捕杀,并促成了环境保护局(Environmental Protection Agency)的成立。

image.png
随着地球物种项目技术路线图的推进,我们可以更了解周围的生物,进行更多的数据收集,开发新的基准和基础模型,从而可以更好地保护这颗蓝色星球。
Raskin认为,在未来12-36个月内,团队就可以实现与动物交流,比如做出一个人造鲸鱼或乌鸦,能以一种无法分辨的方式与鲸鱼或乌鸦交谈,不过关键点在于,我们也需要理解模型在说什么,才能进一步对话。
Raskin团队也在讨论如何负责任地使用这些人工智能方法,目前已经规定在任何测试中都要准备好这些方法,技术路线中指出了潜在的风险,如干扰狩猎和觅食或交配,也可能发送错误给动物。
人类是在10万到30万年前才学会如何用声音说话和交流的,而鲸鱼和海豚用声音来传承文化和歌曲已经有3400万年历史了。
如果随意在鲸群中发送AI音频,可能会对3400万年的文化造成破坏。
这就是为什么到目前为止,地球物种项目中的大部分工作都是在收集数据和创建基础,即推动未来进步的基准和基础模型,与世界各地的公司和组织每天利用人工智能和机器学习所做的事情没有什么不同,只是规模更宏大。
如果人工智能可以帮助我们理解动物在说什么,那么我们使用人工智能的能力的限制是什么?
如果人工智能可以帮助我们了解动物,那么它会教我们关于人类的什么?

image.png
Raskin 和Zacarian希望动物语言的最终翻译成为世界历史上的转折点之一,就像鲸鱼的歌声首次被发现或1990年蓝点(A Pale Blue Dot)的照片一样,这些时刻改变了我们对世界的看法和理解。
参考资料:
https://cloud.google.com/blog/transform/can-generative-ai-help-humans-understand-animals-earth-species-project-conservation
更多AI资讯请查阅365文档


 mysql8.0.31 源码安装)


:UART开发实践)
)
(表的增删查改))
)










