kafka笔记
1/kafka是一个分布式的消息缓存系统
2/kafka集群中的服务器都叫做broker
3/kafka有两类客户端,一类叫producer(消息生产者),一类叫做consumer(消息消费者),客户端和broker服务器之间采用tcp协议连接
4/kafka中不同业务系统的消息可以通过topic进行区分,而且每一个消息topic都会被分区,以分担消息读写的负载
5/每一个分区都可以有多个副本,以防止数据的丢失
6/某一个分区中的数据如果需要更新,都必须通过该分区所有副本中的leader来更新
7/消费者可以分组,比如有两个消费者组A和B,共同消费一个topic:order_info,A和B所消费的消息不会重复
比如 order_info 中有100个消息,每个消息有一个id,编号从0-99,那么,如果A组消费0-49号,B组就消费50-99号
8/消费者在具体消费某个topic中的消息时,可以指定起始偏移量
集群安装
1、解压
2、修改server.properties
broker.id=1
zookeeper.connect=weekend05:2181,weekend06:2181,weekend07:2181
3、将zookeeper集群启动
4、在每一台节点上启动broker
bin/kafka-server-start.sh config/server.properties5、在kafka集群中创建一个topic
bin/kafka-topics.sh --create --zookeeper weekend05:2181 --replication-factor 3 --partitions 1 --topic order6、用一个producer向某一个topic中写入消息
bin/kafka-console-producer.sh --broker-list weekend:9092 --topic order7、用一个comsumer从某一个topic中读取信息
bin/kafka-console-consumer.sh --zookeeper weekend05:2181 --from-beginning --topic order8、查看一个topic的分区及副本状态信息
bin/kafka-topics.sh --describe --zookeeper weekend05:2181 --topic orderkafka消息分组及leader示意
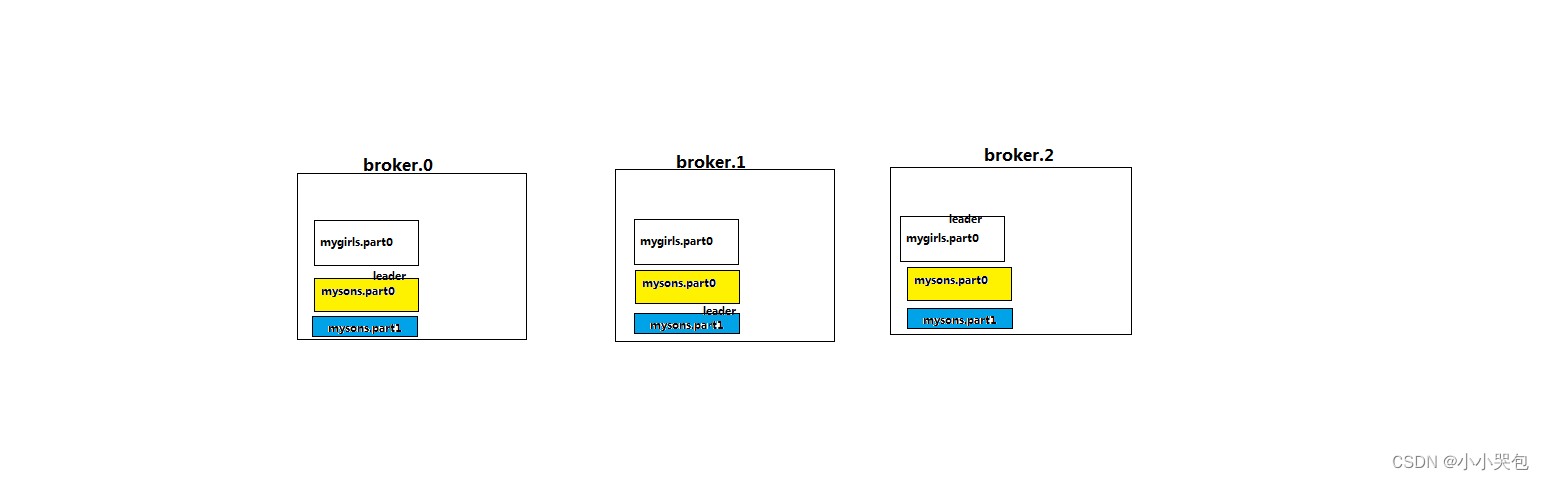
kafka消费者分组的机制

kafka和storm的整合机制
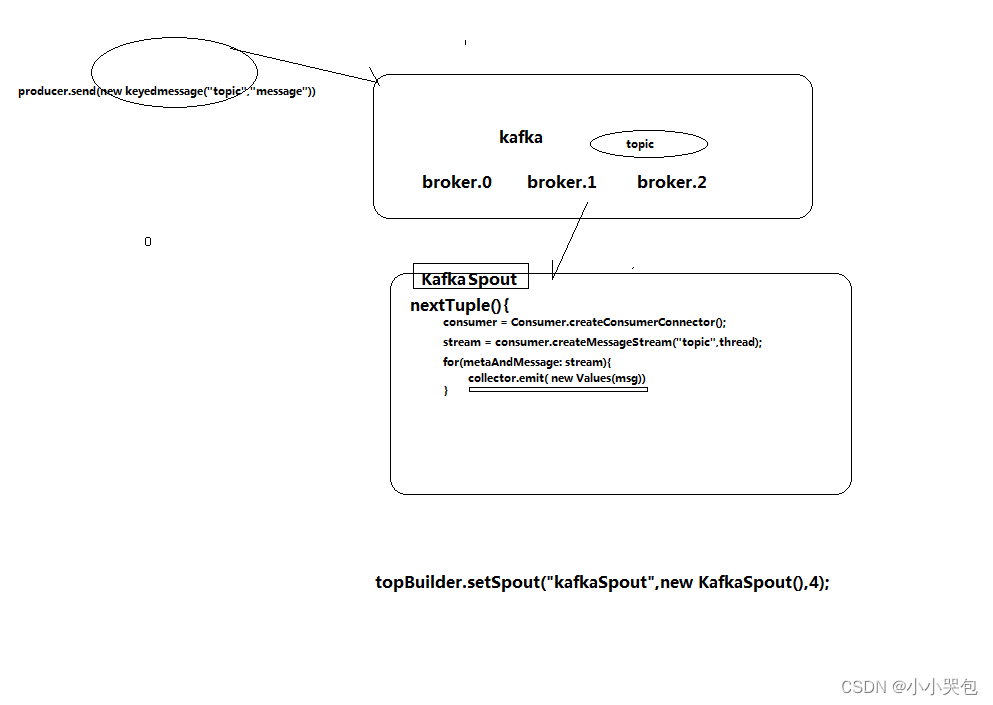
kafka-storm的整合机制2
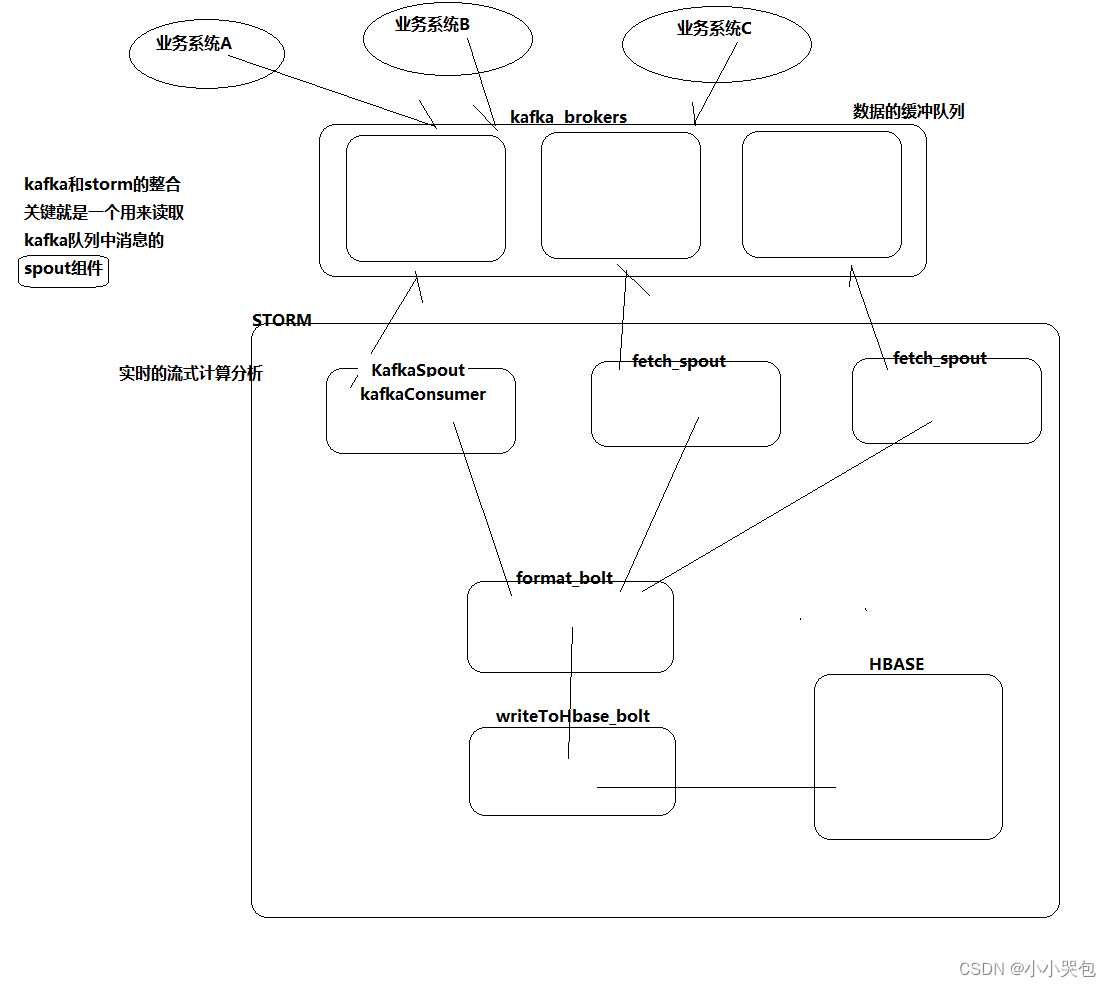


)












Axios)



)