一 准备工作
下面是构建这个应用程序时将使用的软件工具:
1.Llama-cpp-python
下载llama-cpp, llama-cpp-python
[NLP] Llama2模型运行在Mac机器-CSDN博客
2、LangChain
LangChain是一个提供了一组广泛的集成和数据连接器,允许我们链接和编排不同的模块。可以常见聊天机器人、数据分析和文档问答等应用。
3、sentence-transformer
sentence-transformer提供了简单的方法来计算句子、文本和图像的嵌入。它能够计算100多种语言的嵌入。我们将在这个项目中使用开源的all-MiniLM-L6-v2模型。
4、FAISS
Facebook AI相似度搜索(FAISS)是一个为高效相似度搜索和密集向量聚类而设计的库。
给定一组嵌入,我们可以使用FAISS对它们进行索引,然后利用其强大的语义搜索算法在索引中搜索最相似的向量。
虽然它不是传统意义上的成熟的向量存储(如数据库管理系统),但它以一种优化的方式处理向量的存储,以实现有效的最近邻搜索。
二 LLM应用架构:以文档Q&A为例
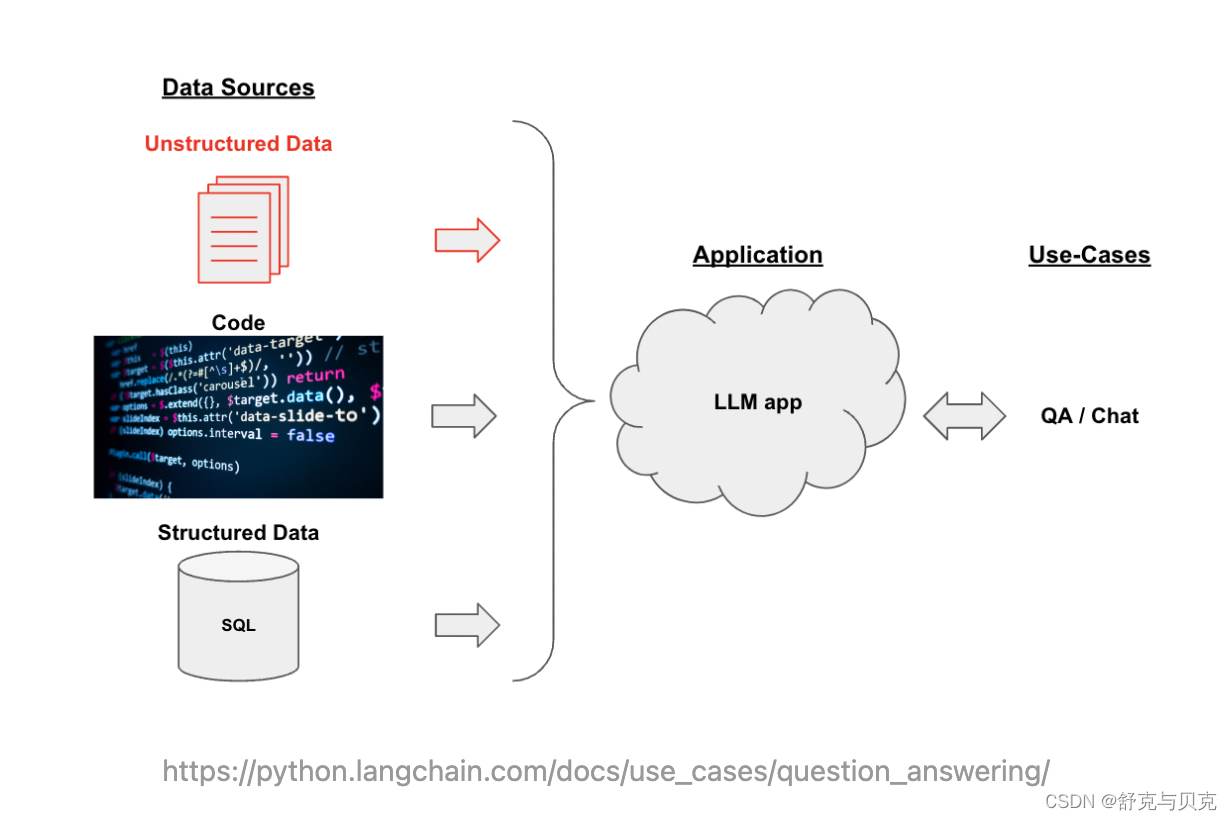
假设我们想基于自己部署的Llama2模型,构建一个用于回答针对特定文档内容提问的聊天机器人。文档的内容可能属于特定领域或者特定组织内的文档,因此不属于任何Llama2进行预训练和微调的数据集。一个直觉的做法是in-context-learning:将文档作为Prompt提供给模型,从而模型能够根据所提供的Context进行回答。直接将文档作为Context可能遇到的问题是:
- 文档的长度超出了模型的Context长度限制,原版Llama2的Context长度为4096个Tokens。
- 对于较长的Context,模型可能会Lost in the Middle,无法准确从Context中获取关键信息。
因此,我们希望在构建Prompt时,只输入与用户的问题最相关的文档内容。
以下是构建文档Q&A应用的常用架构:
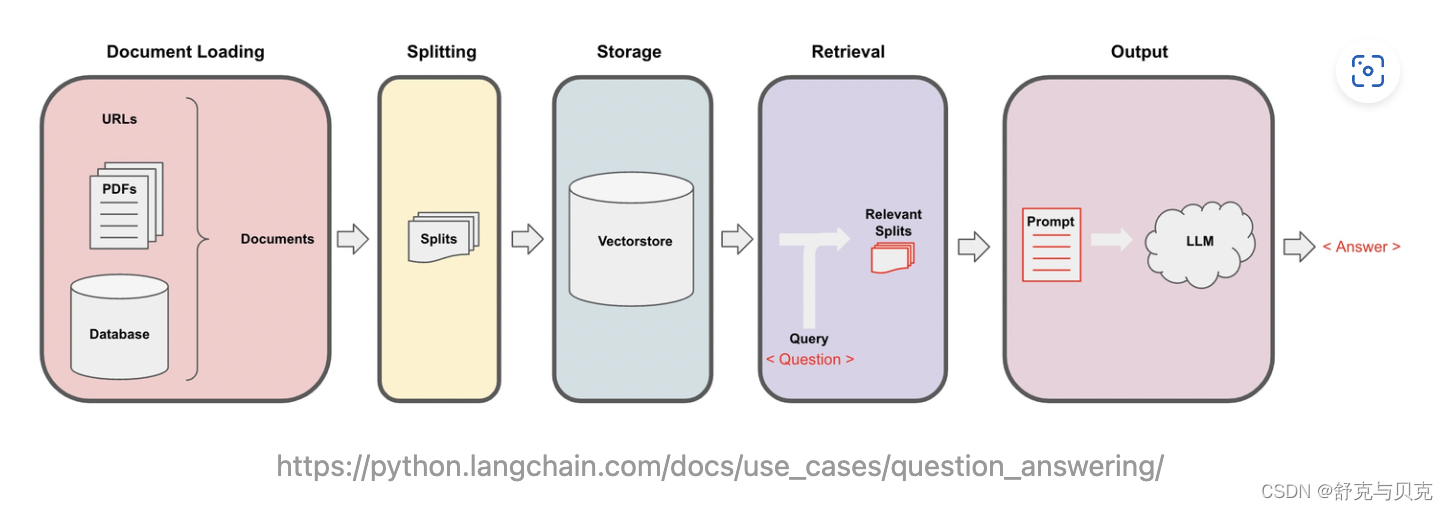
- 文档处理与存储:将原始文本进行分块 (Splitting),并使用语言模型对每块文本进行embedding,得到文本的向量表示,最后将文本向量存储在支持相似性搜索的向量数据库中。
- 用户询问和Prompt构建:根据用户输入的询问,使用相似性搜索在向量数据库中提取出与询问最相关的一些文档分块,并将用户询问+文档一起构建Prompt,随后输入LLM并得到回答。
三 实际使用
LangChain
在上节中描述了以文档Q&A为例的LLM应用Pipeline架构。LangChain是构建该类大模型应用的框架,其提供了模块化组件(例如上文图中的Document loader, Text splitter, Vector storage)的抽象和实现,并支持集成第三方的实现(例如可以使用不同第三方提供的Vector Storage服务)。通过LangChain可以将大模型与自定义的数据源结合起来构建Pipeline。
https://github.com/langchain-ai/langchaingithub.com/langchain-ai/langchain
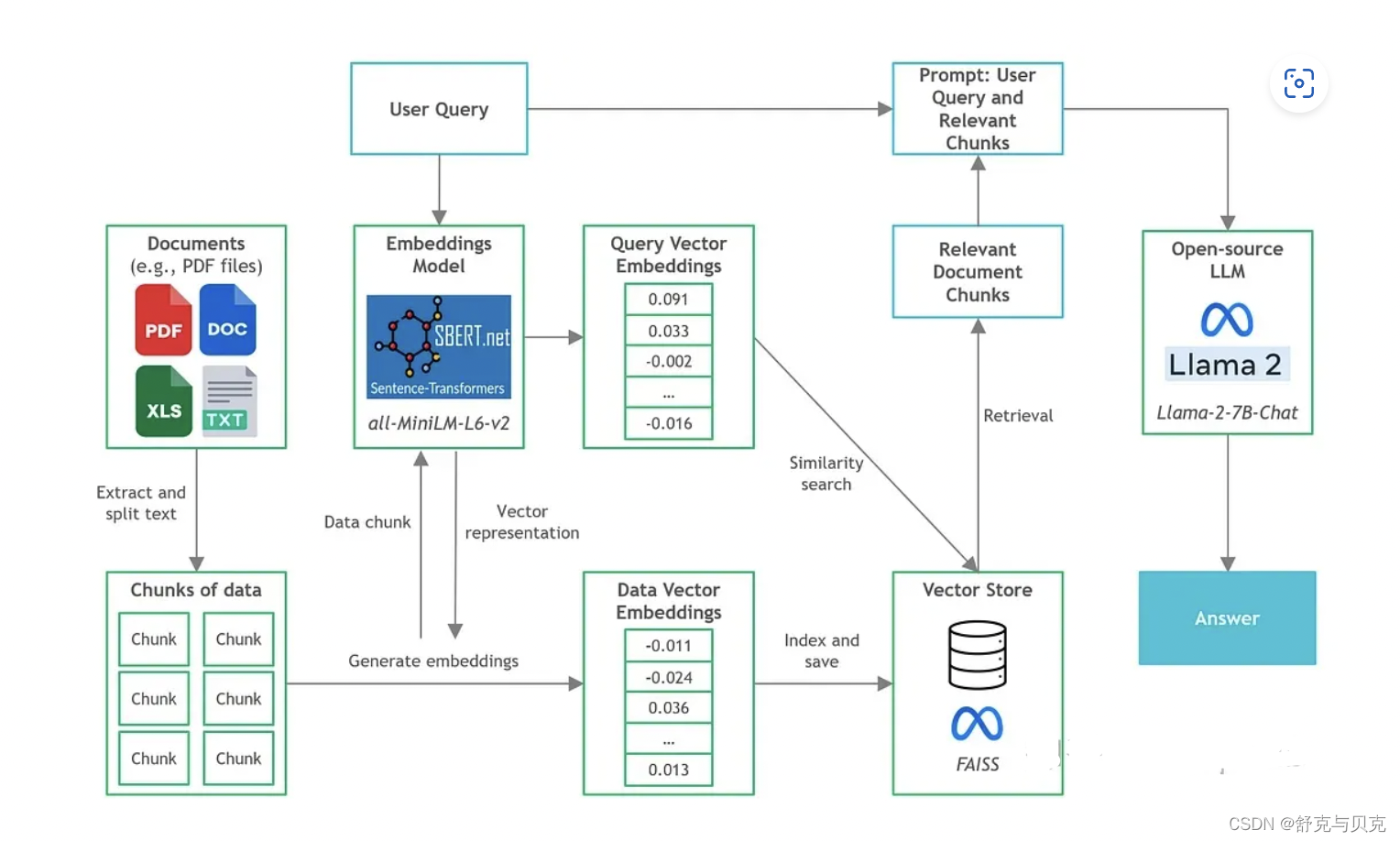
构建步骤
我们已经了解了各种组件,接下来让逐步介绍如何构建文档问答应用程序。
由于已经有许多教程了,所以我们不会深入到复杂和一般的文档问答组件的细节(例如,文本分块,矢量存储设置)。在本文中,我们将把重点放在开源LLM和CPU推理方面。
使用llama-cpp-python启动llama2 api服务
python3 -m llama_cpp.server --model TheBloke--Chinese-Alpaca-2-7B-GGUF/chinese-alpaca-2-7b.Q4_K_M.gguf --n_gpu_layers 1INFO: Started server process [63148]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)使用LangChain调用本地部署的Llama2
下面的示例将使用LangChain的API调用本地部署的Llama2模型。
from langchain.chat_models import ChatOpenAIchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)- 由于本地部署的llama-cpp-python提供了类OpenAI的API,因此可以直接使用
ChatOpenAI接口,这将调用/v1/chat/completionsAPI。 - 由于并没有使用真正的OpenAI API,因此
open_ai_key可以任意提供。openai_pi_base为模型API的Base URL。max_tokens限制了模型回答的长度。
from langchain.chat_models import ChatOpenAIchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)from langchain.schema import AIMessage, HumanMessage, SystemMessagesystem_text = "You are a helpful assistant."
human_text1 = "What is the capital of France?"
assistant_text = "Paris."
human_text2 = "How about England?"messages = [SystemMessage(content=system_text), HumanMessage(content=human_text1), AIMessage(content=assistant_text), HumanMessage(content=human_text2)]chat_model.predict_messages(messages)
这里将演示如何使用LangChain构建一个简单的文档Q&A应用Pipeline:
- Document Loading + Text Splitting
- Text Embeddings + Vector Storage
- Text Retrieval + Query LLM
1 数据加载与处理 Document Loading + Text Splitting
本实验使用llama.cpp的README.md作为我们需要进行询问的文档。LangChain提供了一系列不同格式文档的Loader,包括用于加载Markdown文档的UnstructuredMarkdownLoader:
UnstructuredMarkdownLoader默认会将文档中的不同Elements(各级标题,正文等)组合起来,去掉了#等字符。
RecursiveCharacterTextSplitter是对常见文本进行Split的推荐选择:
RecursiveCharacterTextSplitter递归地在文本中寻找能够进行分割的字符(默认为["\n\n", "\n", " ", ""])。这将尽可能地保留完整的段落,句子和单词。
chunk_size: 文本进行Split后每个分块的最大长度,所有分块将在这个限制以内chunk_overlap: 前后分块overlap的长度,overlap是为了保持前后两个分块之间的语义连续性length_function: 度量文本长度的方法
from langchain.document_loaders import UnstructuredMarkdownLoaderloader = UnstructuredMarkdownLoader("./README.md")
text = loader.load()from langchain.text_splitter import RecursiveCharacterTextSplittertext_splitter = RecursiveCharacterTextSplitter(chunk_size = 2000,chunk_overlap = 400,length_function = len,is_separator_regex = False
)
all_splits = text_splitter.split_documents(text)

2.矢量存储 Text Embeddings + Vector Storage
这一步的任务是:将文本分割成块,加载嵌入模型,然后通过FAISS 进行向量的存储
Vector Storage
这里以FAISS向量数据库作为示例, FAISS基于Facebook AI Similarity Search(Faiss)库 。
pip install faiss-cpufrom langchain.embeddings import HuggingFaceEmbeddings
# Load embeddings model
embeddings = HuggingFaceEmbeddings(model_name='sentence-transformers/all-MiniLM-L6-v2', model_kwargs={'device': 'cpu'}) from langchain.vectorstores import FAISS
vectorstore = FAISS.from_documents(all_splits, embeddings)
vectorstore.save_local('vectorstore/db_faiss')#question = "How to run the program in interactive mode?"
#docs = vectorstore.similarity_search(question, k=1)

运行上面的Python脚本后,向量存储将被生成并保存在名为'vectorstore/db_faiss'的本地目录中,并为语义搜索和检索做好准备。
3.文本检索与LLM查询 Text Retrieval + Query LLM
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQAchat_model = ChatOpenAI(openai_api_key = "EMPTY", openai_api_base = "http://localhost:8000/v1", max_tokens=256)qa_chain = RetrievalQA.from_chain_type(chat_model, retriever=vectorstore.as_retriever(search_kwargs={"k": 1}))
qa_chain({"query": "How to run the program in interactive mode?"})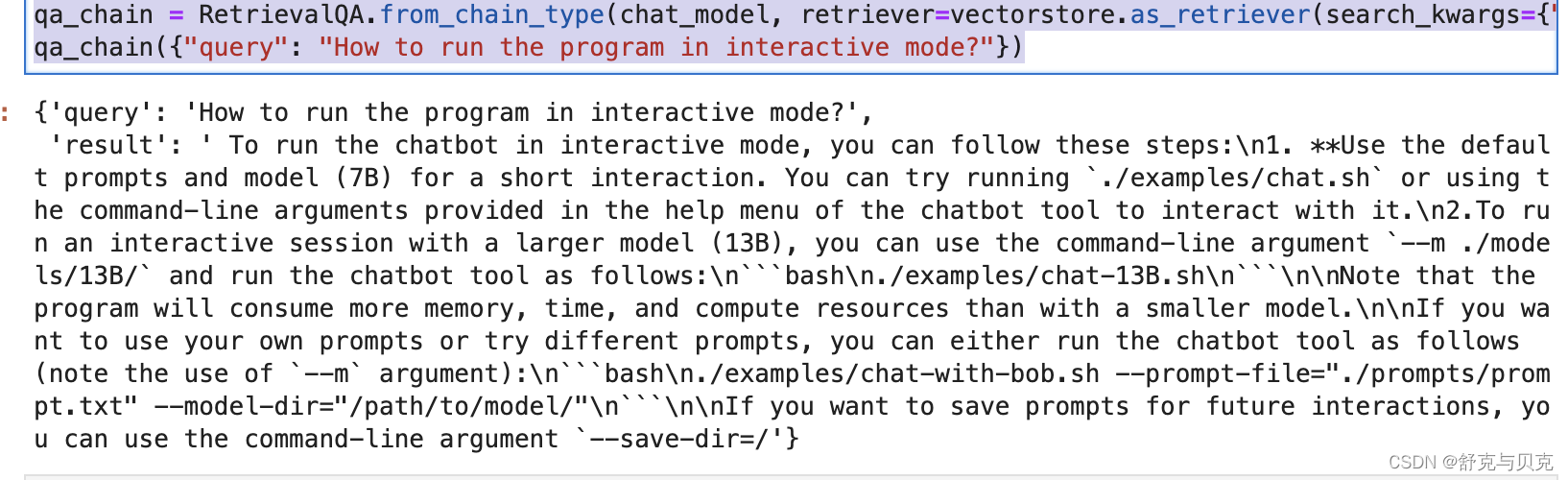
构造RetrievalQA需要提供一个LLM的实例,我们提供基于本地部署的Llama2构造的ChatOpenAI;还需要提供一个文本的Retriever,我们提供FAISS向量数据库作为一个Retriever,参数search_kwargs={"k":1}设置了Retriever提取的文档分块的数量,决定了最终Prompt包含的文档内容的数量,在这里我们设置为1。 向Chain中传入询问,即可得到LLM根据Retriever提取的文档做出的回答。
自定义RetrievalQA的Prompt:
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplatetemplate = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Use three sentences maximum and keep the answer as concise as possible.
Always say "thanks for asking!" at the end of the answer.
{context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)qa_chain = RetrievalQA.from_chain_type(chat_model,retriever=vectorstore.as_retriever(search_kwargs={"k": 1}),chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
qa_chain({"query": "What is --interactive option used for?"})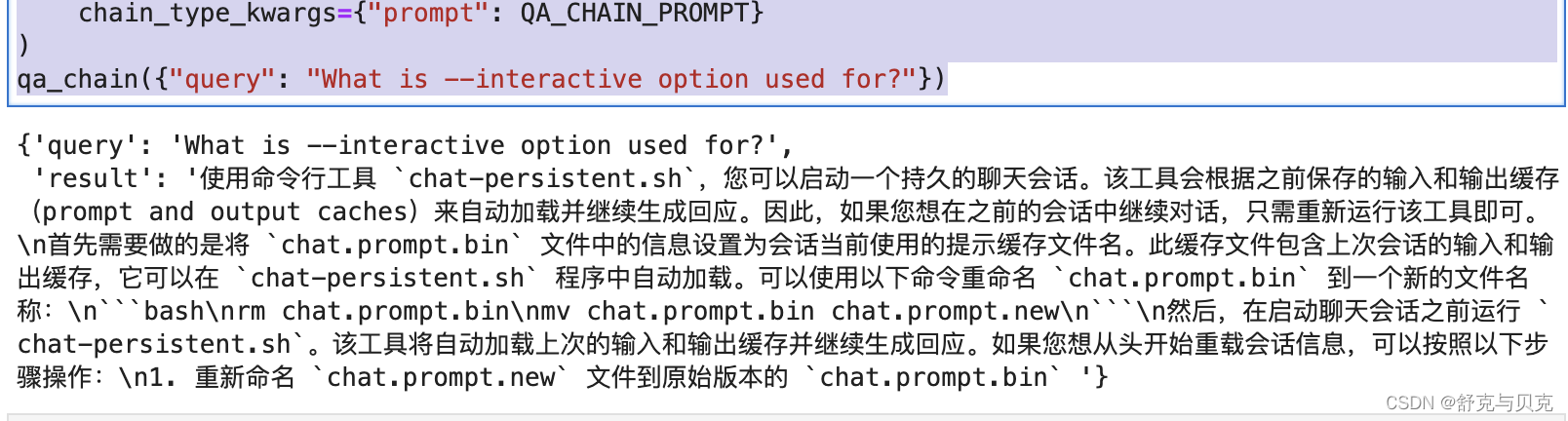
结论
本文介绍了如何在MacBook Pro本地环境使用llama.cpp部署ggml量化格式的Llama2语言模型,并演示如何使用LangChain简单构造了一个文档Q&A应用。
References
[1] https://github.com/ggerganov/llama.cpp
[2] QA over Documents | ️ Langchain
在MacBook Pro部署Llama2语言模型并基于LangChain构建LLM应用 - 知乎 (zhihu.com)
使用GGML和LangChain在CPU上运行量化的llama2 - 知乎 (zhihu.com)



和 pandas 库对日志数据进行分析)





 续4)


)


)
概率的基本概念)


(单表与多表))