概述
安装
关于ES的安装不做重点讲解,这里提供一个k8s基于sts创建以及ingress访问的模板文件。
---
apiVersion: apps/v1
kind: StatefulSet
metadata:labels:app: elasticsearchcomponent: masterrelease: elasticsearchname: elasticsearch-masternamespace: es
spec:podManagementPolicy: OrderedReadyreplicas: 3revisionHistoryLimit: 10selector:matchLabels:app: elasticsearchserviceName: elasticsearch-mastertemplate:metadata:labels:app: elasticsearchcomponent: masterrelease: elasticsearchspec:affinity:podAntiAffinity:preferredDuringSchedulingIgnoredDuringExecution:- podAffinityTerm:labelSelector:matchLabels:app: elasticsearchcomponent: masterrelease: elasticsearchtopologyKey: kubernetes.io/hostnameweight: 1containers:- env:- name: NODE_DATAvalue: 'true'- name: NODE_MASTERvalue: 'true'- name: NODE_INGRESTvalue: 'true'- name: DISCOVERY_SERVICEvalue: elasticsearch-discovery- name: PROCESSORSvalueFrom:resourceFieldRef:divisor: '0'resource: limits.cpu- name: ELASTICSEARCH_USERNAMEvalue: elastic- name: ELASTIC_PASSWORDvalue: your_password- name: ES_JAVA_OPTSvalue: '-Djava.net.preferIPv4Stack=true -Xms512m -Xmx512m '- name: MINIMUM_MASTER_NODESvalue: '2'image: 'your_image'imagePullPolicy: IfNotPresentname: elasticsearchports:- containerPort: 9300name: transportprotocol: TCP- containerPort: 9200name: httpprotocol: TCPreadinessProbe:failureThreshold: 3httpGet:path: /_cluster/health?local=trueport: 9200scheme: HTTPinitialDelaySeconds: 5periodSeconds: 10successThreshold: 1timeoutSeconds: 1resources:limits:cpu: '1'requests:cpu: 25mmemory: 512MiterminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /usr/share/elasticsearch/dataname: data- mountPath: /usr/share/elasticsearch/config/elasticsearch.ymlname: configsubPath: elasticsearch.ymldnsPolicy: ClusterFirstimagePullSecrets:- name: registry-secretinitContainers:- command:- sysctl- '-w'- vm.max_map_count=262144image: 'your_image'imagePullPolicy: IfNotPresentname: sysctlsecurityContext:privileged: trueterminationMessagePath: /dev/termination-logterminationMessagePolicy: File- command:- /bin/bash- '-c'- >-chown -R elasticsearch:elasticsearch /usr/share/elasticsearch/data&& chown -R elasticsearch:elasticsearch/usr/share/elasticsearch/logsimage: 'your_image'imagePullPolicy: IfNotPresentname: chownsecurityContext:runAsUser: 0terminationMessagePath: /dev/termination-logterminationMessagePolicy: FilevolumeMounts:- mountPath: /usr/share/elasticsearch/dataname: datarestartPolicy: AlwaysschedulerName: default-schedulersecurityContext:fsGroup: 1000serviceAccount: elasticsearch-masterserviceAccountName: elasticsearch-masterterminationGracePeriodSeconds: 30volumes:- configMap:defaultMode: 420name: elasticsearchname: configupdateStrategy:type: RollingUpdatevolumeClaimTemplates:- metadata:name: dataspec:accessModes:- ReadWriteOnceresources:requests:storage: 3GivolumeMode: Filesystem---
apiVersion: v1
kind: Service
metadata:labels:app: elasticsearchcomponent: masterrelease: elasticsearchname: elasticsearchnamespace: es
spec:ports:- name: httpport: 9200protocol: TCPtargetPort: httpselector:app: elasticsearchcomponent: masterrelease: elasticsearchtype: ClusterIP---
apiVersion: v1
kind: Service
metadata:labels:app: elasticsearchcomponent: masterrelease: elasticsearchname: elasticsearch-discoverynamespace: es
spec:clusterIP: Noneports:- port: 9300protocol: TCPtargetPort: transportselector:app: elasticsearchcomponent: masterrelease: elasticsearchtype: ClusterIP---
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:name: esnamespace: es
spec:rules:- host: your_domainhttp:paths:- backend:serviceName: elasticsearchservicePort: 9200path: /基本概念
索引
类型
文档
映射
字段
集群
分片
DSL
使用
在了解完ES的使用场景和基本概念后,接下来开发进行一些准备工作,进入到ES的基本使用环节。
客户端工具
ES的服务端安装完成后,以及对基本概念有一定的了解,进一步使用肯定要借助一些客户端,由于ES的使用都是基于REST风格的API,因此可以使用支持HTTP请求的REST API调用工具都可以进行服务端操作,例如PostMan,这里推荐几个常用的工具如Kibana,或者Edge浏览器中可以使用的扩展插件Elasticvue、ES-client等。
基础语法
类比于关系型数据库查询的SQL语言,在ES中使用DSL语言与服务器进行交互。ES中关于数据的操作交互可以分为两大类,索引(index)操作和文档(document)操作。接下来关于REST API的调用使用Elasticvue工具进行演示。使用REST请求,因此查用的请求类型也分别对应POST、PUT、GET、DELETE。
操作索引
创建索引(映射)
索引和映射可以同时创建,也可以先创建索引,再进行映射的创建。
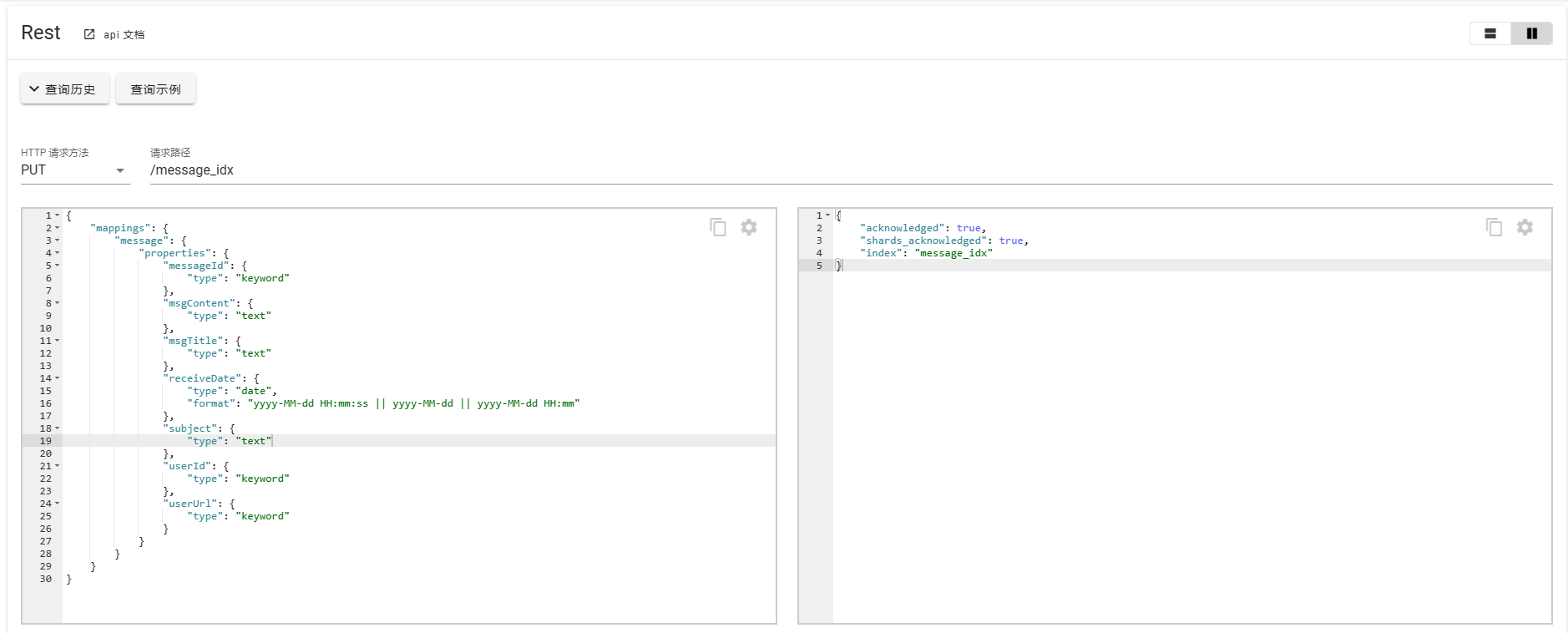
{"mappings": {"message": {"properties": {"messageId": {"type": "keyword"},"msgContent": {"type": "text"},"msgTitle": {"type": "text"},"receiveDate": {"type": "date","format": "yyyy-MM-dd HH:mm:ss || yyyy-MM-dd || yyyy-MM-dd HH:mm"},"subject": {"type": "text"},"userId": {"type": "keyword"},"userUrl": {"type": "keyword"}}}}
}
删除索引
DELETE message_idx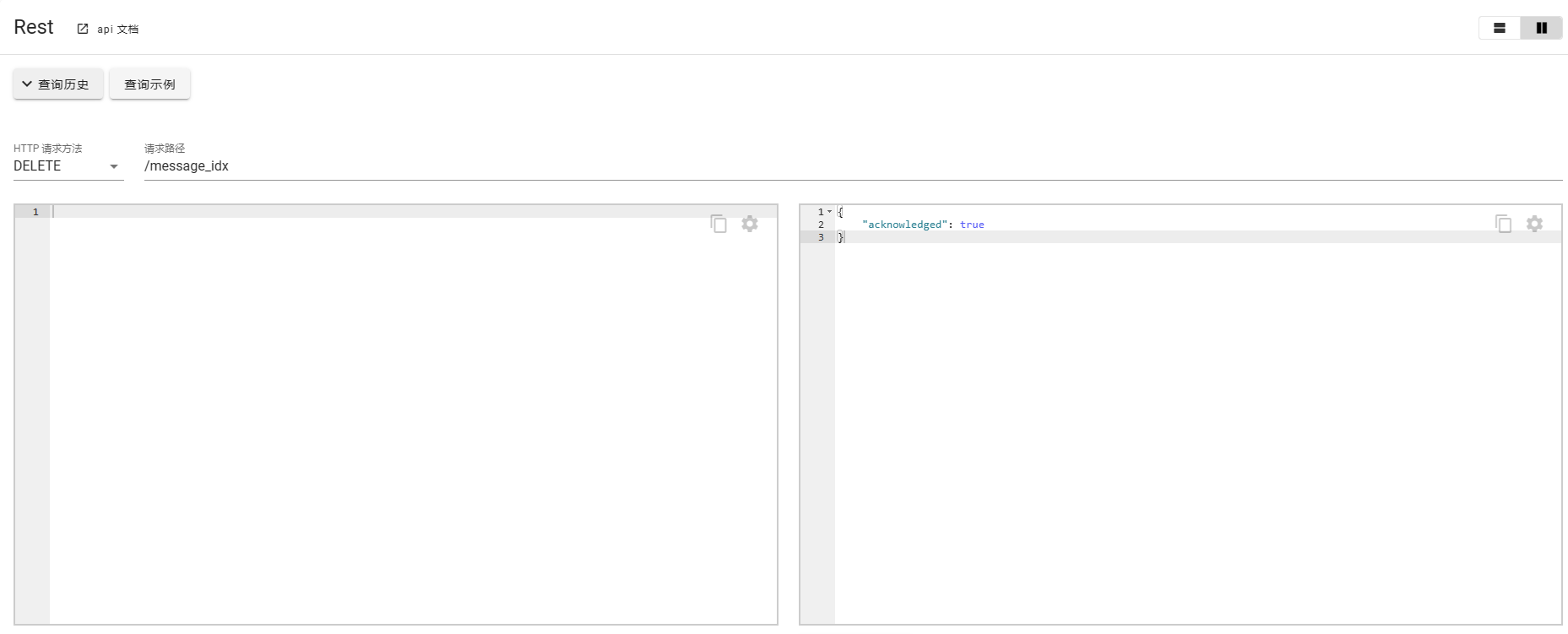
重建索引
一般创建索引时也就意味着数据结构已经确定,如果需要修改mapping信息时,那就需要对索引进行重建。
POST _reindex
{"source": {"index": "test_index"},"dest": {"index": "test_index_new"}
}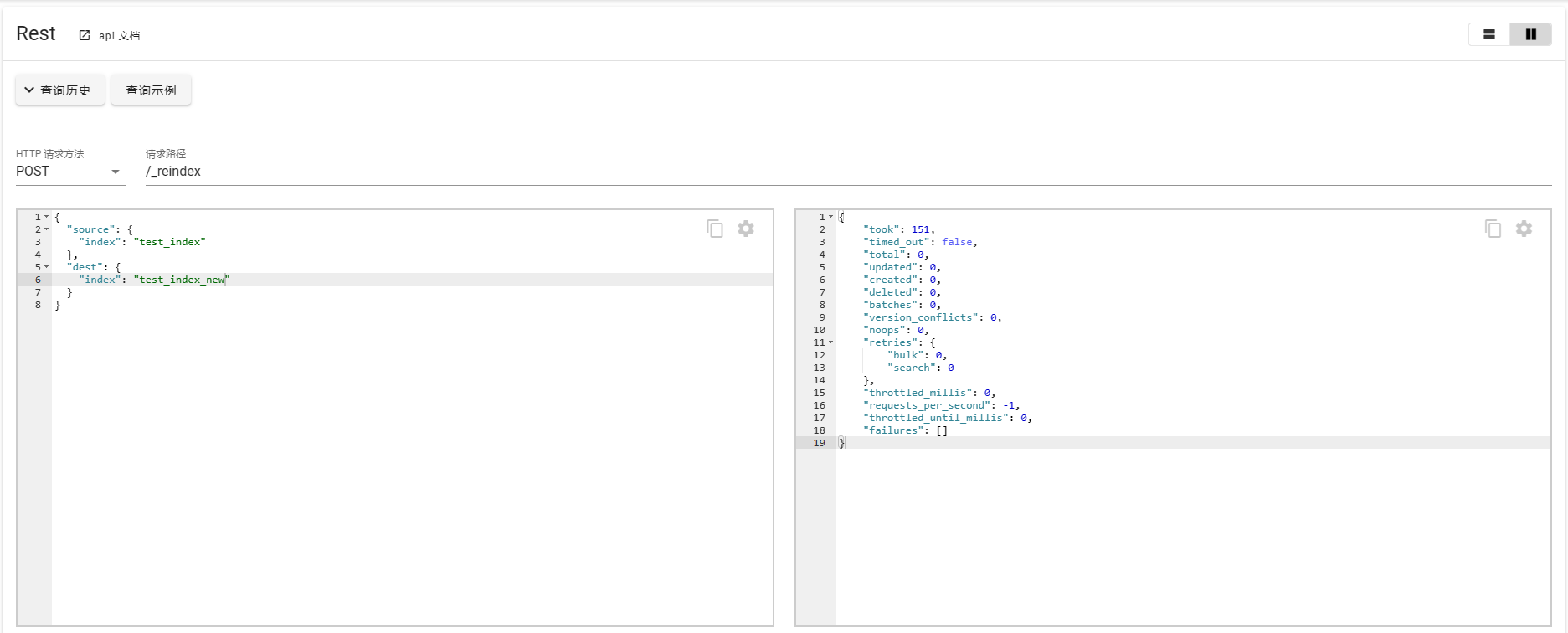
如果重建时间可能太长,可以添加参数?wait_for_completion=false直接返回taskId。
别名
索引别名是用于引用一个或多个现有索引的辅助名称。简单来说就是,一个索引可以通过别名进行调用,也可以使用本身的名称进行调用。一个索引可以绑定多个别名,一个别名也可以绑定多个索引。使用别名的好处主要有以下几点:
-
索引切换:通过使用别名,可以将一个别名绑定到一个或多个索引上。这样,在索引切换或滚动升级时,可以更新别名的绑定,而不需要修改应用程序中对索引的引用。这使得索引维护和数据迁移更加灵活和无缝。
-
查询分发:别名可以作为查询的目标,将查询请求分发到多个索引上。这对于在多个索引上执行相同的查询非常有用,尤其是当索引按时间进行分割或分片时。通过使用别名,可以将查询发送到所有相关的索引,而不需要显式指定每个索引的名称。
-
索引别名过滤:别名还可以与过滤器结合使用,以将查询限制为特定的索引或索引模式。通过为别名定义过滤条件,可以创建只包含满足特定条件的文档的虚拟索引视图。这对于数据分区、安全性和权限控制非常有用。
-
索引重命名:通过修改别名的绑定,可以实现索引的重命名操作。这在需要更改索引名称或将索引从一个集群迁移到另一个集群时非常有用。
通过使用别名,可以提供更灵活、更抽象的索引命名和查询操作,使得索引的管理和使用更加方便和可靠。
别名的操作使用POST _aliases,使用如下所示:
绑定/解绑别名
- 绑定
POST _aliases
{"actions" : [{ "add" : { "index" : "test_index", "alias" : "test_index_aliases" } }]
}- 解绑
POST /_aliases
{"actions" : [{ "remove" : { "index" : "test_index", "alias" : "test_index_aliases" } }]
}更换别名
POST /_aliases
{"actions" : [{ "remove" : { "index" : "test_index", "alias" : "test_index_aliases" } },{ "add" : { "index" : "test_index", "alias" : "test" } }]
}绑定多个别名
POST /_aliases
{"actions" : [{ "add" : { "index" : "test_index_1", "alias" : "test" } },{ "add" : { "index" : "test_index_2", "alias" : "test" } }]
}操作文档
文档操作可以说是ES中使用最多的操作类型了,通常也是使用相应的REST请求。这里主要介绍以下几种常用操作。
基本操作
文档的基本操作,相对于传统数据库无非也是CRUD,使用最多的就是PUT和POST操作了,关于二者的区别如下:
在 Elasticsearch 中,"PUT" 和 "POST" 是两种不同的 HTTP 方法,用于向 Elasticsearch 发送请求。
-
PUT 方法:PUT 方法用于创建或更新文档。如果指定了文档的 ID,它将尝试将提供的文档内容放置在该 ID 对应的位置。如果该 ID 不存在,它将创建一个新的文档。如果没有指定 ID,Elasticsearch 将自动生成一个唯一的 ID,并创建一个新文档。PUT 方法是幂等的,这意味着多次执行相同的 PUT 请求会产生相同的结果。
-
POST 方法:POST 方法用于在 Elasticsearch 中执行各种操作,包括创建文档、更新文档、搜索等。与 PUT 方法不同,POST 方法不要求指定文档的 ID。如果指定了 ID,它将尝试将提供的文档内容放置在该 ID 对应的位置。如果没有指定 ID,Elasticsearch 将自动生成一个唯一的 ID,并创建一个新文档。POST 方法不是幂等的,这意味着多次执行相同的 POST 请求可能会产生不同的结果。
总结:
- PUT 方法用于创建或更新文档,需要指定文档的 ID,是幂等的。
- POST 方法用于执行各种操作,包括创建或更新文档,可以不指定文档的 ID,不是幂等的。
创建文档
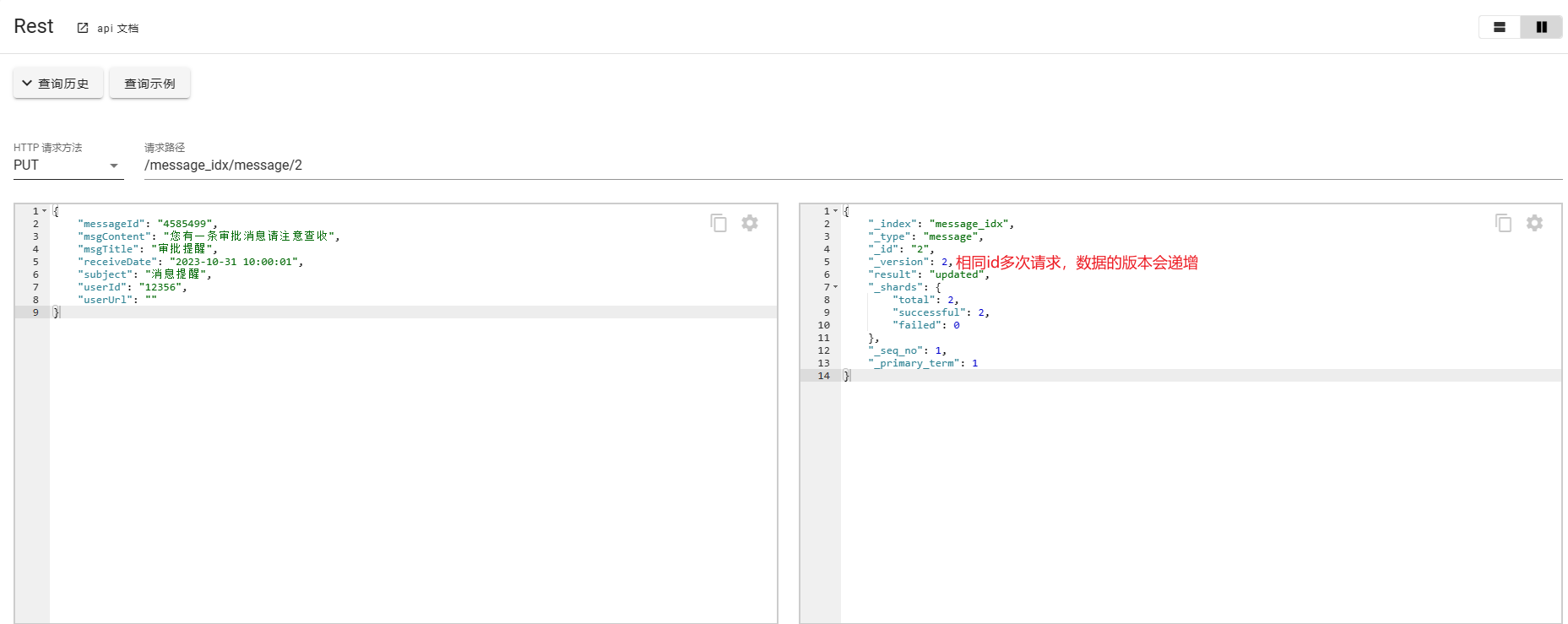
- 使用PUT
请求路径携带id,如果id不存在会自动创建数据,如果id存在会进行替换。
PUT /message_idx/message/1
{"messageId": "4585499","msgContent": "您有一条审批消息请注意查收","msgTitle": "审批提醒","receiveDate": "2023-10-31 10:00:01","subject": "消息提醒","userId": "12356","userUrl": ""
}
请求路径无id,可以看到服务端返回提示这种场景下应该使用POST请求。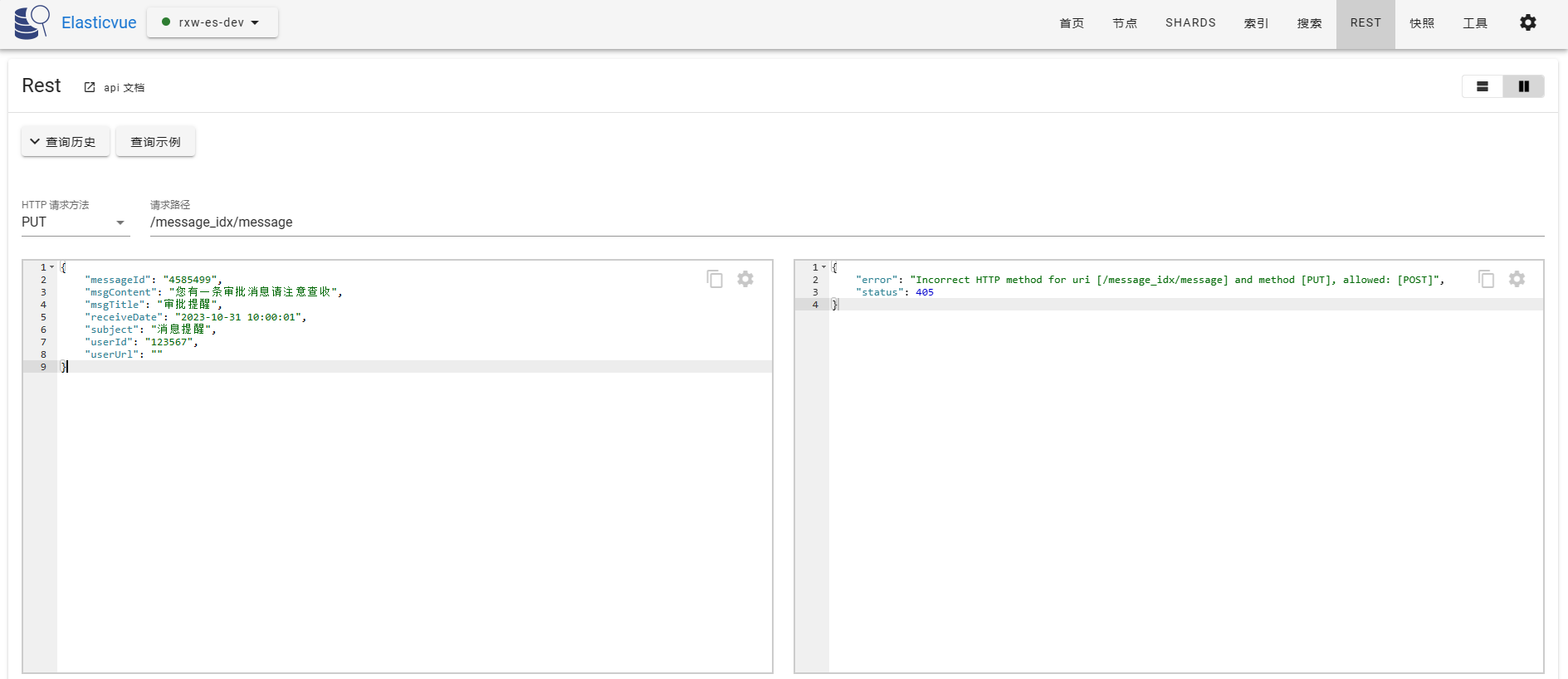
- 使用POST
POST /message_idx/message
{"messageId": "4585499","msgContent": "您有一条审批消息请注意查收","msgTitle": "审批提醒","receiveDate": "2023-10-31 10:00:01","subject": "消息提醒","userId": "123567","userUrl": ""
}使用POST可以不携带id,会自定生成id并创建数据。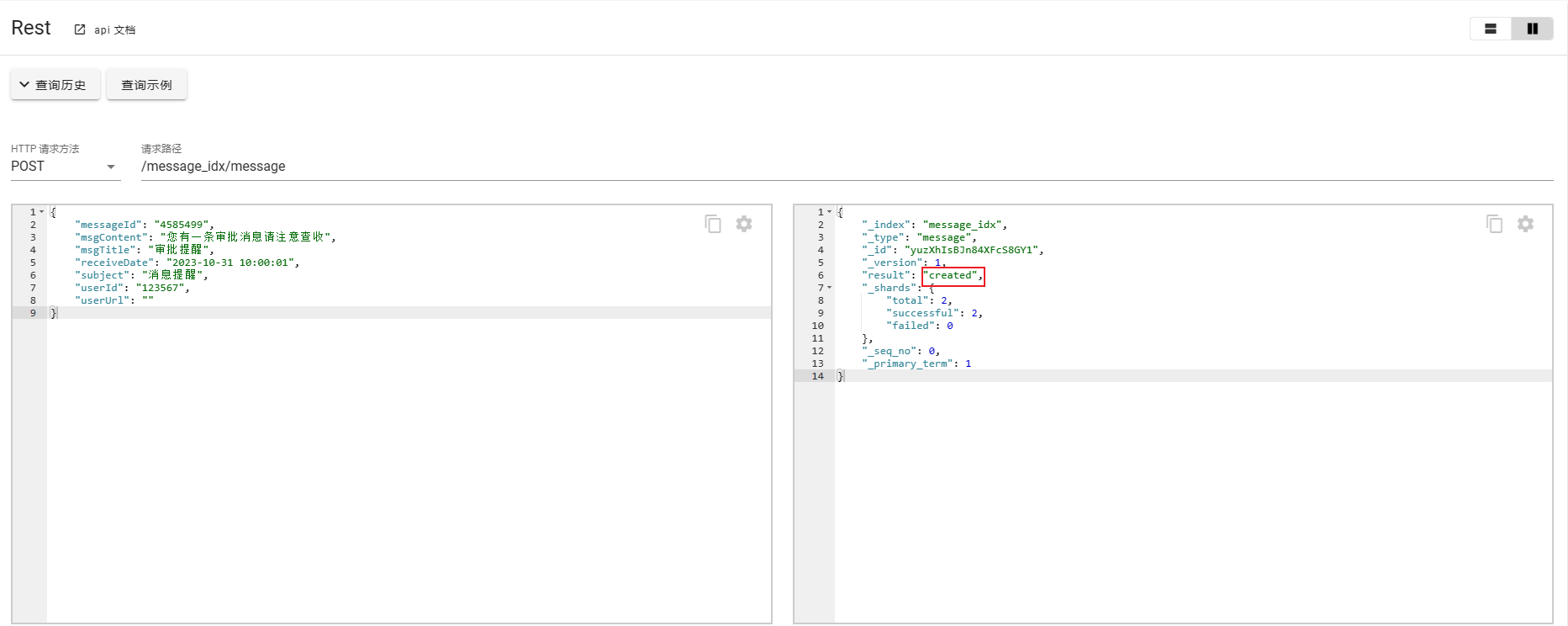
通过以上的案例可以说明PUT侧重数据的更新,POST更侧重于数据的创建,如果请求携带了id的时候POST和PUT的处理方式基本一致,区别在于请求没有携带id的场景。
另外需要注意的是:
对于请求路径格式为 POST/PUT /index_name/_doc/document_id,有以下说明
- index_name: 索引名称
- _doc: type类型
- document_id: 文档id
关于_doc(type)引用官方文档有以下说明:
Elasticsearch 是一个开源的分布式搜索和分析引擎,它是基于 Apache Lucene 构建的。在 Elasticsearch 的早期版本中,它使用了一种叫做 "types" 的概念来组织文档。然而,自从 Elasticsearch 6.0 版本发布以来,types 的概念已经被弃用,并且在 Elasticsearch 7.0 版本中完全移除了。
下面是 Elasticsearch 中 type 发展历史的简要概述:
- Elasticsearch 1.x:在 Elasticsearch 1.x 版本中,文档被组织在索引(index)之中,并且可以在索引级别下定义多个 types。每个 type 有自己的映射(mapping),它定义了文档的字段和数据类型。这种类型的组织结构使得索引可以存储多种相关但具有不同结构的文档。
- Elasticsearch 2.x:随着 Elasticsearch 2.x 版本的发布,Elastic 团队开始逐渐弃用 type 的概念。虽然仍然可以在索引中定义多个 types,但 Elastic 官方建议将所有文档放在单个 type 中。这是为了减少混淆,因为很多用户都误解了 types 的含义和使用方式。
- Elasticsearch 6.x:在 Elasticsearch 6.0 版本中,types 被宣布为即将被移除的功能。Elastic 团队鼓励用户在升级到 Elasticsearch 6.x 时移除所有 types,并将所有文档放在单个 type 中。
- Elasticsearch 7.x:在 Elasticsearch 7.0 版本中,types 被完全移除。现在,文档只能被组织在一个索引中,而不是在多个 types 中。这意味着每个索引只有一个默认的 type
_doc,用于存储所有文档。
总结起来,随着 Elasticsearch 的发展,type 的概念逐渐被弃用并移除。Elasticsearch 7.x 版本及更高版本中,文档被组织在索引中,而不再使用 types。这种变化简化了数据模型,并提高了 Elasticsearch 的性能和可维护性。在使用ES时也要注意版本不同导致API调用的差异,尤其是系统框架升级时更应注意升级带来的影响。
删除文档
DELETE /message_idx/message/1注意查看返回结果。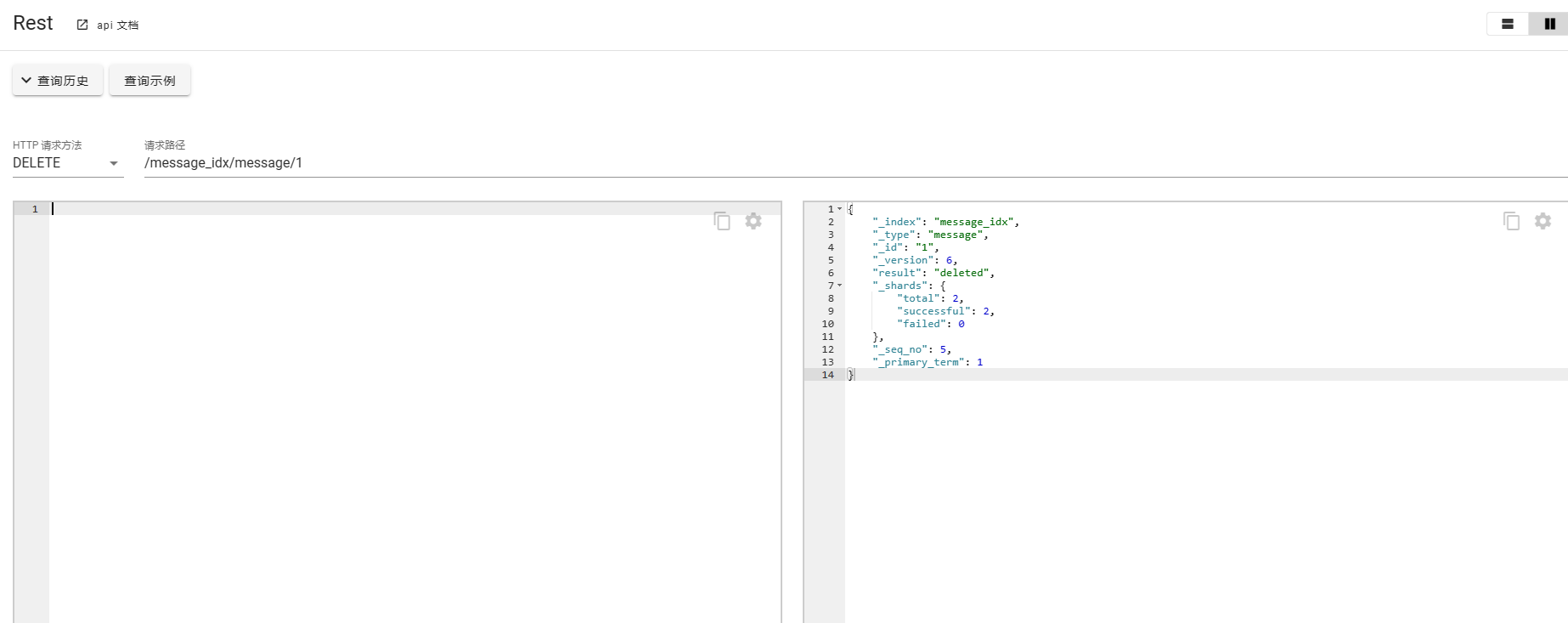
更新文档
POST /message_idx/message/1
{"doc": {"msgContent": "您有一条审批消息请注意查收!"}
}这里也可以使用PUT请求。
获取文档
这里说获取文档指的是根据id进行查询的方式,关于复杂查询,后续会进行详细介绍。
根据id获取单个文档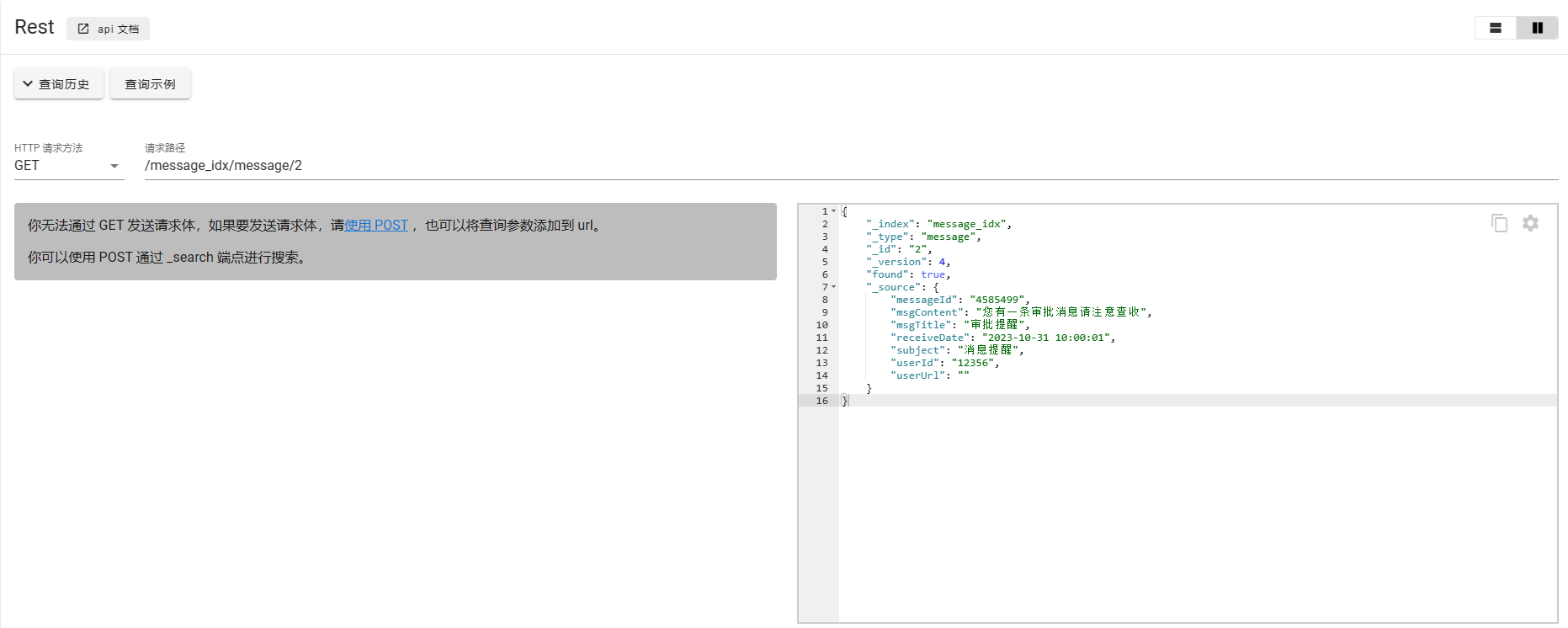
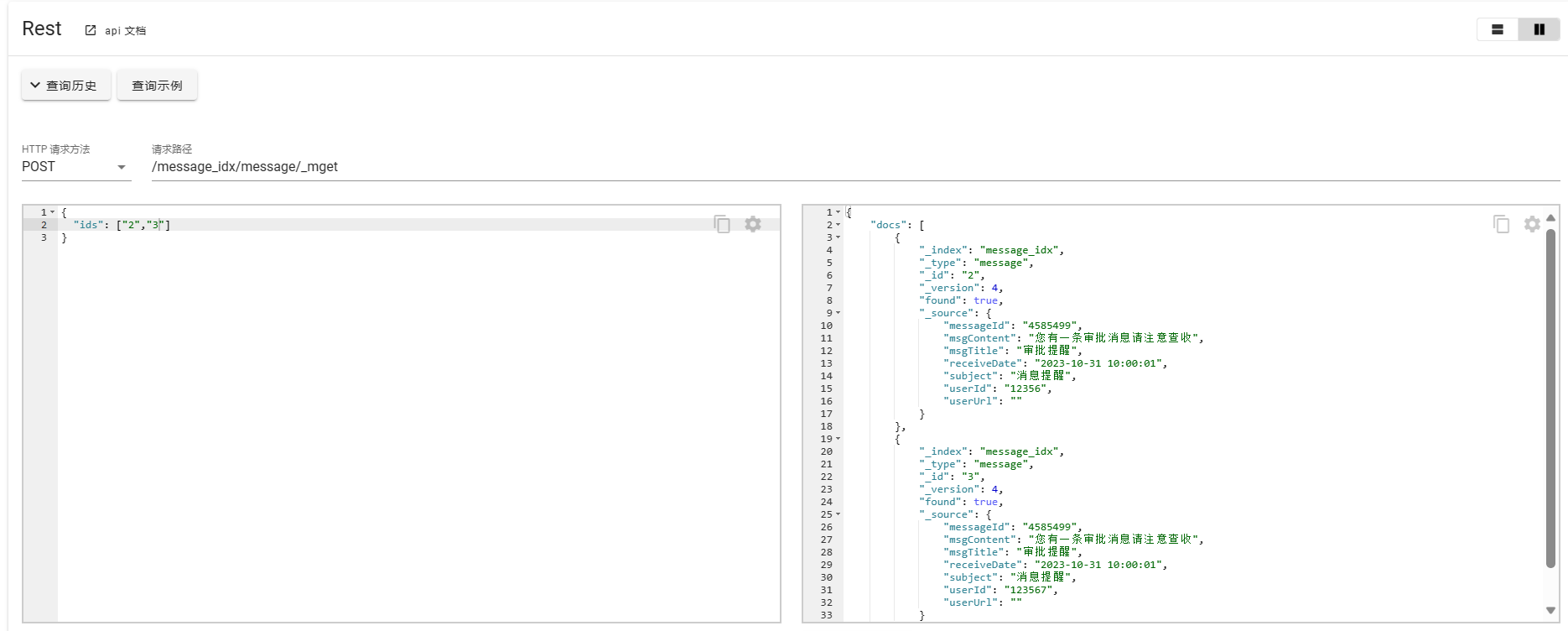
使用POST请求批量获取
POST /message_idx/message/_mget
{"ids": ["2","3"]
}
关于文档的创建、更新、删除操作主要做以上演示,在实际使用中需要注意PUT、POST在创建和更新时的细节差别,以及ES版本不同,导致请求REST API在请求路径结构商的不同。
查询操作
查询操作是ES使用中最重要的一部分内容。
Match查询
Match查询用来做基本的模糊查询,会对查询内容做分词,然后根据倒排索引去匹配文档。
- match_all
match_all没有查询条件会查询所有数据,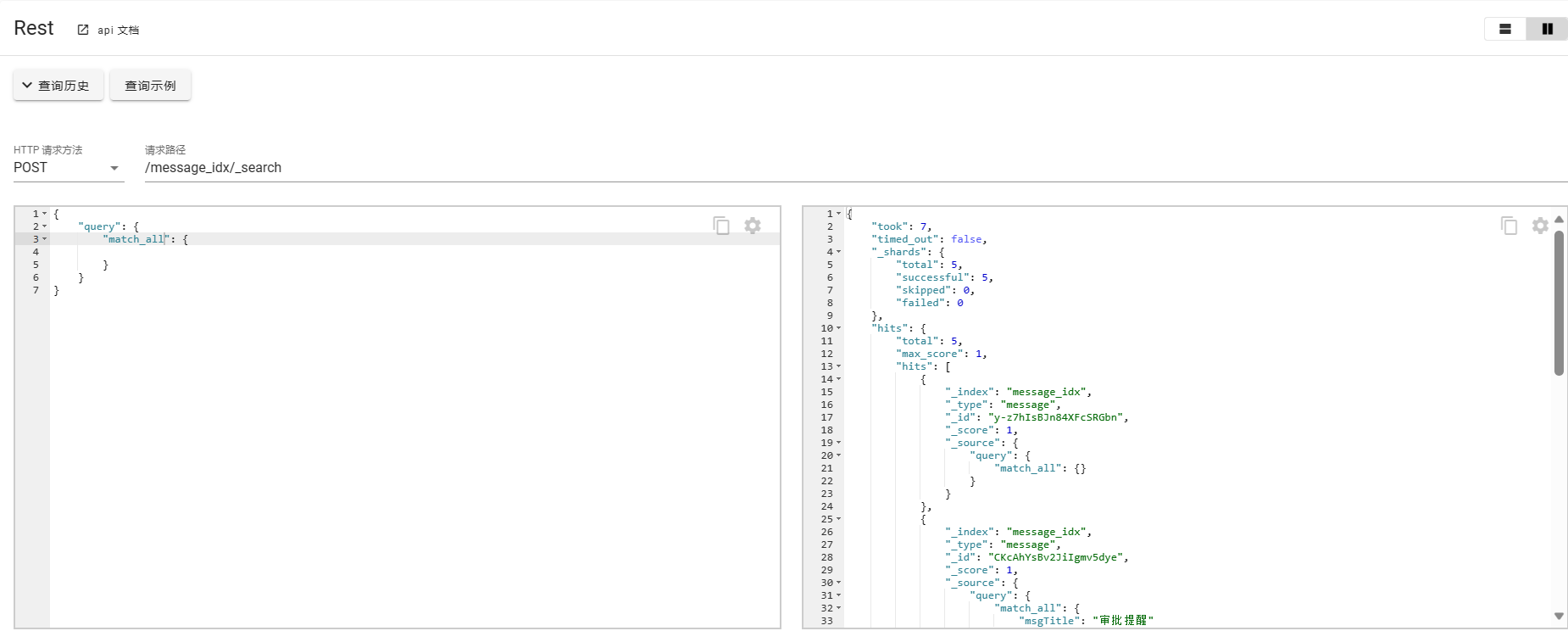
- match
基本的匹配查询,对于分词结果只要匹配的内容即可命中。
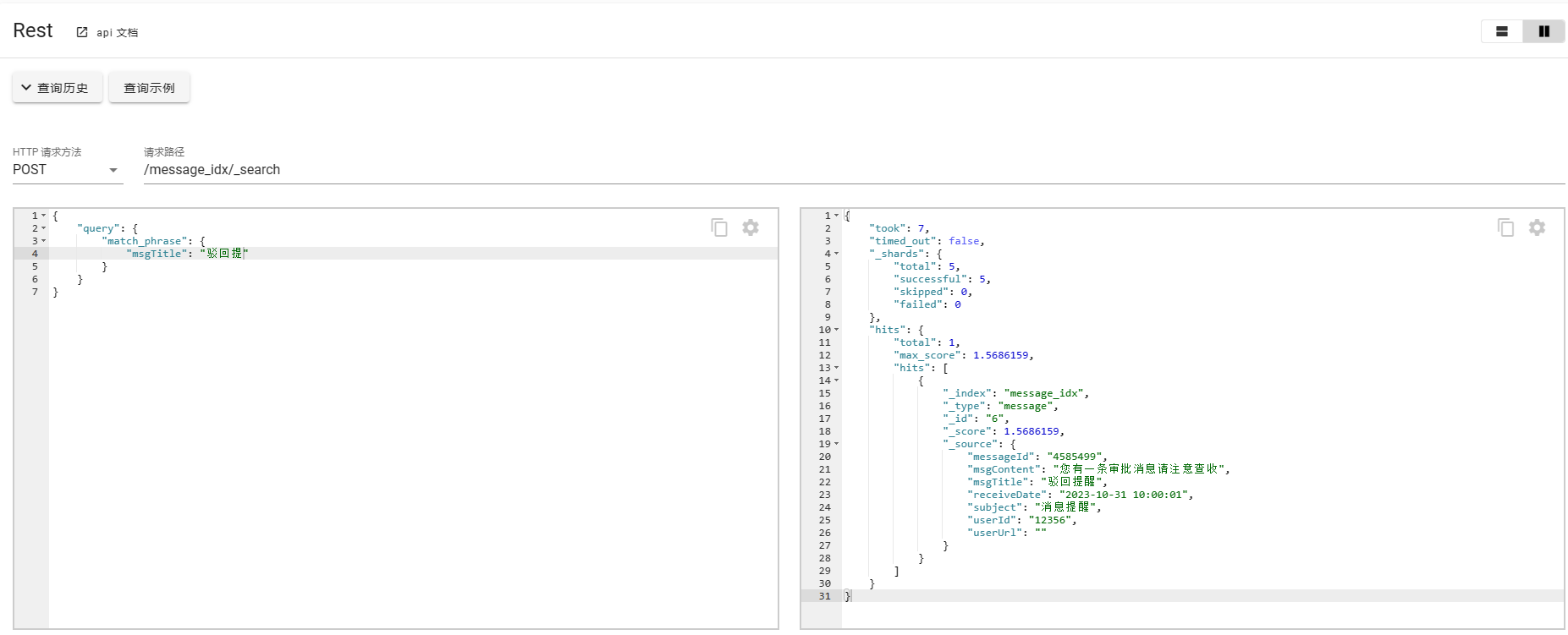
POST /message_idx/_search
{"query": {"match": {"msgTitle": "提醒驳回"}}
}对于输入内容提醒驳回进行分词,提醒、驳回,只要匹配这两个词都可以被命中返回数据。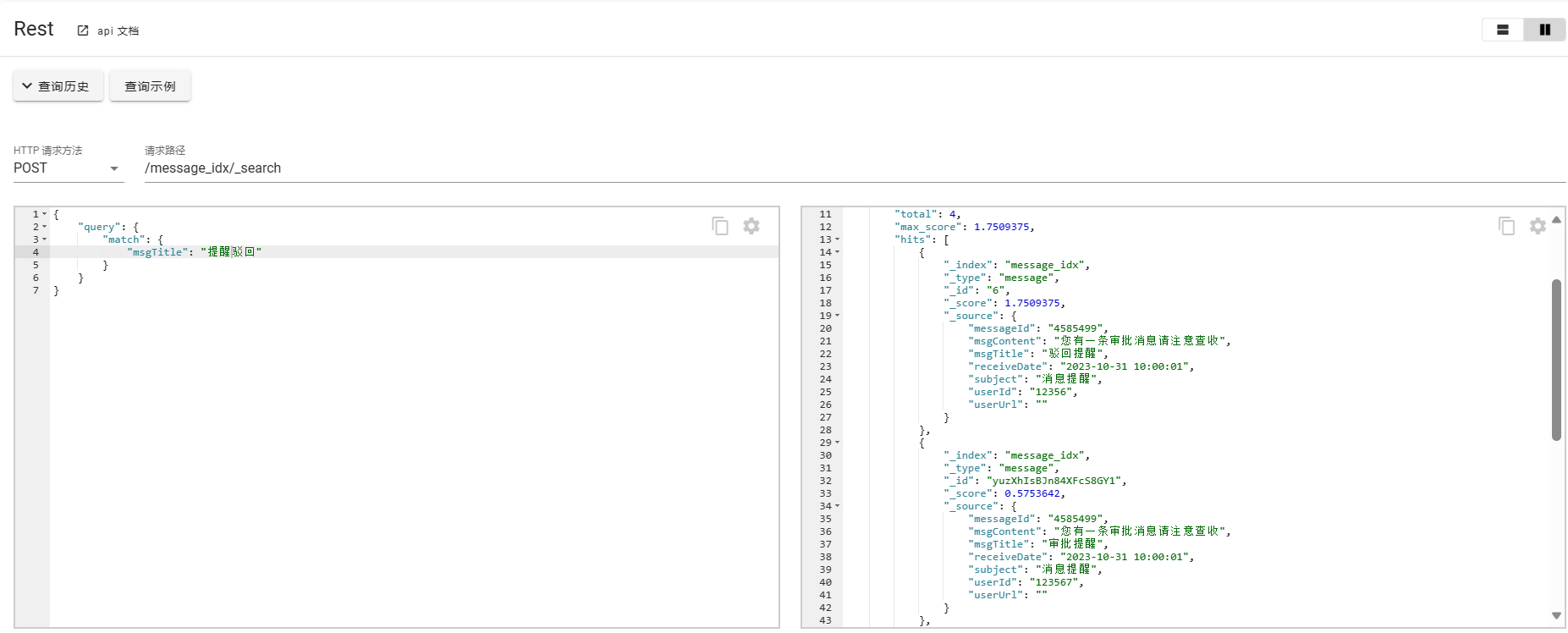
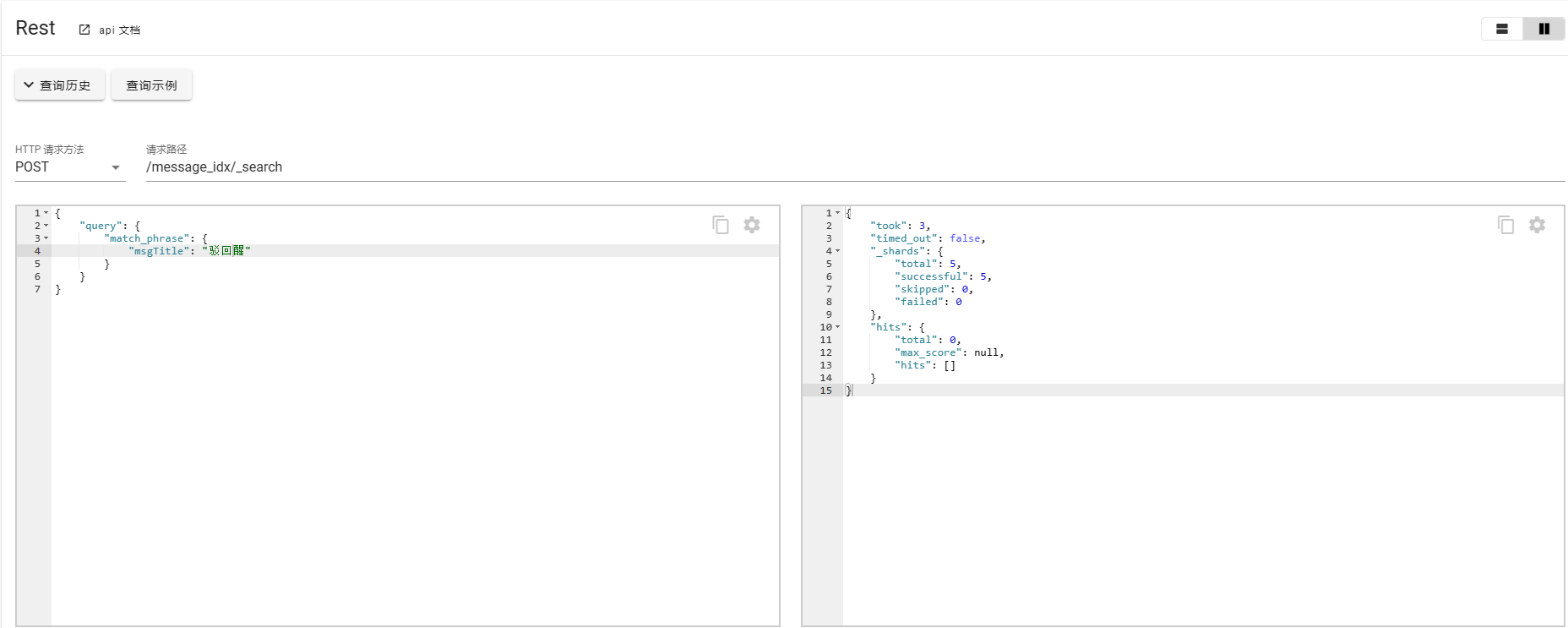
3. match_phrase
match_phrase的匹配条件较为严苛一点,需要严格匹配,会对输入的短语进行分词,并且要包含所有的分词结果并且顺序一致。
如下案例所示: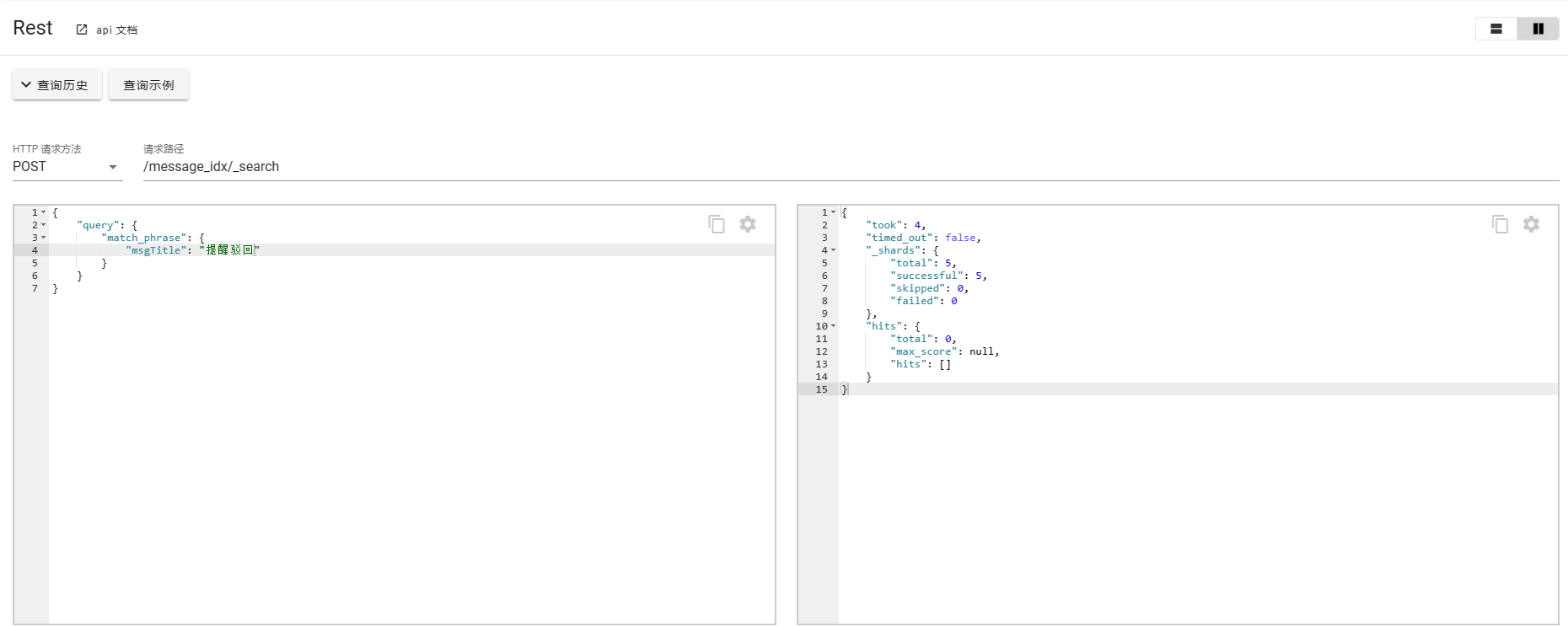
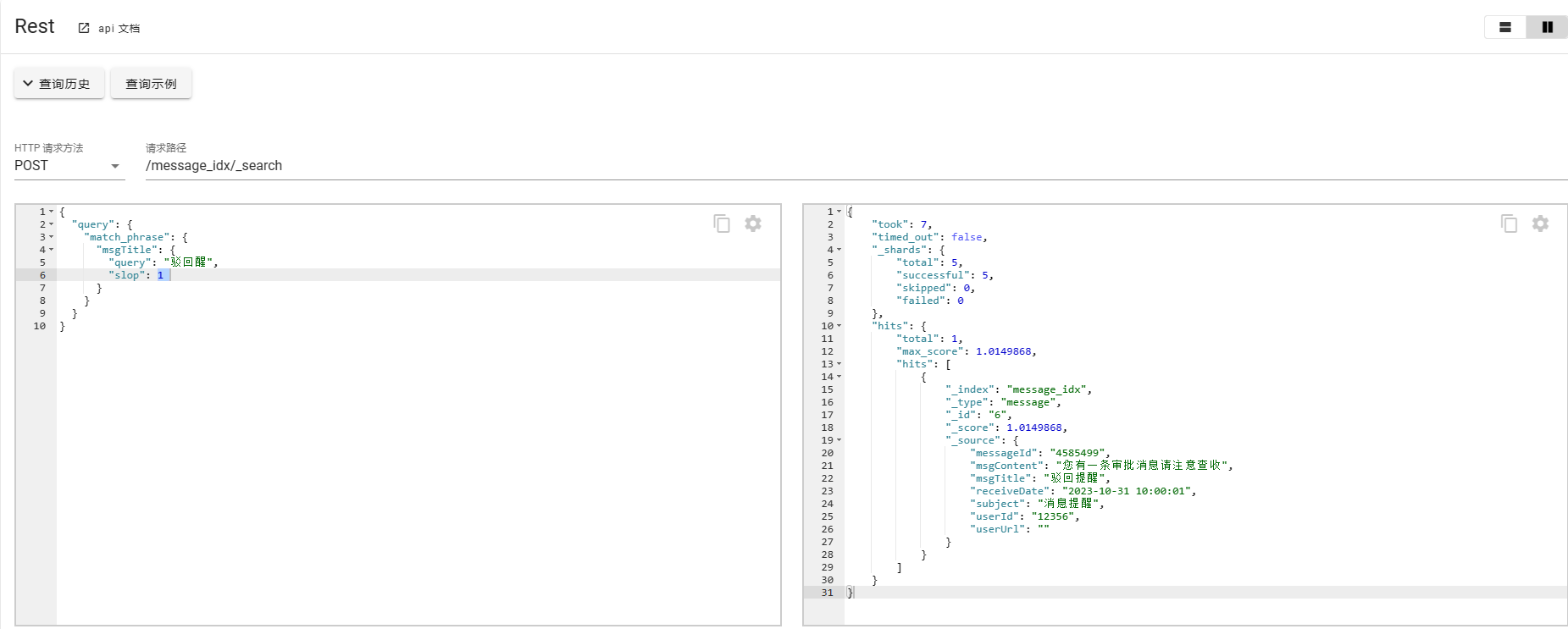
如果对于这种场景有特殊需求,刚好输入错误了单词或者字,ES也给出了相应的补救措施,使用slop进行修正
POST /message_idx/_search
{"query": {"match_phrase": {"msgTitle": {"query": "驳回醒","slop": 1}}}
}
对比场景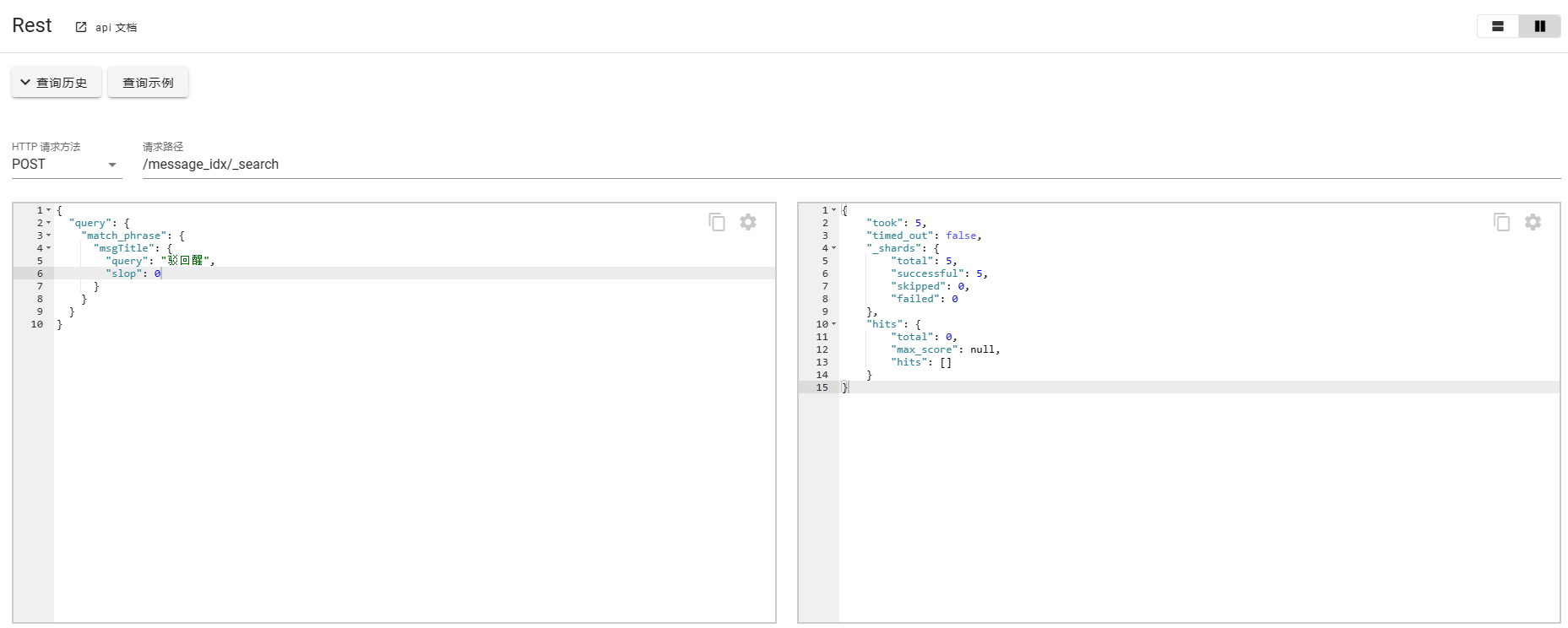
此外也可以使用match_phrase_prefix进行查询匹配。可以看做match_phrase的一个扩展,他会把query的查询条件进行分词,然后把最后一个单词看做是一个前缀,匹配索引中所有以这个单词为前缀的单词,然后进行返回。
关于更多的查询场景需要,可以去关注multi_match这种match类型的检索。
Term查询
Term查询对查询内容不做分词,直接去倒排索引里去匹配文档。
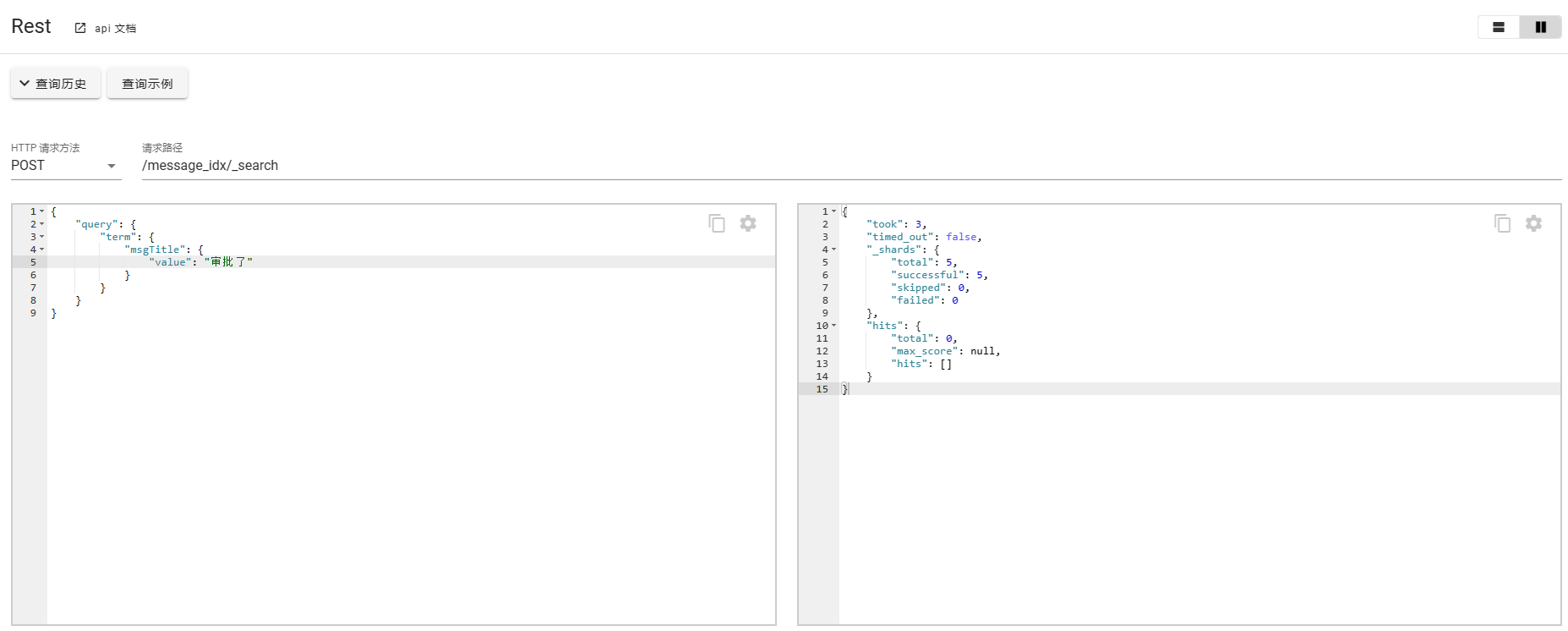
POST message_idx/_search
{"query": {"term": {"msgTitle": {"value": "审批"}}}
}# 匹配多个term
POST message_idx/_search
{"query": {"terms": {"msgTitle": ["审批","驳回"]}}
}
组合查询
翻页查询
聚合查询
范围查询
高亮查询
分组查询
子查询
分词
ES模糊查询的强大之处在于其可以进行分词并且维护成倒排索引,分词功能的实现需要借助于一次分词插件,对于中文支持比较好的分词插件就是IK分词器。基本使用如下所示: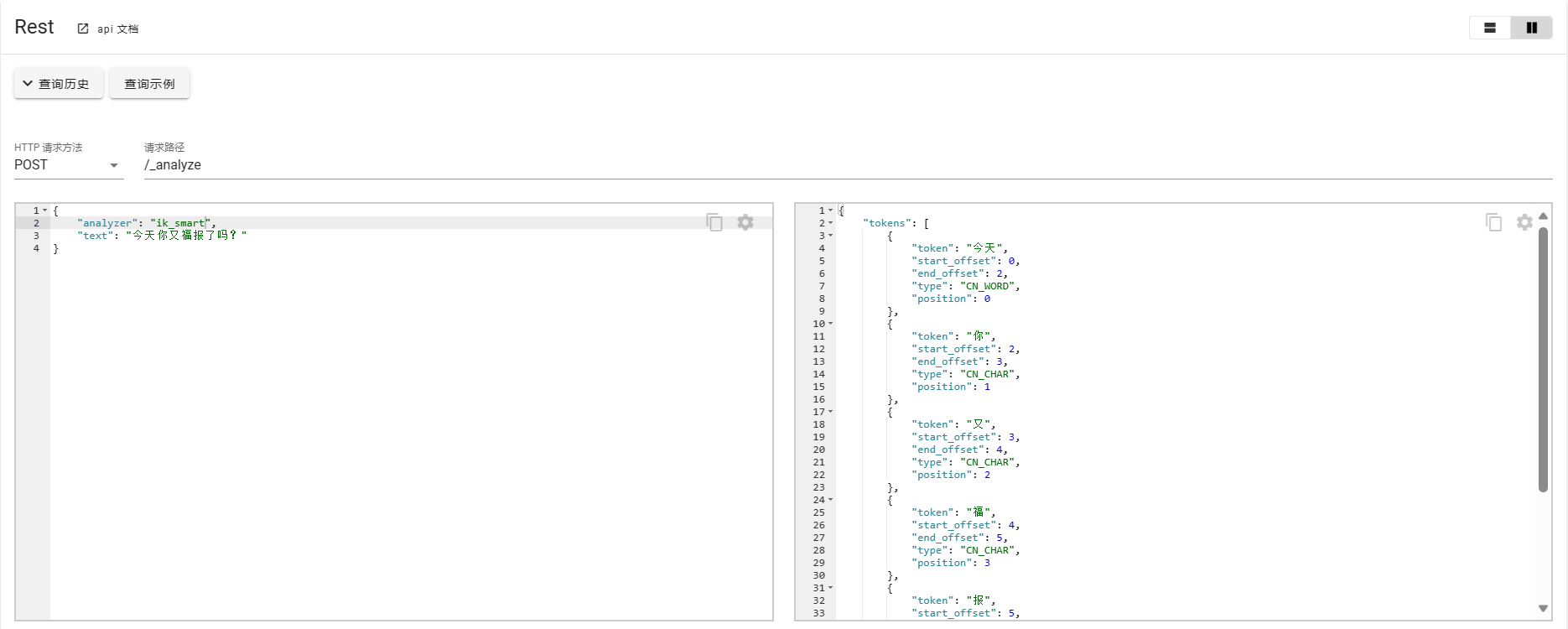
对于IK分词器常用的模式有以下几种:
POST _analyze
{"analyzer": "ik_smart","text": "中华人民共和国国歌"
}
POST _analyze
{"analyzer": "ik_max_word","text": "中华人民共和国国歌"
}补充
倒排索引
ES数据操作过程
写入过程
更新过程
删除过程
SpringBoot整合ES版本选择
上述介绍的基于REST API调用的客户端,在实际项目应用中是不能整合到系统集成的,只适合用来检索查看数据使用,Spring提供了一套关于ES的整合方案,并从属于SpringDataElasticsearch模块,针对不同版本的ES,SpringDataElasticsearch也提供了不同的适配方案,并且每个版本支持的客户端也不尽相同。
在使用的时候如果不提前选型或者做足够的了解,会遇到各种各样的坑,这里会对常用的客户端进行简介,并提供整合案例以供参考。
接下来所介绍的内容,主要参考官方文档。
客户端简介
简单来说,客户端存在的意义就是为了更好的使用ES,对服务端的数据进行操作。参考上文所提到的官方文档,目前为止,ES支持的客户端共有,Jest client、Rest client、Transport client、Node client几种,其中Jest和Rest是使用的HTTP协议,Transport client和Node client使用的是Native Elasticsearch binary协议。
在ES5.0之前官方提供的客户端只有Transport client、Node client协议,Jest为非官方支持客户端,ES5.0之后官方主推荐的为Rest客户端。

参考官方提醒,以及综上所述,在使用ES时尽可能的使用Rest Client。
关于Spring、SpringBoot、SpringDataElasticsearch版本的选择,可以参考如下官方提供的信息:
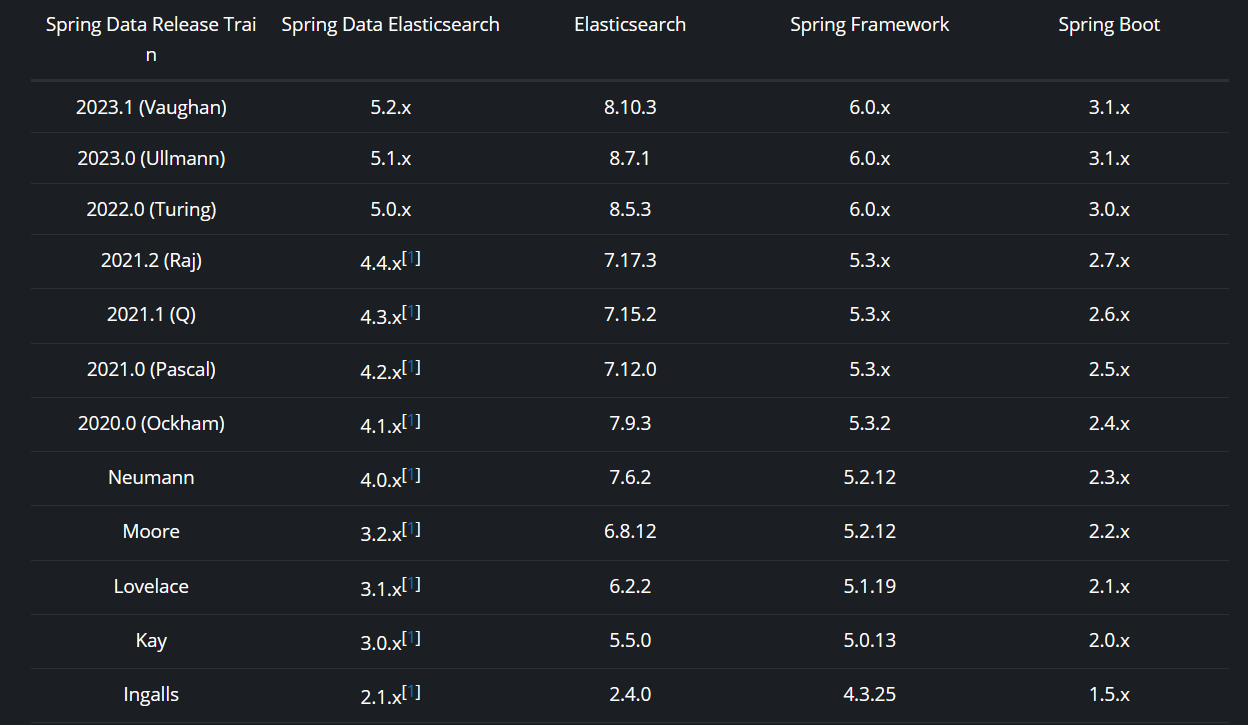
https://docs.spring.io/spring-data/elasticsearch/reference/index.html
整合案例
接下来使用SpringBoot 2.2.x及ES 6.5.x进行整合演示。
- 首先引入整合依赖。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>- 整合客户端
官方文档提供了两种整合方式,命令式和响应式客户端。
- 命令式
import org.springframework.data.elasticsearch.client.elc.ElasticsearchConfiguration;@Configuration
public class MyClientConfig extends ElasticsearchConfiguration {@Overridepublic ClientConfiguration clientConfiguration() {return ClientConfiguration.builder().connectedTo("localhost:9200").build();}
}- 响应式
import org.springframework.data.elasticsearch.client.elc.ReactiveElasticsearchConfiguration;@Configuration
public class MyClientConfig extends ReactiveElasticsearchConfiguration {@Overridepublic ClientConfiguration clientConfiguration() {return ClientConfiguration.builder().connectedTo("localhost:9200").build();}
}如果有其他特殊配置参数需要,可以设置
import org.springframework.data.elasticsearch.client.ClientConfiguration;
import org.springframework.data.elasticsearch.support.HttpHeaders;import static org.springframework.data.elasticsearch.client.elc.ElasticsearchClients.*;HttpHeaders httpHeaders = new HttpHeaders();
httpHeaders.add("some-header", "on every request")ClientConfiguration clientConfiguration = ClientConfiguration.builder().connectedTo("localhost:9200", "localhost:9291").usingSsl().withProxy("localhost:8888").withPathPrefix("ela").withConnectTimeout(Duration.ofSeconds(5)).withSocketTimeout(Duration.ofSeconds(3)).withDefaultHeaders(defaultHeaders).withBasicAuth(username, password).withHeaders(() -> {HttpHeaders headers = new HttpHeaders();headers.add("currentTime", LocalDateTime.now().format(DateTimeFormatter.ISO_LOCAL_DATE_TIME));return headers;}).withClientConfigurer(ElasticsearchClientConfigurationCallback.from(clientBuilder -> {// ...return clientBuilder;})). // ... other options.build();SpringDataElasticsearch中提供了一个高级API并且整合了客户端配置,也可以呃直接使用High Level REST Client完成整合,更加快速高效。
/*** ES客户端配置* @author starsray* @date 2023/11/01*/
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {@Override@Beanpublic RestHighLevelClient elasticsearchClient() {final ClientConfiguration clientConfiguration = ClientConfiguration.builder().connectedTo("localhost:9200").build();return RestClients.create(clientConfiguration).rest();}
}- API使用
ES实战应用场景
ES与MySQL的数据一致性问题
https://cloud.tencent.com/developer/article/1583402https://developer.aliyun.com/article/1361781?spm=a2c6h.14164896.0.0.192e47c52jyi7n&scm=20140722.S_community@@文章@@1361781._.ID_1361781-RL_elasticsearch-LOC_searchUNDcommunityUNDitem-OR_ser-V_3-P0_0




)
![Electron[2] Electron使用准备](http://pic.xiahunao.cn/Electron[2] Electron使用准备)

)

![Why delete[] array when deepcopying with “=“?](http://pic.xiahunao.cn/Why delete[] array when deepcopying with “=“?)





)



