首先明确一点,绝大多数情况下,是标准库中的容器使用allocator。因为容器需要频繁的申请和释放内存。
一、容器使用allocator
典型的例子:
vector<int , allocator<int>> a;
但是为什么我们通常的定义vector变量的方法是:
vector<int> a;
这就要看看stl里面vector的定义了:
template<typename _Tp, typename _Alloc = std::allocator<_Tp> >class vector : protected _Vector_base<_Tp, _Alloc>
显然,第二个参数是默认参数。如果我们什么也不输入,则会传入一个实例化的类模板allocator。实例化的类型与容器元素类型一致。如果你故意传入一个类型不一致的allocator,编译可以通过,但是这种做法等于搬起石头砸自己的脚。
二、为什么容器需要allocator?
容器在初始化、扩容、新增元素等情况下需要申请内存,删除元素需要释放内存。allocator可以帮助我们做这个事情。这就有一个问题,为什么 不直接用malloc和free函数?
其实,VC和BC版本的编译器,allocator就是malloc和free套了个壳子,加入了一些日志,增加了一些错误处理而已。但是存在两个问题:(1)多次malloc有cookie浪费;(2)频繁malloc和free比较耗时。
在GC版本的编译器情况大不一样了。G4.9版本的编译器加入了内存池的思想,可以有效解决上面的两个问题。
在侯捷老师的课中,有这么一句话:“频繁的malloc和free会产生大量的cookie浪费,如果你有100万个元素,就会浪费100万个cookie。”这句话其实不太严谨。当然侯捷老师举的例子是list,list如果想放置100万个元素,自然要申请100万个空间,在VC版本的分配器之下自然产生100万个cookie。但是如果是vector,情况就不一样了,可能一次就malloc了100万的空间,cookie就只有一个。
三、VC、BC版本的分配器
没什么好说的,就是套了个malloc和free。
比如说
vector<int> a(100);
那么在初始化的时候,会调用malloc函数,申请一块4*100字节的内存。
四、G4.9版本的分配器
分为两级分配器:
(1)一级分配器,就是原装的malloc和free。没什么好说的。当申请内存的大小超过128字节的时候,调用一级分配器。
(2)二级分配器,利用了线程池的思想,适合分配小块内存。
结构如下:
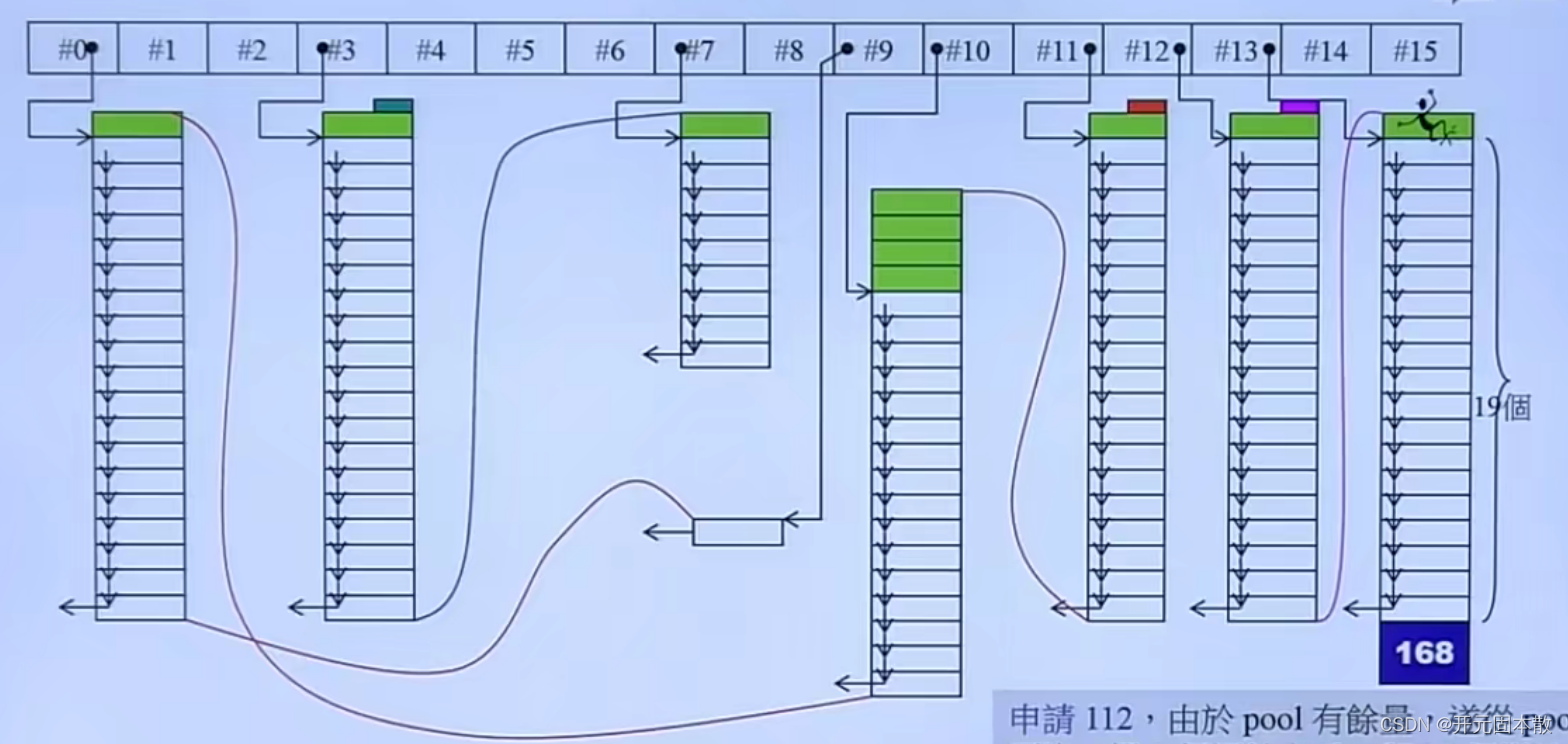
是一个长度为16的指针数组,下拉链表。每个链表都是一个freelist,就是内存池。关于freelist和内存池的概念,可以参考前三篇博客。
长度16是为了适配不同的内存大小。内存块大小都是8的倍数,从8到128。
假如要申请一块大小是6字节的内存,那么上取8的倍数,取8字节。到数组第一位找内存块。
申请内存的步骤为:
(1)申请内存大小上取8的倍数,找到对应的freeList拿内存块。
(2)如果freeList已经满了,或者之前没申请过。那么malloc大块内存,按照这个位置上的内存大小切片,拉链表(使用嵌入式指针)。
释放步骤参考前三篇博客。
有个注意点:
一个进程中,只有一个二级分配器数据对象。因为数据结构、分配函数都是静态的。所以在这个进程中,vector和list,用的都是这一个分配器数据对象。
)






![P1966 [NOIP2013 提高组] 火柴排队](http://pic.xiahunao.cn/P1966 [NOIP2013 提高组] 火柴排队)

最大公因数等于 K 的子数组数目)
图解递归)
--wordcount案例)
:定义损失函数与优化器)



——OpenCV中绘图功能)


