模型评估主要分为离线评估和在线评估两个阶段。 针对分类、 排序、 回归、序列预测等不同类型的机器学习问题, 评估指标的选择也有所不同。
1 评估指标
1.1准确率
准确率是指分类正确的样本占总样本个数的比例

但是准确率存在明显的问题,比如当负样本占99%时, 分类器把所有样本都预测为负样本也可以获得99%的准确率。 所以, 当不同类别的样本比例非常不均衡时, 占比大的类别往往成为影响准确率的最主要因素。
为了解决这个问题, 可以使用更为有效的平均准确率(每个类别下的样本准确率的算术平均) 作为模型评估的指标。
1.2 精确率和召回率
精确率是指分类正确的正样本个数占分类器判定为正样本的样本个数的比例。 召回率是指分类正确的正样本个数占真正的正样本个数的比例。
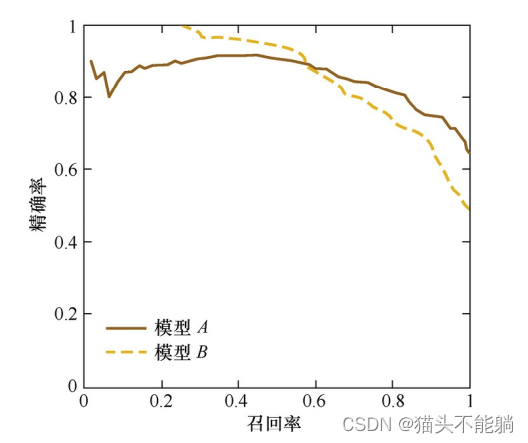
P-R曲线的横轴是召回率, 纵轴是精确率。 对于一个排序模型来说, 其P-R曲
线上的一个点代表着, 在某一阈值下, 模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本, 此时返回结果对应的召回率和精确率。 整条P-R曲线是通过将阈值从高到低移动而生成的。
1.3 F1 score
F1score是精准率和召回率的调和平均值, 它定义为:

1.4 RMSE
RMSE经常被用来衡量回归模型的好坏:

一般情况下, RMSE能够很好地反映回归模型预测值与真实值的偏离程度。 但
在实际问题中, 如果存在个别偏离程度非常大的离群点( Outlier) 时, 即使离群点数量非常少, 也会让RMSE指标变得很差.
解决方案:
(1)认定这些离群点是“噪声点”的话, 就需要在数据预处理的阶段把这些噪声点过滤掉。
(2)不认为这些离群点是“噪声点”的话, 就需要进一步提高模型的预测能力, 将离群点产生的机制建模进去。
(3)找一个更合适的指标来评估该模型。 关于评估指标, 其实是存在比RMSE的鲁棒性更好的指标, 比如平均绝对百分比误差MAPE:
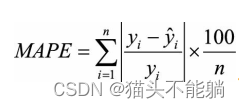
相比RMSE, MAPE相当于把每个点的误差进行了归一化, 降低了个别离群点带来的绝对误差的影响。
1.6 ROC曲线和AUC值
二值分类器(Binary Classifier) 是机器学习领域中最常见也是应用最广泛的分
类器。 评价二值分类器的指标很多, 比如precision、 recall、 F1 score、 P-R曲线等。 ROC曲线则有很多优点, 经常作为评估二值分类器最重要的指标之一。
ROC曲线的横坐标为假阳性率(False Positive Rate, FPR) ; 纵坐标为真阳性率(True Positive Rate, TPR) 。 FPR和TPR的计算方法分别为:

P是真实的正样本的数量, N是真实的负样本的数量, TP是P个正样本中被分类器预测为正样本的个数, FP是N个负样本中被分类器预测为正样本的个数。
在二值分类问题中, 模型的输出一般都是预测样本为正例的概率。
AUC指的是ROC曲线下的面积大小, 该值能够量化地反映基于ROC曲线衡量出的模型性能。AUC越大, 说明分类器越可能把真正的正样本排在前面, 分类性能越好。
相比P-R曲线, ROC曲线有一个特点, 当正负样本的分布发生变化时, ROC曲线的形状能够基本保持不变, 而P-R曲线的形状一般会发生较剧烈的变化。这个特点让ROC曲线能够尽量降低不同测试集带来的干扰, 更加客观地衡量模型本身的性能。
2 余弦距离
如何评估样本距离也是定义优化目标和训练方法的基础。
在机器学习问题中, 通常将特征表示为向量的形式, 所以在分析两个特征向量之间的相似性时, 常使用余弦相似度来表示。 余弦相似度的取值范围是[−1,1]。
2.1 余弦相似度
关注的是向量之间的角度关系, 并不关心它们的绝对大小:

2.2 余弦距离
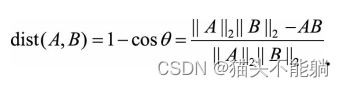
3 模型评估的方法
通常把样本分为训练集和测试集, 训练集用于训练模型, 测试集用于评估模型。 在样本划分和模型验证的过程中, 存在着不同的抽样方法和验证方法。
3.1 Holdout检验
Holdout 检验是最简单也是最直接的验证方法, 它将原始的样本集合随机划分成训练集和验证集两部分。
3.2 交叉验证
k-fold交叉验证: 首先将全部样本划分成k个大小相等的样本子集; 依次遍历这k个子集, 每次把当前子集作为验证集, 其余所有子集作为训练集, 进行模型的训练和评估; 最后把k次评估指标的平均值作为最终的评估指标。 在实际实验中, k经常取10。
留一验证: 每次留下1个样本作为验证集, 其余所有样本作为测试集。 样本总58数为n, 依次对n个样本进行遍历, 进行n次验证, 再将评估指标求平均值得到最终的评估指标。 在样本总数较多的情况下, 留一验证法的时间开销极大。
3.3自助法
当样本规模比较小时, 将样本集进行划分会让训练集进一步减小, 这可能会影响模型训练效果。 有没有能维持训练集样本规模的验证方法呢?
自助法是基于自助采样法的检验方法。 对于总数为n的样本集合, 进行n次有放回的随机抽样, 得到大小为n的训练集。 n次采样过程中,有的样本会被重复采样, 有的样本没有被抽出过, 将这些没有被抽出的样本作为验证集, 进行模型验证, 这就是自助法的验证过程。
4 超参数调优
需要明确超参数搜索算法一般包括哪几个要素。 一是目标函数, 即算法需要最大化/最小化的目标; 二是搜索范围, 一般通过上限和下限来确定; 三是算法的其他参数, 如搜索步长。
4.1 网格搜索
过查找搜索范围内的所有的点来确定最优值。
在实际应用中, 网格搜索法一般会先使用较广的搜索范围和较大的步长, 来寻找全局最优值可能的位置; 然后会逐渐缩小搜索范围和步长, 来寻找更精确的最优值。
4.2 随机搜索
随机搜索的思想与网格搜索比较相似, 只是不再测试上界和下界之间的所有值, 而是在搜索范围中随机选取样本点。 它的理论依据是, 如果样本点集足够大, 那么通过随机采样也能大概率地找到全局最优值, 或其近似值。
4.3 贝叶斯优化
网格搜索和随机搜索在测试一个新点时, 会忽略前一个点的信息;而贝叶斯优化算法则充分利用了之前的信息。
首先根据先验分布, 假设一个搜集函数; 然后, 每一次使用新的采样点来测试目标函数时, 利用这个信息来更新目标函数的先验分布; 最后, 算法测试由后验分布给出的全局最值最可能出现的位置的点。
5 过拟合和欠拟合
过拟合是指模型对于训练数据拟合呈过当的情况, 反映到评估指标上, 就是模型在训练集上的表现很好, 但在测试集和新数据上的表现较差。 欠拟合指的是模型在训练和预测时表现都不好的情况。

5.1 解决过拟合的方法
(1) 从数据入手, 获得更多的训练数据。比如, 在图像分类的问题上, 可以通过图像的平移、 旋转、缩放等方式扩充数据; 更进一步地, 可以使用生成式对抗网络来合成大量的新训练数据。
(2) 降低模型复杂度。例如, 在神经网络模型中减少网络层数、 神经元个数等; 在决策树模型中降低树的深度、 进行剪枝等。
(3) 正则化方法。 给模型的参数加上一定的正则约束, 比如将权值的大小加入到损失函数中。
(4) 集成学习方法。 集成学习是把多个模型集成在一起, 来降低单一模型的过拟合风险, 如Bagging方法。
5.2 解决欠拟合的方法
(1) 添加新特征。 当特征不足或者现有特征与样本标签的相关性不强时, 模型容易出现欠拟合。 如因子分解机、 梯度提升决策树、Deep-crossing等都可以成为丰富特征的方法。
(2) 增加模型复杂度。 简单模型的学习能力较差, 通过增加模型的复杂度可以使模型拥有更强的拟合能力。 在线性模型中添加高次项, 在神经网络模型中增加网络层数或神经元个数等。
(3) 减小正则化系数。 正则化是用来防止过拟合的, 但当模型出现欠拟合现象时, 则需要有针对性地减小正则化系数。















发布(附黑白苹果镜像地址))



)