一、算法初识
数据结构和算法是程序的基石。我们使用的所有数据类型就是一种数据结构(数据的组织形式),写的程序逻辑就是算法。
算法是指用来操作数据、解决程序问题的一组方法。
对于同一个问题,使用不同的算法,也许最终得到的结果是一样的,但在过程中消耗的资源(空间复杂度)和时间(时间复杂度)却会有很大的区别。
时间维度:是指执行当前算法所消耗的时间,我们通常用「时间复杂度」来描述。
空间维度:是指执行当前算法需要占用多少内存空间,我们通常用「空间复杂度」来描述。
常见的时间复杂度量级有(大O符号表示法):
- 常数阶O(1)
- 对数阶O(logN)
- 线性阶O(n)
- 线性对数阶O(nlogN)
- 平方阶O(n²)
- 立方阶O(n³)
- K次方阶O(n^k)
- 指数阶(2^n)
上面从上至下依次的时间复杂度越来越大,执行的效率越来越低。(具体参考此博客)
Python:常用的排序算法
二、Python和Go/Java/C语言混编
1.动态链接库(dll,so文件)
Linux下的动态库以.so 结尾
Windows下的动态库以.dll结尾
2.Go语言写的代码,把所有代码都编译到一个可执行文件
3.C语言写的程序,支持不同的代码编译到动态链接库中
4.Python调用动态链接库(so,dll)
from ctypes import *
#----------以下四种加载DLL方式皆可—————————
# pDLL = WinDLL("./myTest.dll")
# pDll = windll.LoadLibrary("./myTest.dll")
# pDll = cdll.LoadLibrary("./myTest.dll")
pDll = CDLL("./myTest.dll")#调用动态链接库函数
res = pDll.sum(1,2)
#打印返回结果
print(res)
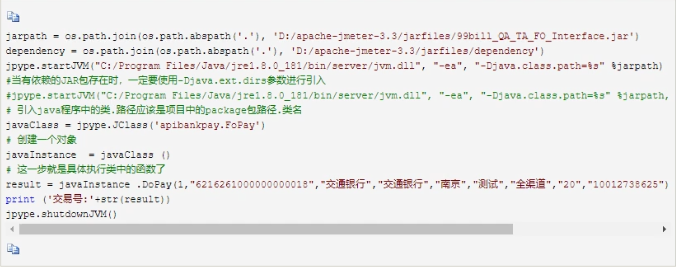
5.Python调用Java的jar包
6.Go写的代码编译成动态链接库文件(参考此博客)
package main
import "C" //必须引入C库
import "fmt"
//加入下面注释代码,表示导出,可以被python调用
//export PrintDll
func PrintDll() {fmt.Println("我来自dll")
}
//
//export Sum
func Sum(a int, b int) int {return a + b
}
func main() {//必须加一个main函数,作为CGO编译的入口,无具体实现代码
}
编译成so库:
go build -buildmode=c-shared -o s1.so s1.go
编译成dll库:
go build -buildmode=c-shared -o s1.dll s1.go
python调用so文件:
from ctypes import cdlllib = cdll.LoadLibrary('./s1.so')# 调用go语言的Sum
result = lib.Sum(100, 200)
print(result)# 调用go语言的PrintDll
lib.PrintDll()
7.什么场景使用
1)生成支付连接的方法---->so文件
2)雪花算法
三、分布式锁
在很多场景中,我们为了保证数据的最终一致性,需要很多的技术方案来支持,比如分布式锁,那具体什么是分布式锁?
分布式锁具备的条件:
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败。
如何实现?
1、基于数据库实现分布式锁
2、基于缓存(Redis等)实现分布式锁,官方提供了redlock
示例:
from redlock import Redlockdlm = Redlock([{"host": "localhost", "port": 6379, "db": 0}, ])# 获得锁
my_lock = dlm.lock("my_resource_name", 1000)print("锁被我拿到了,你们任何人都拿不到了")dlm.unlock(my_lock)
底层基于SETNX,当且仅当key不存在时,set一个key为val的字符串,返回1;若key存在,则什么都不做,返回0。封装如下:
#连接redis
import redis
import uuid
import time
redis_client = redis.Redis(host="localhost",port=6379,# password=,db=10)#获取一个锁
# lock_name:锁名称
# acquire_time: 客户端等待获取锁的时间
# time_out: 锁的超时时间
def acquire_lock(lock_name, acquire_time=10, time_out=10):"""获取一个分布式锁"""identifier = str(uuid.uuid4())end = time.time() + acquire_timelock = "string:lock:" + lock_namewhile time.time() < end:if redis_client.setnx(lock, identifier):# 给锁设置超时时间, 防止进程崩溃导致其他进程无法获取锁redis_client.expire(lock, time_out)return identifierelif not redis_client.ttl(lock):redis_client.expire(lock, time_out)time.sleep(0.001)return False#释放一个锁
def release_lock(lock_name, identifier):"""通用的锁释放函数"""lock = "string:lock:" + lock_namepip = redis_client.pipeline(True)while True:try:pip.watch(lock)lock_value = redis_client.get(lock)if not lock_value:return Trueif lock_value.decode() == identifier:pip.multi()pip.delete(lock)pip.execute()return Truepip.unwatch()breakexcept redis.excetions.WacthcError:passreturn False
3、基于Zookeeper实现分布式锁(参考此博客)
四、分布式ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
具备条件:
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
趋势递增:mysql主键
单调递增:保证下一个ID一定大于上一个ID
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
平均延迟和TP999延迟都要尽可能低(TP90就是满足百分之九十的网络请求所需要的最低耗时。TP99就是满足百分之九十九的网络请求所需要的最低耗时。同理TP999就是满足千分之九百九十九的网络请求所需要的最低耗时);可用性5个9(99.999%);高QPS。
如何实现?
mysql自增、UUID、Redis生成ID、snowflake(雪花算法)方案(比较主流)
五、IO模型
数据复制的过程中(IO)不会消耗CPU
网络IO、磁盘IO
用户缓冲区和内核换冲突:
1、内存分为内核缓冲区和用户缓冲区
2、用户的应用程序不能直接操作内核缓冲区,需要将数据从内核拷贝到用户才能使用
3、而IO操作、网络请求加载到内存的数据一开始是放在内核缓冲区的
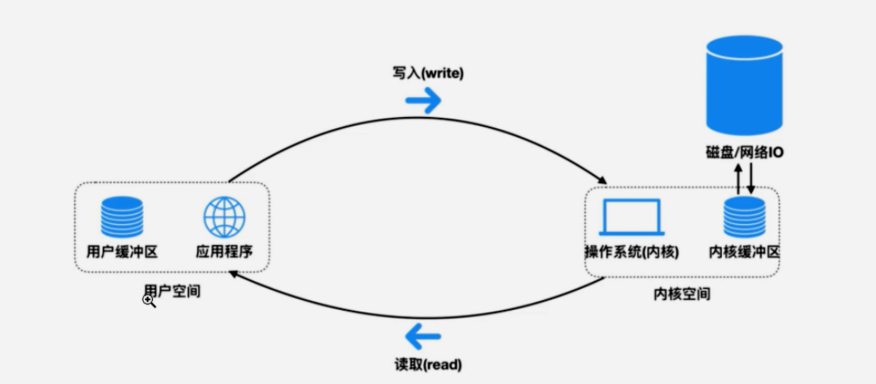
IO模型有哪些?
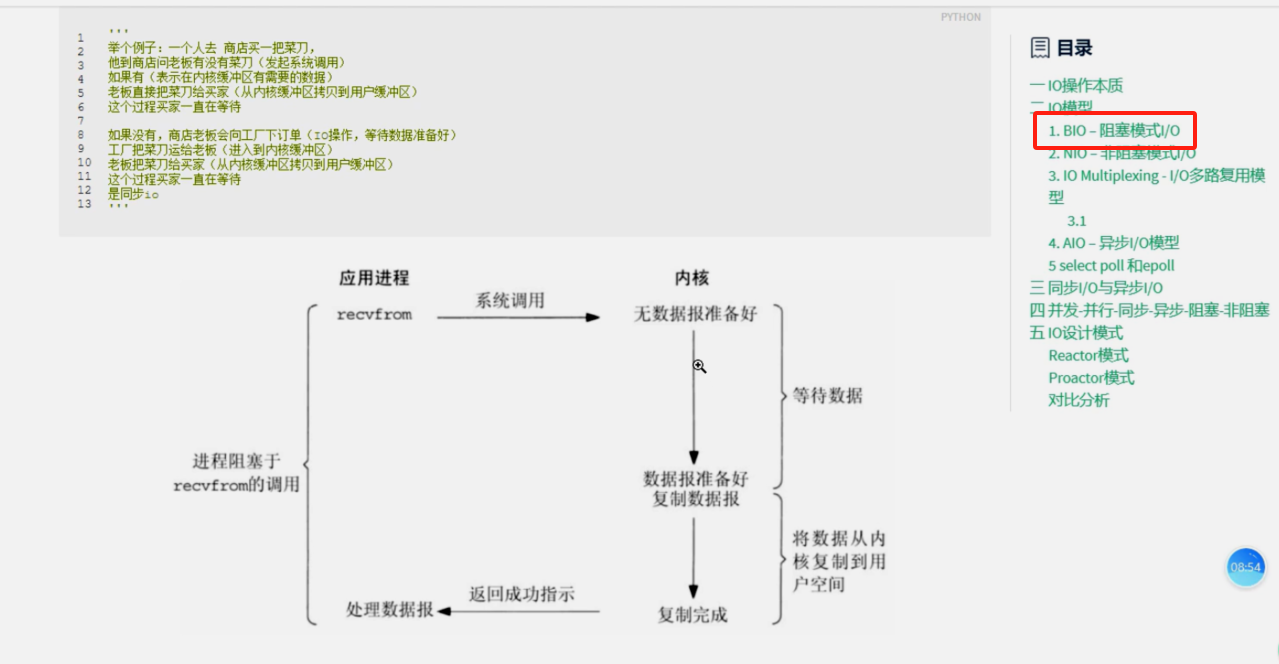
1、BIO-阻塞模式I/O
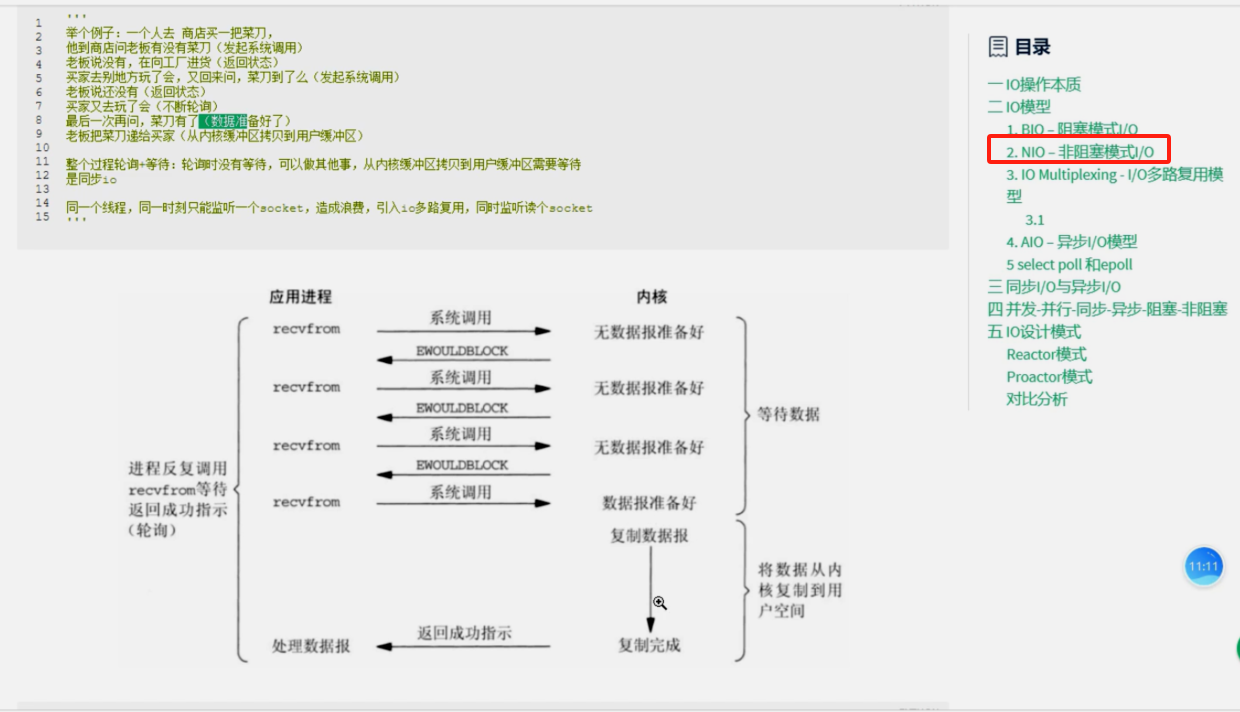
2、NIO-非阻塞模式I/O
3、IO多路复用模型
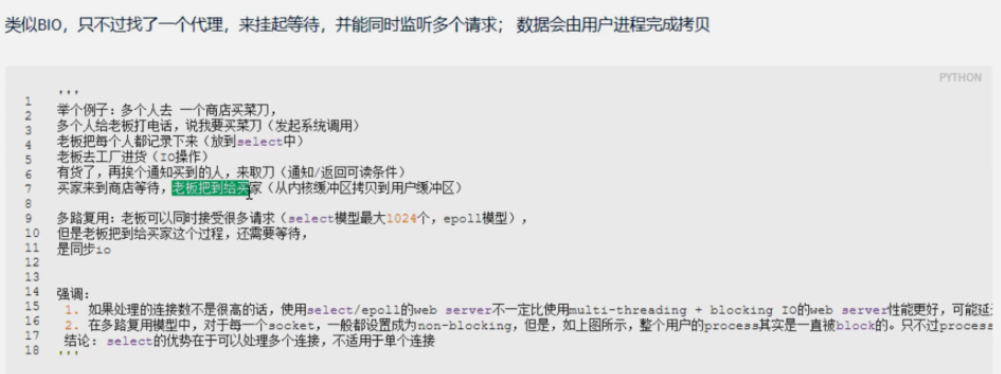
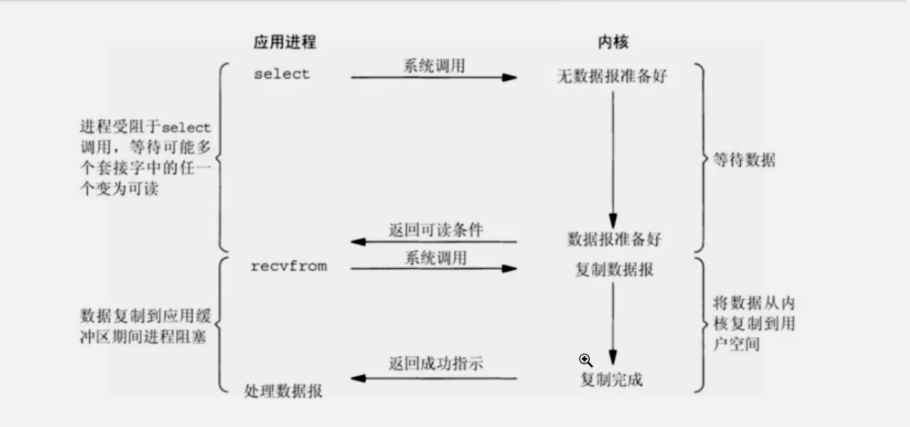
注意:
1.IO多路复用是阻塞式IO
2.select poll和epoll的区别
select poll:基于轮询,最多监听1024个文件的变化
epoll:基于回调,无限制监听
3.IO多路复用epoll模型是比较成熟的IO模型
4、AIO-异步I/O模型

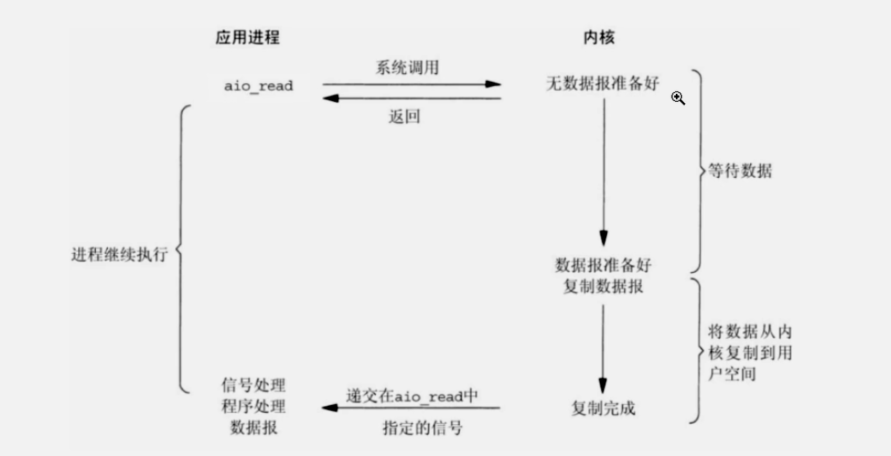
注意:
AIO指用户缓冲区到内核缓冲区不等待,从内核缓冲区到用户缓冲区也不等待;
市面上没有成熟的框架,因为内核缓冲区copy到用户缓冲区过程性能消耗很低,基本忽略。
阻塞与非阻塞、同步与异步区别:
同步和异步是消息通讯的机制,阻塞和非阻塞是函数调用机制。
又分为同步阻塞、同步非阻塞、异步阻塞、异步非阻塞
1 并发
并发是指一个时间段内,有几个程序在同一个cpu上执行,但是同一时刻,只有一个程序在cpu上运行
比如跑步,鞋带开了,停下跑步,系鞋带
2 并行
指任意时刻点上,有多个程序同时运行在多个cpu上
比如跑步,边跑步边听音乐
3 同步:
指代码调用io操作时,必须等待io操作完成才返回的调用方式
4 异步
异步是指代码调用io操作时,不必等io操作完成就返回调用方式
5 阻塞
指调用函数时候,当前线程别挂起
6 非阻塞
指调用函数时候,当前线程不会被挂起,而是立即返回
)











)




串口应用编程之串口介绍)

