Kafka 最初是为海量日志处理而构建的。它保留消息直到过期,并让消费者按照自己的节奏提取消息。与它的前辈不同,Kafka 不仅仅是一个消息队列,它还是一个适用于各种情况的开源事件流平台。
1. 日志处理与分析
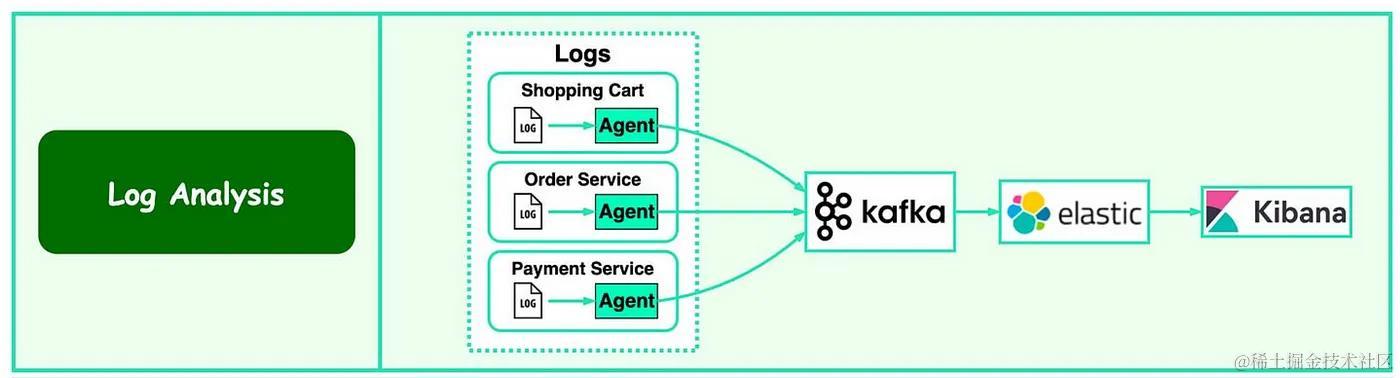
- 下图显示了典型的 ELK(Elastic-Logstash-Kibana)堆栈。Kafka 有效地从每个实例收集日志流。
- ElasticSearch 使用来自 Kafka 的日志并为其建立索引。Kibana 在 ElasticSearch 之上提供了搜索和可视化 UI。
2. 推荐中的数据流
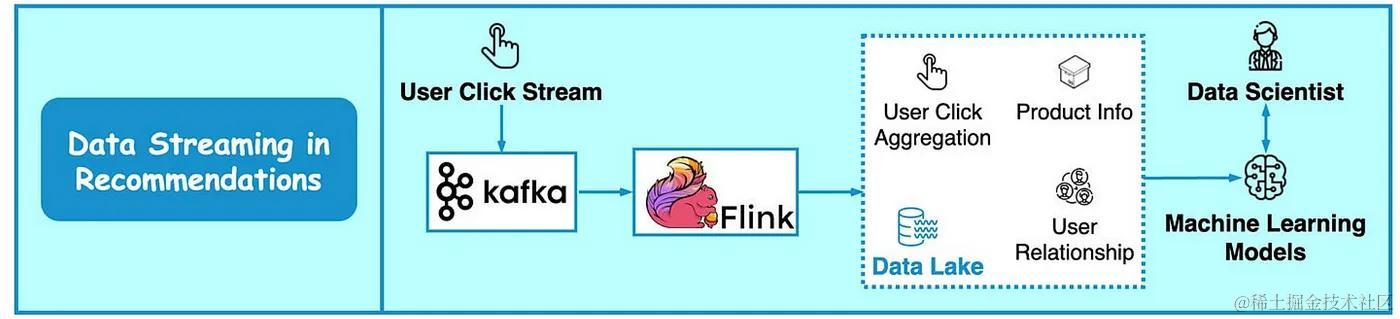
- 大型电子商务网站使用过去的行为和相似的用户来计算产品推荐。
- 下图展示了推荐系统的工作原理。Kafka 传输原始点击流数据,Flink 对其进行处理,模型训练则使用来自数据湖的聚合数据。
- 这使得能够持续改进每个用户的推荐的相关性。Kafka 的另一个重要用例是实时点击流分析。
3. 系统监控与报警
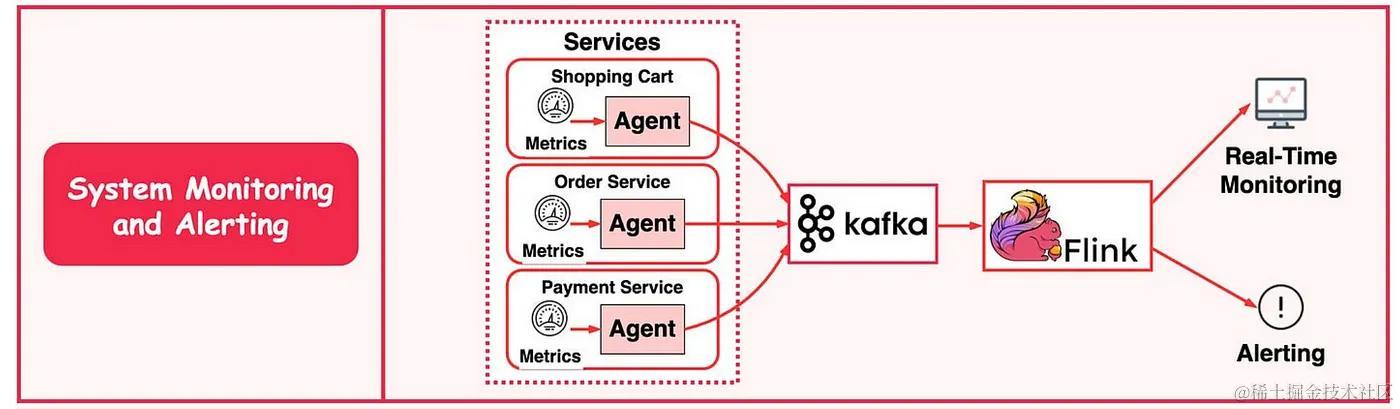
- 与日志分析系统类似,我们需要收集系统指标以进行监控和故障排除。
- 区别在于指标是结构化数据,而日志是非结构化文本。指标数据发送到 Kafka 并在 Flink 中聚合。聚合数据由实时监控仪表板和警报系统使用。
4. CDC(变更数据捕获)
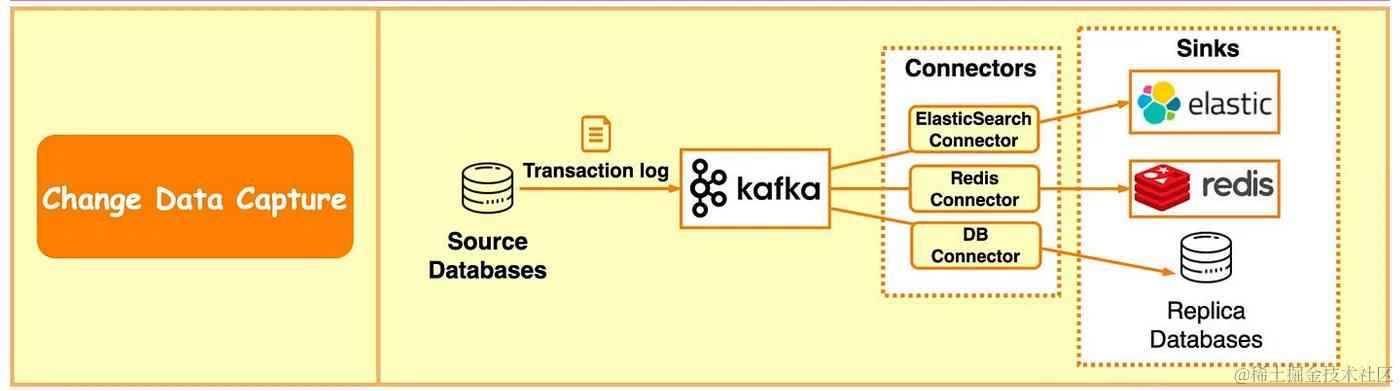
- 更改数据捕获 (CDC) 将数据库更改流式传输到其他系统以进行复制或缓存/索引更新。
- Kafka 还是构建数据管道的绝佳工具,这意味着您可以使用它从各种来源获取数据、应用处理规则并将数据存储在仓库、数据湖或数据网格中。
- 例如,在下图中,事务日志发送到 Kafka 并由 ElasticSearch、Redis 和辅助数据库摄取。
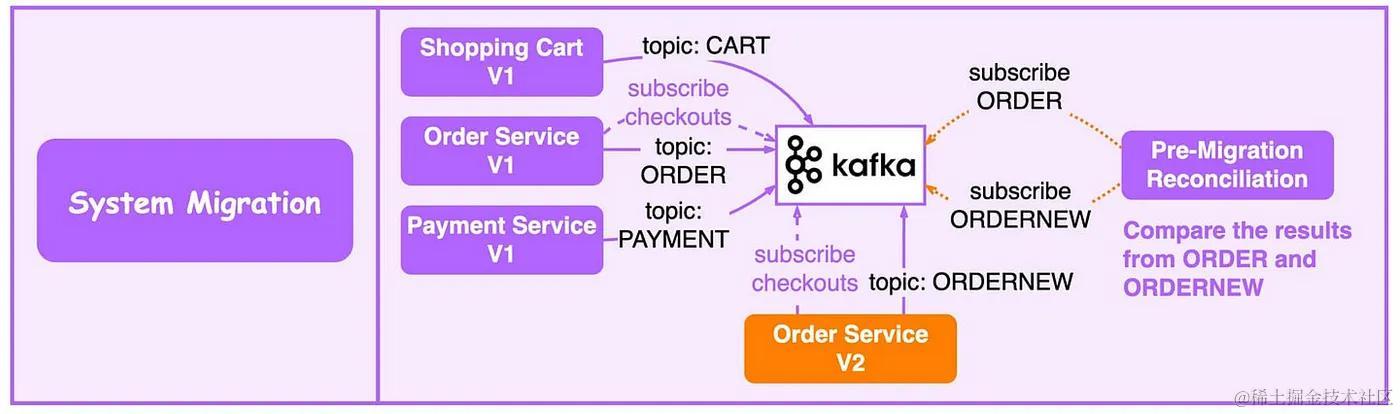
5. 系统迁移
- 升级遗留服务具有挑战性——旧的语言、复杂的逻辑和缺乏测试。我们可以通过利用消息传递中间件来降低风险。
- 在下图中,为了升级下图中的订单服务,我们更新旧的订单服务以使用来自 Kafka 的输入并将结果写入 ORDER 主题。新订单服务使用相同的输入并将结果写入 ORDERNEW 主题。
- 调节服务比较 ORDER 和 ORDERNEW。如果它们相同,则新服务通过测试。
6. 事件溯源
- 事件溯源就是捕获一系列事件中状态的变化。通常使用 Kafka 作为主要事件存储。如果发生任何故障、回滚或需要重建状态,您可以随时重新应用 Kafka 中的事件。
7. 消息传递
- Kafka 最好和最常见的用例之一是作为消息队列。Kafka 为您提供了一个可靠且可扩展的消息队列,可以处理大量数据。
- 我们可以将您的消息组织成“主题”,这意味着您将每条消息发布到一个特定主题,而另一方面,消费者将订阅一个或多个主题并消费其中的消息。
- 微服务之间解耦通信的最大优点是,您可以随时向这些事件添加新服务,而无需增加系统的复杂性或不必更改任何源代码。
8. 提交日志
- Kafka 可以充当分布式系统的一种外部提交日志。日志有助于在节点之间复制数据,并充当故障节点恢复数据的重新同步机制。
- Kafka 中的日志压缩功能有助于支持这种用法。






)



Storage Relationship Strut)



)




)