本章概要
- 正则表达式
- 基础
- 创建正则表达式
- 量词
- CharSequence
- Pattern 和 Matcher
- finde()
- 组(Groups)
- start() 和 end()
- Pattern 标记
- split()
- 替换操作
- reset()
- 正则表达式与 Java I/0
正则表达式
很久之前,_正则表达式_就已经整合到标准 Unix 工具集之中,例如 sed、awk 和程序语言之中了,如 Python 和Perl(有些人认为正是正则表达式促成了 Perl 的成功)。而在 Java 中,字符串操作还主要集中于String、StringBuffer 和 StringTokenizer 类。与正则表达式相比较,它们只能提供相当简单的功能。
正则表达式是一种强大而灵活的文本处理工具。使用正则表达式,我们能够以编程的方式,构造复杂的文本模式,并对输入 String 进行搜索。一旦找到了匹配这些模式的部分,你就能随心所欲地对它们进行处理。初学正则表达式时,其语法是一个难点,但它确实是一种简洁、动态的语言。正则表达式提供了一种完全通用的方式,能够解决各种 String 处理相关的问题:匹配、选择、编辑以及验证。
基础
一般来说,正则表达式就是以某种方式来描述字符串,因此你可以说:“如果一个字符串含有这些东西,那么它就是我正在找的东西。”例如,要找一个数字,它可能有一个负号在最前面,那你就写一个负号加上一个问号,就像这样:
-?
要描述一个整数,你可以说它有一位或多位阿拉伯数字。在正则表达式中,用 \d 表示一位数字。如果在其他语言中使用过正则表达式,那你可能就能发现 Java 对反斜线 \ 的不同处理方式。在其他语言中,\\ 表示“我想要在正则表达式中插入一个普通的(字面上的)反斜线,请不要给它任何特殊的意义。”而在Java中,\\ 的意思是“我要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。”例如,如果你想表示一位数字,那么正则表达式应该是 \\d。如果你想插入一个普通的反斜线,应该这样写 \\\。不过换行符和制表符之类的东西只需要使用单反斜线:\n\t。
要表示“一个或多个之前的表达式”,应该使用 +。所以,如果要表示“可能有一个负号,后面跟着一位或多位数字”,可以这样:
-?\\d+
应用正则表达式最简单的途径,就是利用 String 类内建的功能。例如,你可以检查一个 String 是否匹配如上所述的正则表达式:
public class IntegerMatch {public static void main(String[] args) {System.out.println("-1234".matches("-?\\d+"));System.out.println("5678".matches("-?\\d+"));System.out.println("+911".matches("-?\\d+"));System.out.println("+911".matches("(-|\\+)?\\d+"));}
}
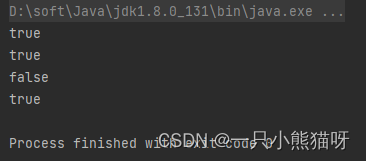
前两个字符串都满足对应的正则表达式,匹配成功。第三个字符串以 + 开头,这也是一个合法的符号,但与对应的正则表达式却不匹配。因此,我们的正则表达式应该描述为:“可能以一个加号或减号开头”。在正则表达式中,用括号将表达式进行分组,用竖线 | 表示或操作。也就是:
(-|\\+)?
这个正则表达式表示字符串的起始字符可能是一个 - 或 +,或者二者都没有(因为后面跟着 ? 修饰符)。因为字符 + 在正则表达式中有特殊的意义,所以必须使用 \\ 将其转义,使之成为表达式中的一个普通字符。
String类还自带了一个非常有用的正则表达式工具——split() 方法,其功能是“将字符串从正则表达式匹配的地方切开。”
import java.util.Arrays;public class Splitting {public static String knights ="Then, when you have found the shrubbery, " +"you must cut down the mightiest tree in the " +"forest...with... a herring!";public static void split(String regex) {System.out.println(Arrays.toString(knights.split(regex)));}public static void main(String[] args) {split(" "); // Doesn't have to contain regex charssplit("\\W+"); // Non-word characterssplit("n\\W+"); // 'n' followed by non-words}
}

首先看第一个语句,注意这里用的是普通的字符作为正则表达式,其中并不包含任何特殊字符。因此第一个 split() 只是按空格来划分字符串。
第二个和第三个 split() 都用到了 \\W,它的意思是一个非单词字符(如果 W 小写,\\w,则表示一个单词字符)。通过第二个例子可以看到,它将标点字符删除了。第三个 split() 表示“字母 n 后面跟着一个或多个非单词字符。”可以看到,在原始字符串中,与正则表达式匹配的部分,在最终结果中都不存在了。
String.split() 还有一个重载的版本,它允许你限制字符串分割的次数。
用正则表达式进行替换操作时,你可以只替换第一处匹配,也可以替换所有的匹配:
public class Replacing {static String s = Splitting.knights;public static void main(String[] args) {System.out.println(s.replaceFirst("f\\w+", "located"));System.out.println(s.replaceAll("shrubbery|tree|herring", "banana"));}
}

第一个表达式要匹配的是,以字母 f 开头,后面跟一个或多个字母(注意这里的 w 是小写的)。并且只替换掉第一个匹配的部分,所以 “found” 被替换成 “located”。
第二个表达式要匹配的是三个单词中的任意一个,因为它们以竖线分割表示“或”,并且替换所有匹配的部分。
稍后你会看到,String 之外的正则表达式还有更强大的替换工具,例如,可以通过方法调用执行替换。而且,如果正则表达式不是只使用一次的话,非 String 对象的正则表达式明显具备更佳的性能。
创建正则表达式
我们首先从正则表达式可能存在的构造集中选取一个很有用的子集,以此开始学习正则表达式。正则表达式的完整构造子列表,请参考JDK文档 java.util.regex 包中的 Pattern类。
| 表达式 | 含义 |
|---|---|
B | 指定字符B |
\xhh | 十六进制值为0xhh的字符 |
\uhhhh | 十六进制表现为0xhhhh的Unicode字符 |
\t | 制表符Tab |
\n | 换行符 |
\r | 回车 |
\f | 换页 |
\e | 转义(Escape) |
当你学会了使用字符类(character classes)之后,正则表达式的威力才能真正显现出来。以下是一些创建字符类的典型方式,以及一些预定义的类:
| 表达式 | 含义 |
|---|---|
. | 任意字符 |
[abc] | 包含a、b或c的任何字符(和`a |
[^abc] | 除a、b和c之外的任何字符(否定) |
[a-zA-Z] | 从a到z或从A到Z的任何字符(范围) |
[abc[hij]] | a、b、c、h、i、j中的任意字符(与`a |
[a-z&&[hij]] | 任意h、i或j(交) |
\s | 空白符(空格、tab、换行、换页、回车) |
\S | 非空白符([^\s]) |
\d | 数字([0-9]) |
\D | 非数字([^0-9]) |
\w | 词字符([a-zA-Z_0-9]) |
\W | 非词字符([^\w]) |
这里只列出了部分常用的表达式,你应该将JDK文档中 java.util.regex.Pattern 那一页加入浏览器书签中,以便在需要的时候方便查询。
| 逻辑操作符 | 含义 |
|---|---|
XY | Y跟在X后面 |
XY | X或Y |
(X) | 捕获组(capturing group)。可以在表达式中用\i引用第i个捕获组 |
下面是不同的边界匹配符:
| 边界匹配符 | 含义 |
|---|---|
^ | 一行的开始 |
$ | 一行的结束 |
\b | 词的边界 |
\B | 非词的边界 |
\G | 前一个匹配的结束 |
作为演示,下面的每一个正则表达式都能成功匹配字符序列“Rudolph”:
public class Rudolph {public static void main(String[] args) {for (String pattern : new String[]{"Rudolph","[rR]udolph","[rR][aeiou][a-z]ol.*","R.*"}) {System.out.println("Rudolph".matches(pattern));}}
}
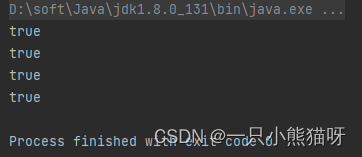
我们的目的并不是编写最难理解的正则表达式,而是尽量编写能够完成任务的、最简单以及最必要的正则表达式。一旦真正开始使用正则表达式了,你就会发现,在编写新的表达式之前,你通常会参考代码中已经用到的正则表达式。
量词
量词描述了一个模式捕获输入文本的方式:
- 贪婪型:
量词总是贪婪的,除非有其他的选项被设置。贪婪表达式会为所有可能的模式发现尽可能多的匹配。导致此问题的一个典型理由就是假定我们的模式仅能匹配第一个可能的字符组,如果它是贪婪的,那么它就会继续往下匹配。 - 勉强型:
用问号来指定,这个量词匹配满足模式所需的最少字符数。因此也被称作懒惰的、最少匹配的、非贪婪的或不贪婪的。 - 占有型:
目前,这种类型的量词只有在 Java 语言中才可用(在其他语言中不可用),并且也更高级,因此我们大概不会立刻用到它。当正则表达式被应用于String时,它会产生相当多的状态,以便在匹配失败时可以回溯。而“占有的”量词并不保存这些中间状态,因此它们可以防止回溯。它们常常用于防止正则表达式失控,因此可以使正则表达式执行起来更高效。
| 贪婪型 | 勉强型 | 占有型 | 如何匹配 |
|---|---|---|---|
X? | X?? | X?+ | 一个或零个X |
X* | X*? | X*+ | 零个或多个X |
X+ | X+? | X++ | 一个或多个X |
X{n} | X{n}? | X{n}+ | 恰好n次X |
X{n,} | X{n,}? | X{n,}+ | 至少n次X |
X{n,m} | X{n,m}? | X{n,m}+ | X至少n次,但不超过m次 |
应该非常清楚地意识到,表达式 X 通常必须要用圆括号括起来,以便它能够按照我们期望的效果去执行。例如:
abc+
看起来它似乎应该匹配1个或多个abc序列,如果我们把它应用于输入字符串abcabcabc,则实际上会获得3个匹配。然而,这个表达式实际上表示的是:匹配ab,后面跟随1个或多个c。要表明匹配1个或多个完整的字符串abc,我们必须这样表示:
(abc)+
你会发现,在使用正则表达式时很容易混淆,因为它是一种在 Java 之上的新语言。
CharSequence
接口 CharSequence 从 CharBuffer、String、StringBuffer、StringBuilder 类中抽象出了字符序列的一般化定义:
interface CharSequence {char charAt(int i); int length();CharSequence subSequence(int start, int end);@OverrideString toString();
}
因此,这些类都实现了该接口。多数正则表达式操作都接受 CharSequence 类型参数。
Pattern 和 Matcher
通常,比起功能有限的 String 类,我们更愿意构造功能强大的正则表达式对象。只需导入 java.util.regex包,然后用 static Pattern.compile() 方法来编译你的正则表达式即可。它会根据你的 String 类型的正则表达式生成一个 Pattern 对象。接下来,把你想要检索的字符串传入 Pattern 对象的 matcher() 方法。matcher() 方法会生成一个 Matcher 对象,它有很多功能可用(可以参考 java.util.regext.Matcher 的 JDK 文档)。例如,它的 replaceAll() 方法能将所有匹配的部分都替换成你传入的参数。
作为第一个示例,下面的类可以用来测试正则表达式,看看它们能否匹配一个输入字符串。第一个控制台参数是将要用来搜索匹配的输入字符串,后面的一个或多个参数都是正则表达式,它们将被用来在输入的第一个字符串中查找匹配。在Unix/Linux上,命令行中的正则表达式必须用引号括起来。这个程序在测试正则表达式时很有用,特别是当你想验证它们是否具备你所期待的匹配功能的时候。
import java.util.regex.*;public class TestRegularExpression {public static void main(String[] args) {if (args.length < 2) {System.out.println("Usage:\njava TestRegularExpression " +"characterSequence regularExpression+");System.exit(0);}System.out.println("Input: \"" + args[0] + "\"");for (String arg : args) {System.out.println("Regular expression: \"" + arg + "\"");Pattern p = Pattern.compile(arg);Matcher m = p.matcher(args[0]);while (m.find()) {System.out.println("Match \"" + m.group() + "\" at positions " +m.start() + "-" + (m.end() - 1));}}}
}
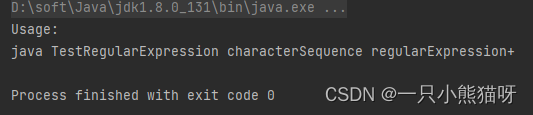
还可以在控制台参数中加入“(abc){2,}”,看看执行结果。
Pattern 对象表示编译后的正则表达式。从这个例子可以看到,我们使用已编译的 Pattern 对象上的 matcher() 方法,加上一个输入字符串,从而共同构造了一个 Matcher 对象。同时,Pattern 类还提供了一个static方法:
static boolean matches(String regex, CharSequence input)
该方法用以检查 regex 是否匹配整个 CharSequence 类型的 input 参数。编译后的 Pattern 对象还提供了 split() 方法,它从匹配了 regex 的地方分割输入字符串,返回分割后的子字符串 String 数组。
通过调用 Pattern.matcher() 方法,并传入一个字符串参数,我们得到了一个 Matcher 对象。使用 Matcher 上的方法,我们将能够判断各种不同类型的匹配是否成功:
boolean matches()
boolean lookingAt()
boolean find()
boolean find(int start)
其中的 matches() 方法用来判断整个输入字符串是否匹配正则表达式模式,而 lookingAt() 则用来判断该字符串(不必是整个字符串)的起始部分是否能够匹配模式。
find()
Matcher.find() 方法可用来在 CharSequence 中查找多个匹配。例如:
import java.util.regex.*;public class Finding {public static void main(String[] args) {Matcher m = Pattern.compile("\\w+").matcher("Evening is full of the linnet's wings");while (m.find()) {System.out.print(m.group() + " ");}System.out.println();int i = 0;while (m.find(i)) {System.out.print(m.group() + " ");i++;}}
}

模式 \\w+ 将字符串划分为词。find() 方法像迭代器那样向前遍历输入字符串。而第二个重载的 find() 接收一个整型参数,该整数表示字符串中字符的位置,并以其作为搜索的起点。从结果可以看出,后一个版本的 find() 方法能够根据其参数的值,不断重新设定搜索的起始位置。
组(Groups)
组是用括号划分的正则表达式,可以根据组的编号来引用某个组。组号为 0 表示整个表达式,组号 1 表示被第一对括号括起来的组,以此类推。因此,下面这个表达式,
A(B(C))D
中有三个组:组 0 是 ABCD,组 1 是 BC,组 2 是 C。
Matcher 对象提供了一系列方法,用以获取与组相关的信息:
public int groupCount()返回该匹配器的模式中的分组数目,组 0 不包括在内。public String group()返回前一次匹配操作(例如find())的第 0 组(整个匹配)。public String group(int i)返回前一次匹配操作期间指定的组号,如果匹配成功,但是指定的组没有匹配输入字符串的任何部分,则将返回null。public int start(int group)返回在前一次匹配操作中寻找到的组的起始索引。public int end(int group)返回在前一次匹配操作中寻找到的组的最后一个字符索引加一的值。
下面是正则表达式组的例子:
import java.util.regex.*;public class Groups {public static final String POEM ="Twas brillig, and the slithy toves\n" +"Did gyre and gimble in the wabe.\n" +"All mimsy were the borogoves,\n" +"And the mome raths outgrabe.\n\n" +"Beware the Jabberwock, my son,\n" +"The jaws that bite, the claws that catch.\n" +"Beware the Jubjub bird, and shun\n" +"The frumious Bandersnatch.";public static void main(String[] args) {Matcher m = Pattern.compile("(?m)(\\S+)\\s+((\\S+)\\s+(\\S+))$").matcher(POEM);while (m.find()) {for (int j = 0; j <= m.groupCount(); j++) {System.out.print("[" + m.group(j) + "]");}System.out.println();}}
}
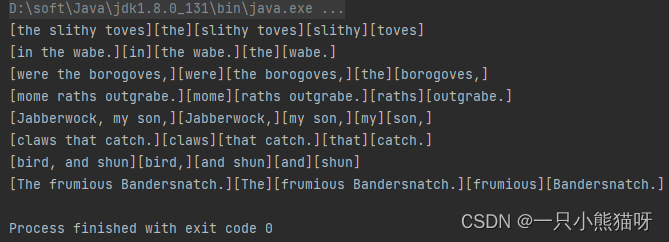
这首诗来自于 Lewis Carroll 所写的 Through the Looking Glass 中的 “Jabberwocky”。可以看到这个正则表达式模式有许多圆括号分组,由任意数目的非空白符(\\S+)及随后的任意数目的空白符(\\s+)所组成。目的是捕获每行的最后3个词,每行最后以 \$ 结束。不过,在正常情况下是将 \$ 与整个输入序列的末端相匹配。所以我们一定要显式地告知正则表达式注意输入序列中的换行符。这可以由序列开头的模式标记 (?m) 来完成(模式标记马上就会介绍)。
start() 和 end()
在匹配操作成功之后,start() 返回先前匹配的起始位置的索引,而 end() 返回所匹配的最后字符的索引加一的值。匹配操作失败之后(或先于一个正在进行的匹配操作去尝试)调用 start() 或 end() 将会产生 IllegalStateException。下面的示例还同时展示了 matches() 和 lookingAt() 的用法 :
import java.util.regex.*;public class StartEnd {public static String input ="As long as there is injustice, whenever a\n" +"Targathian baby cries out, wherever a distress\n" +"signal sounds among the stars " +"... We'll be there.\n" +"This fine ship, and this fine crew ...\n" +"Never give up! Never surrender!";private static class Display {private boolean regexPrinted = false;private String regex;Display(String regex) {this.regex = regex;}void display(String message) {if (!regexPrinted) {System.out.println(regex);regexPrinted = true;}System.out.println(message);}}static void examine(String s, String regex) {Display d = new Display(regex);Pattern p = Pattern.compile(regex);Matcher m = p.matcher(s);while (m.find()) {d.display("find() '" + m.group() +"' start = " + m.start() + " end = " + m.end());}if (m.lookingAt()) // No reset() necessary{d.display("lookingAt() start = "+ m.start() + " end = " + m.end());}if (m.matches()) // No reset() necessary{d.display("matches() start = "+ m.start() + " end = " + m.end());}}public static void main(String[] args) {for (String in : input.split("\n")) {System.out.println("input : " + in);for (String regex : new String[]{"\\w*ere\\w*","\\w*ever", "T\\w+", "Never.*?!"}) {examine(in, regex);}}}
}
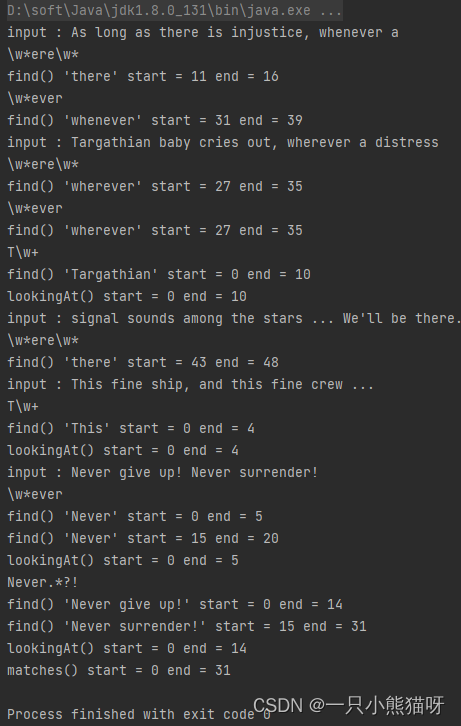
注意,find() 可以在输入的任意位置定位正则表达式,而 lookingAt() 和 matches() 只有在正则表达式与输入的最开始处就开始匹配时才会成功。matches() 只有在整个输入都匹配正则表达式时才会成功,而 lookingAt() 只要输入的第一部分匹配就会成功。
Pattern 标记
Pattern 类的 compile() 方法还有另一个版本,它接受一个标记参数,以调整匹配行为:
Pattern Pattern.compile(String regex, int flag)
其中的 flag 来自以下 Pattern 类中的常量
| 编译标记 | 效果 |
|---|---|
Pattern.CANON_EQ | 当且仅当两个字符的完全规范分解相匹配时,才认为它们是匹配的。例如,如果我们指定这个标记,表达式\u003F就会匹配字符串?。默认情况下,匹配不考虑规范的等价性 |
Pattern.CASE_INSENSITIVE(?i) | 默认情况下,大小写不敏感的匹配假定只有US-ASCII字符集中的字符才能进行。这个标记允许模式匹配不考虑大小写(大写或小写)。通过指定UNICODE_CASE标记及结合此标记。基于Unicode的大小写不敏感的匹配就可以开启了 |
Pattern.COMMENTS(?x) | 在这种模式下,空格符将被忽略掉,并且以#开始直到行末的注释也会被忽略掉。通过嵌入的标记表达式也可以开启Unix的行模式 |
Pattern.DOTALL(?s) | 在dotall模式下,表达式.匹配所有字符,包括行终止符。默认情况下,.不会匹配行终止符 |
Pattern.MULTILINE(?m) | 在多行模式下,表达式^和$分别匹配一行的开始和结束。^还匹配输入字符串的开始,而$还匹配输入字符串的结尾。默认情况下,这些表达式仅匹配输入的完整字符串的开始和结束 |
Pattern.UNICODE_CASE(?u) | 当指定这个标记,并且开启CASE_INSENSITIVE时,大小写不敏感的匹配将按照与Unicode标准相一致的方式进行。默认情况下,大小写不敏感的匹配假定只能在US-ASCII字符集中的字符才能进行 |
Pattern.UNIX_LINES(?d) | 在这种模式下,在.、^和$的行为中,只识别行终止符\n |
在这些标记中,Pattern.CASE_INSENSITIVE、Pattern.MULTILINE 以及 Pattern.COMMENTS(对声明或文档有用)特别有用。请注意,你可以直接在正则表达式中使用其中的大多数标记,只需要将上表中括号括起来的字符插入到正则表达式中,你希望它起作用的位置即可。
你还可以通过“或”(|)操作符组合多个标记的功能:
import java.util.regex.*;public class ReFlags {public static void main(String[] args) {Pattern p = Pattern.compile("^java",Pattern.CASE_INSENSITIVE | Pattern.MULTILINE);Matcher m = p.matcher("java has regex\nJava has regex\n" +"JAVA has pretty good regular expressions\n" +"Regular expressions are in Java");while (m.find()) {System.out.println(m.group());}}
}
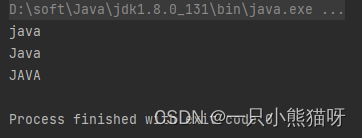
在这个例子中,我们创建了一个模式,它将匹配所有以“java”、“Java”和“JAVA”等开头的行,并且是在设置了多行标记的状态下,对每一行(从字符序列的第一个字符开始,至每一个行终止符)都进行匹配。注意,group() 方法只返回已匹配的部分。
split()
split()方法将输入 String 断开成 String 对象数组,断开边界由正则表达式确定:
String[] split(CharSequence input)
String[] split(CharSequence input, int limit)
这是一个快速而方便的方法,可以按照通用边界断开输入文本:
import java.util.regex.*;
import java.util.*;public class SplitDemo {public static void main(String[] args) {String input = "This!!unusual use!!of exclamation!!points";System.out.println(Arrays.toString(Pattern.compile("!!").split(input)));// Only do the first three: System.out.println(Arrays.toString(Pattern.compile("!!").split(input, 3)));}
}
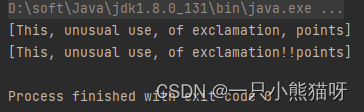
第二种形式的 split() 方法可以限制将输入分割成字符串的数量。
替换操作
正则表达式在进行文本替换时特别方便,它提供了许多方法:
replaceFirst(String replacement)以参数字符串replacement替换掉第一个匹配成功的部分。replaceAll(String replacement)以参数字符串replacement替换所有匹配成功的部分。appendReplacement(StringBuffer sbuf, String replacement)执行渐进式的替换,而不是像replaceFirst()和replaceAll()那样只替换第一个匹配或全部匹配。这是一个非常重要的方法。它允许你调用其他方法来生成或处理replacement(replaceFirst()和replaceAll()则只能使用一个固定的字符串),使你能够以编程的方式将目标分割成组,从而具备更强大的替换功能。appendTail(StringBuffer sbuf)在执行了一次或多次appendReplacement()之后,调用此方法可以将输入字符串余下的部分复制到sbuf中。
下面的程序演示了如何使用这些替换方法。开头部分注释掉的文本,就是正则表达式要处理的输入字符串:
import java.util.regex.*;
import java.nio.file.*;
import java.util.stream.*;/*! Here's a block of text to use as input to the regular expression matcher. Note that we first extract the block of text by looking for the special delimiters, then process the extracted block. !*/public class TheReplacements {public static void main(String[] args) throws Exception {String s = Files.lines(Paths.get("D:\\onJava\\test\\src\\main\\java\\com\\example\\test\\TheReplacements.java")).collect(Collectors.joining("\n"));// Match specially commented block of text above: Matcher mInput = Pattern.compile("/\\*!(.*)!\\*/", Pattern.DOTALL).matcher(s);if (mInput.find()) {s = mInput.group(1); // Captured by parentheses}// Replace two or more spaces with a single space: s = s.replaceAll(" {2,}", " ");// Replace 1+ spaces at the beginning of each // line with no spaces. Must enable MULTILINE mode: s = s.replaceAll("(?m)^ +", "");System.out.println(s);s = s.replaceFirst("[aeiou]", "(VOWEL1)");StringBuffer sbuf = new StringBuffer();Pattern p = Pattern.compile("[aeiou]");Matcher m = p.matcher(s);// Process the find information as you // perform the replacements: while (m.find()) {m.appendReplacement(sbuf, m.group().toUpperCase());}// Put in the remainder of the text: m.appendTail(sbuf);System.out.println(sbuf);}
}
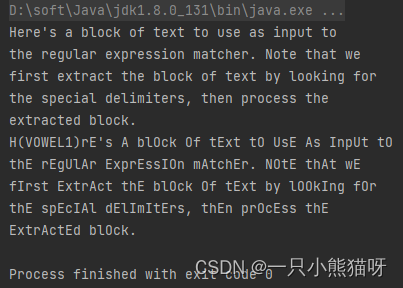
此处使用上一章介绍过的 Files 类打开并读入文件。Files.lines() 返回一个 Stream 对象,包含读入的所有行,Collectors.joining() 在每一行的结尾追加参数字符序列,最终拼接成一个 String 对象。
mInput 匹配 /*! 和 !*/ 之间的所有文字(注意分组的括号)。接下来,将存在两个或两个以上空格的地方,缩减为一个空格,并且删除每行开头部分的所有空格(为了使每一行都达到这个效果,而不仅仅是删除文本开头部分的空格,这里特意开启了多行模式)。
这两个替换操作所使用的的 replaceAll() 是 String 对象自带的方法,在这里,使用此方法更方便。注意,因为这两个替换操作都只使用了一次 replaceAll(),所以,与其编译为 Pattern,不如直接使用 String 的 replaceAll() 方法,而且开销也更小些。
replaceFirst() 只对找到的第一个匹配进行替换。此外,replaceFirst() 和 replaceAll() 方法用来替换的只是普通字符串,所以,如果想对这些替换字符串进行某些特殊处理,这两个方法时无法胜任的。如果你想要那么做,就应该使用 appendReplacement() 方法。该方法允许你在执行替换的过程中,操作用来替换的字符串。在这个例子中,先构造了 sbuf 用来保存最终结果,然后用 group() 选择一个组,并对其进行处理,将正则表达式找到的元音字母替换成大些字母。
一般情况下,你应该遍历执行所有的替换操作,然后再调用 appendTail() 方法,但是,如果你想模拟 replaceFirst()(或替换n次)的行为,那就只需要执行一次替换,然后调用 appendTail() 方法,将剩余未处理的部分存入 sbuf 即可。
同时,appendReplacement() 方法还允许你通过 \$g 直接找到匹配的某个组,这里的 g 就是组号。然而,它只能应付一些简单的处理,无法实现类似前面这个例子中的功能。
reset()
通过 reset() 方法,可以将现有的 Matcher 对象应用于一个新的字符序列:
import java.util.regex.*;public class Resetting {public static void main(String[] args) throws Exception {Matcher m = Pattern.compile("[frb][aiu][gx]").matcher("fix the rug with bags");while (m.find()) {System.out.print(m.group() + " ");}System.out.println();m.reset("fix the rig with rags");while (m.find()) {System.out.print(m.group() + " ");}}
}

使用不带参数的 reset() 方法,可以将 Matcher 对象重新设置到当前字符序列的起始位置。
正则表达式与 Java I/O
到目前为止,我们看到的例子都是将正则表达式用于静态的字符串。下面的例子将向你演示,如何应用正则表达式在一个文件中进行搜索匹配操作。JGrep.java 的灵感源自于 Unix 上的 grep。它有两个参数:文件名以及要匹配的正则表达式。输出的是每行有匹配的部分以及匹配部分在行中的位置。
import java.util.regex.*;
import java.nio.file.*;public class JGrep {public static void main(String[] args) throws Exception {if (args.length < 2) {System.out.println("Usage: java JGrep file regex");System.exit(0);}Pattern p = Pattern.compile(args[1]);// Iterate through the lines of the input file: int index = 0;Matcher m = p.matcher("");for (String line : Files.readAllLines(Paths.get(args[0]))) {m.reset(line);while (m.find()) {System.out.println(index++ + ": " +m.group() + ": " + m.start());}}}
}
Files.readAllLines() 返回一个 List<String> 对象,这意味着可以用 for-in 进行遍历。虽然可以在 for 循环内部创建一个新的 Matcher 对象,但是,在循环体外创建一个空的 Matcher 对象,然后用 reset() 方法每次为 Matcher 加载一行输入,这种处理会有一定的性能优化。最后用 find() 搜索结果。
这里读入的测试参数是 JGrep.java 文件,然后搜索以 [Ssct] 开头的单词。
如果想要更深入地学习正则表达式,你可以阅读 Jeffrey E. F. Friedl 的《精通正则表达式(第2版)》。网络上也有很多正则表达式的介绍,你还可以从 Perl 和 Python 等其他语言的文档中找到有用的信息。













)

)


...)
