1 train
1.1 加载training和validation数据
def train(args):logging.basicConfig(filename=os.path.join(args.data, "training.log"), level=logging.INFO)'''设置了日志的基本配置。将日志信息保存到名为 "training.log" 的文件中日志的级别被设置为 INFO,这意味着所有级别为 INFO 及以上的日志消息都会被记录。'''trainsrc = os.path.join(args.data, "train.src")traintrg = os.path.join(args.data, "train.trg")trainmta = os.path.join(args.data, "train.mta")trainData = DataLoader(trainsrc, traintrg, trainmta, args.batch, args.bucketsize)#使用自定义的Dataloader 加载训练数据print("Reading training data...")trainData.load(args.max_num_line)#从指定的源文件、目标文件和元数据文件中加载数据,并按照桶大小进行组织print("Allocation: {}".format(trainData.allocation))print("Percent: {}".format(trainData.p))valsrc = os.path.join(args.data, "val.src")valtrg = os.path.join(args.data, "val.trg")valmta = os.path.join(args.data, "val.mta")#使用自定义的Dataloader 加载测试数据if os.path.isfile(valsrc) and os.path.isfile(valtrg):valData = DataLoader(valsrc, valtrg, valmta, args.batch, args.bucketsize, True)print("Reading validation data...")valData.load()assert valData.size > 0, "Validation data size must be greater than 0"print("Loaded validation data size {}".format(valData.size))else:print("No validation data found, training without validating...")'''首先检查验证数据的文件是否存在。如果存在,则加载验证数据;否则,输出一个消息表示没有找到验证数据,并且将在没有验证的情况下进行训练'''1.2 创建优化器、loss function等
## create criterion, model, optimizerif args.criterion_name == "NLL":#检查args.criterion_name是否为"NLL"criterion = NLLcriterion(args.vocab_size)lossF = lambda o, t: criterion(o, t)如果是,使用NLLcriterion创建一个损失函数。else:assert os.path.isfile(args.knearestvocabs),\"{} does not exist".format(args.knearestvocabs)'''首先,确保args.knearestvocabs指向一个存在的文件。如果不是,则触发断言错误。'''print("Loading vocab distance file {}...".format(args.knearestvocabs))with h5py.File(args.knearestvocabs, "r") as f:V, D = f["V"][...], f["D"][...]V, D = torch.LongTensor(V), torch.FloatTensor(D)'''加载args.knearestvocabs指向的文件内容V矩阵存储每个词汇的k个最近词汇的索引,而D矩阵存储与这些词汇的相应距离'''D = dist2weight(D, args.dist_decay_speed)#将距离矩阵逐行softmaxif args.cuda and torch.cuda.is_available():V, D = V.cuda(), D.cuda()criterion = KLDIVcriterion(args.vocab_size)lossF = lambda o, t: KLDIVloss(o, t, criterion, V, D)'''使用KLDIVcriterion创建一个损失函数,并定义另一个损失函数lossF'''triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2)'''定义一个Triplet loss测量一个锚点与一个正面样本之间的距离相对于一个负面样本的距离'''1.3 创建模型
m0 = EncoderDecoder(args.vocab_size,args.embedding_size,args.hidden_size,args.num_layers,args.dropout,args.bidirectional)#创建EncoderDecoderm1 = nn.Sequential(nn.Linear(args.hidden_size, args.vocab_size),nn.LogSoftmax(dim=1))#线性层,输入维度是args.hidden_size,输出维度是args.vocab_size#接着,这个线性层的输出被送入一个LogSoftmax层,用于归一化输出并取对数if args.cuda and torch.cuda.is_available():print("=> training with GPU")m0.cuda()m1.cuda()criterion.cuda()#m0 = nn.DataParallel(m0, dim=1)else:print("=> training with CPU")#是否放在GPU上训练1.4 定义优化过程
m0_optimizer = torch.optim.Adam(m0.parameters(), lr=args.learning_rate)m1_optimizer = torch.optim.Adam(m1.parameters(), lr=args.learning_rate)#为前面定义的两个模块m0和m1各自创建了一个优化器## load model state and optmizer stateif os.path.isfile(args.checkpoint):print("=> loading checkpoint '{}'".format(args.checkpoint))logging.info("Restore training @ {}".format(time.ctime()))checkpoint = torch.load(args.checkpoint)args.start_iteration = checkpoint["iteration"]best_prec_loss = checkpoint["best_prec_loss"]m0.load_state_dict(checkpoint["m0"])m1.load_state_dict(checkpoint["m1"])m0_optimizer.load_state_dict(checkpoint["m0_optimizer"])m1_optimizer.load_state_dict(checkpoint["m1_optimizer"])else:print("=> no checkpoint found at '{}'".format(args.checkpoint))logging.info("Start training @ {}".format(time.ctime()))best_prec_loss = float('inf')'''首先检查args.checkpoint指定的路径是否存在检查点文件:如果存在,它会加载检查点,然后从中恢复模型m0、m1以及它们的优化器的状态。这对于中断后继续训练非常有用。如果不存在检查点,代码将记录开始训练的时间,并设置best_prec_loss为无穷大,表示还没有最好的损失值。'''
1.5 训练过程
num_iteration = 67000*128 // args.batchprint("Iteration starts at {} ""and will end at {}".format(args.start_iteration, num_iteration-1))#设定总迭代次数## trainingfor iteration in range(args.start_iteration, num_iteration):try:m0_optimizer.zero_grad()m1_optimizer.zero_grad()#在每次迭代开始时,都会清零之前计算的梯度。(pytorch训练三部曲1)## generative lossgendata = trainData.getbatch_generative()#获取一个桶中一个batch的train、target数据#分别将train和val数据pad成相同的长度genloss = genLoss(gendata, m0, m1, lossF, args)'''对于选择的这一个batch的src、target数据计算经过encoder-decoder之后的输出,和ground-truth单元格 最近的 k个单元格的加权距离和'''## discriminative lossdisloss_cross, disloss_inner = 0, 0if args.use_discriminative and iteration % 10 == 0:a, p, n = trainData.getbatch_discriminative_cross()'''获取三个batch的数据,a、p和n[锚点(anchor)、正例(positive)和负例(negative)]'''disloss_cross = disLoss(a, p, n, m0, triplet_loss, args)#锚点(anchor)、正例(positive)和负例(negative)经过encoder之后的hidden state的三元组距离a, p, n = trainData.getbatch_discriminative_inner()'''从同一个初始数据的不同部分产生a(锚点)、p(正例)、和n(负例)'''disloss_inner = disLoss(a, p, n, m0, triplet_loss, args)#锚点(anchor)、正例(positive)和负例(negative)经过encoder之后的hidden state的三元组距离loss = genloss + args.discriminative_w * (disloss_cross + disloss_inner)#总的loss## compute the gradientsloss.backward()#梯度反向传播## clip the gradientsclip_grad_norm_(m0.parameters(), args.max_grad_norm)clip_grad_norm_(m1.parameters(), args.max_grad_norm)#并对模型的梯度进行裁剪,以防止梯度爆炸## one step optimizationm0_optimizer.step()m1_optimizer.step()#使用前面计算的梯度更新模型的参数## average loss for one wordavg_genloss = genloss.item() / gendata.trg.size(0)if iteration % args.print_freq == 0:print("Iteration: {0:}\tGenerative Loss: {1:.3f}\t"\"Discriminative Cross Loss: {2:.3f}\tDiscriminative Inner Loss: {3:.3f}"\.format(iteration, avg_genloss, disloss_cross, disloss_inner))#打印信息if iteration % args.save_freq == 0 and iteration > 0:prec_loss = validate(valData, (m0, m1), lossF, args)if prec_loss < best_prec_loss:best_prec_loss = prec_losslogging.info("Best model with loss {} at iteration {} @ {}"\.format(best_prec_loss, iteration, time.ctime()))is_best = Trueelse:is_best = Falseprint("Saving the model at iteration {} validation loss {}"\.format(iteration, prec_loss))savecheckpoint({"iteration": iteration,"best_prec_loss": best_prec_loss,"m0": m0.state_dict(),"m1": m1.state_dict(),"m0_optimizer": m0_optimizer.state_dict(),"m1_optimizer": m1_optimizer.state_dict()}, is_best, args) #保存最好的modelexcept KeyboardInterrupt:breakt2vec 辅助笔记:data_utils-CSDN博客
2 NLLcriterion
'''
构造负对数似然损失函数(Negative Log Likelihood, y NLL)
'''
def NLLcriterion(vocab_size):weight = torch.ones(vocab_size)#建一个大小为vocab_size的全1张量,用于为每个词汇项赋权重。weight[constants.PAD] = 0'''constants.PAD是指示填充(Padding)标记的索引,这行代码将其权重设置为0这意味着在计算损失时会忽略填充标记。'''criterion = nn.NLLLoss(weight, reduction='sum')'''创建NLL损失函数。其中reduction='sum'表示损失是所有元素的总和'''return criterion注:确保传入NLL损失的输入已经经过了log_softmax,因为NLLLoss期望的输入是对数概率。
2.1 举例
假设词汇表由以下词汇组成
词汇表: ["<PAD>", "你好", "再见", "是", "吗"]
其中,"<PAD>"是用于填充序列的特殊标记。
因此,vocab_size是5,constants.PAD的索引是0。
现在,假设有以下批量预测输出(batch=2),每一行表示这个样本的预测结果(经过了log和softmax之后)
log_probs = [[-0.2, -1.5, -2.3, -3.1, -1.8],[-0.5, -1.2, -0.9, -2.5, -3.0],]
同时目标标签是[1, 2](表示第一个示例的标签是“你好”,第二个是“再见”)
所以
# 创建损失函数
criterion = NLLcriterion(5)# 示例数据
log_probs = torch.tensor([[-0.2, -1.5, -2.3, -3.1, -1.8],[-0.5, -1.2, -0.9, -2.5, -3.0],
])
targets = torch.tensor([1, 2])# 计算损失
loss = criterion(log_probs, targets)
print(loss)
#2.4
#损失 = -(-1.5) - (-0.9) = 1.5 + 0.9 = 2.43 dist2weight
'''
将给定的距离矩阵转换为一个权重矩阵
'''
def dist2weight(D, dist_decay_speed=0.8):D = D.div(100)D = torch.exp(-D * dist_decay_speed)'''使用指数衰减————让距离较小的元素(距离更近的)获得更大的权重,并且让距离较大的元素获得更小的权重'''s = D.sum(dim=1, keepdim=True)D = D / s'''逐行手动softmax'''## The PAD should not contribute to the decoding lossD[constants.PAD, :] = 0.0return D4 KLDIVcriterion
'''
创建KLloss
'''
def KLDIVcriterion(vocab_size):criterion = nn.KLDivLoss(reduction='sum')return criterion5 KLDIVloss
'''
计算 KL 散度损失,但它与通常的直接比较输出和目标之间的损失有所不同。它基于目标索引的 k-最近邻来计算损失
'''
def KLDIVloss(output, target, criterion, V, D):"""output (batch, vocab_size)target (batch,)criterion (nn.KLDIVLoss)V (vocab_size, k) 最近的K个词汇的IDD (vocab_size, k) 最近的K个词汇的距离"""## (batch, k) index in vocab_size dimension## k-nearest neighbors for targetindices = torch.index_select(V, 0, target)'''target的维度也即(seq_len*generator_batch)也就是generator_batch个sequence 每个元素的ground-truth 单元格index_select就把这些单元格作为索引id给提取了出来,得到了一个 (batch, k)generator_batch个sequence 每个元素的最近k个邻居单元格'''## (batch, k) gather along vocab_size dimensionoutputk = torch.gather(output, 1, indices)'''output的维度是 (batch, vocab_size)也即(seq_len*generator_batch, vocab_size)generator_batch个sequence 每个元素在vocab_size个单元格的概率这里只考虑最近的k个邻居单元格的概率,所以使用index_select得到的(seq_len*generator_batch, k)generator_batch个sequence 每个元素的最近k个邻居单元格的概率'''## (batch, k) index in vocab_size dimensiontargetk = torch.index_select(D, 0, target)'''generator_batch个sequence 每个元素的最近k个邻居单元格的距离'''return criterion(outputk, targetk)pytorch 笔记:KLDivLoss-CSDN博客
6 genLoss
def genLoss(gendata, m0, m1, lossF, args):"""One batch lossInput:gendata: a named tuple containsgendata.src (seq_len1, batch): input tensorgendata.lengths (1, batch): lengths of source sequencesgendata.trg (seq_len2, batch): target tensor.m0: map input to output.m1: map the output of EncoderDecoder into the vocabulary space and dolog transform.lossF: loss function.---Output:loss"""input, lengths, target = gendata.src, gendata.lengths, gendata.trgif args.cuda and torch.cuda.is_available():input, lengths, target = input.cuda(), lengths.cuda(), target.cuda()#从gendata中提取数据,并根据是否使用GPU进行调整## (seq_len2, batch, hidden_size)output = m0(input, lengths, target)'''m0是一个encoder-decoderencoder输入inputdecoder将encoder的hidden state和target 作为输入,得到和target通常的一个输出'''batch = output.size(1)loss = 0## we want to decode target in range [BOS+1:EOS]target = target[1:]for o, t in zip(output.split(args.generator_batch),target.split(args.generator_batch)):'''!!!这里我存疑,output的维度是 (seq_len2, batch, hidden_size),target的维度是(seq_len2, batch)那么进行split的时候,是否需要设置dim=1?'''## (seq_len2, generator_batch, hidden_size) =>## (seq_len2*generator_batch, hidden_size)o = o.view(-1, o.size(2))#根据论文作者给的注释,如果第二个维度是generator_batch,那上面的split就应该有dim=1o = m1(o)# (seq_len2*generator_batch, vocab_size)## (seq_len*generator_batch,)t = t.view(-1)loss += lossF(o, t)return loss.div(batch)'''seq_len2* generator_batch 每个元素到他最近的k个单元格的距离*在这个单元格的概率 ,这个概率距离的和'''genData的格式如下
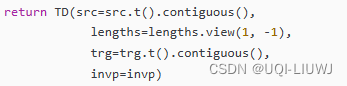
7 disLoss
'''
计算三元组损失
'''
def disLoss(a, p, n, m0, triplet_loss, args):"""a (named tuple): anchor datap (named tuple): positive datan (named tuple): negative data"""a_src, a_lengths, a_invp = a.src, a.lengths, a.invpp_src, p_lengths, p_invp = p.src, p.lengths, p.invpn_src, n_lengths, n_invp = n.src, n.lengths, n.invp#从命名元组中解包数据if args.cuda and torch.cuda.is_available():a_src, a_lengths, a_invp = a_src.cuda(), a_lengths.cuda(), a_invp.cuda()p_src, p_lengths, p_invp = p_src.cuda(), p_lengths.cuda(), p_invp.cuda()n_src, n_lengths, n_invp = n_src.cuda(), n_lengths.cuda(), n_invp.cuda()## (num_layers * num_directions, batch, hidden_size)a_h, _ = m0.encoder(a_src, a_lengths)p_h, _ = m0.encoder(p_src, p_lengths)n_h, _ = m0.encoder(n_src, n_lengths)#从命名元组中解包数据## (num_layers, batch, hidden_size * num_directions)a_h = m0.encoder_hn2decoder_h0(a_h)p_h = m0.encoder_hn2decoder_h0(p_h)n_h = m0.encoder_hn2decoder_h0(n_h)#使用函数 encoder_hn2decoder_h0 来调整每个隐藏状态的形状## take the last layer as representations (batch, hidden_size * num_directions)a_h, p_h, n_h = a_h[-1], p_h[-1], n_h[-1]#使用编码器的最后一个层的输出作为数据的表示return triplet_loss(a_h[a_invp], p_h[p_invp], n_h[n_invp])#使用 triplet_loss 函数计算锚点、正样本和负样本之间的三元组损失8 validate
def validate(valData, model, lossF, args):"""valData (DataLoader)"""m0, m1 = model## switch to evaluation modem0.eval()m1.eval() #在评估之前将模型设置为评估模式,这样可以关闭dropoutnum_iteration = valData.size // args.batchif valData.size % args.batch > 0: num_iteration += 1#根据验证数据集的大小和批量大小计算需要的迭代次数。total_genloss = 0for iteration in range(num_iteration):gendata = valData.getbatch_generative()#获取一个batch的train、target数据#分别将train和val数据pad成相同的长度with torch.no_grad():genloss = genLoss(gendata, m0, m1, lossF, args)'''对于选择的这一个batch的src、target数据计算经过encoder-decoder之后的输出,和ground-truth单元格 最近的 k个单元格的加权距离和'''total_genloss += genloss.item() * gendata.trg.size(1)## switch back to training modem0.train()m1.train()return total_genloss / valData.size9 保存模型
def savecheckpoint(state, is_best, args):torch.save(state, args.checkpoint)if is_best:shutil.copyfile(args.checkpoint, os.path.join(args.data, 'best_model.pt'))'''如果is_best为True,意味着当前的模型是最好的模型,那么它会使用shutil.copyfile函数把args.checkpoint文件复制到一个新的路径这个路径由args.data文件夹和文件名'best_model.pt'组成。这样做的目的是为了保留一个单独的最好模型的副本'''11.0.0激活版)

)






工程师》课程简介(二)丨IDCF)







)

