文章目录
- 0、前言
- 1、网络介绍
- 1.1、输入
- 1.2、Backbone主干网络
- 1.3、Neck
- 1.4、Prediction预测输出
- 1.4.1、Decoupled Head解耦头
- 1.4.2、Anchor-Free
- 1.4.3、标签分配
- 1.4.4、Loss计算
- 1.5、Yolox-s、l、m、x系列
- 1.6、轻量级网络研究
- 1.6.1、轻量级网络
- 1.6.2、数据增强的优缺点
- 1.7、Yolox的实现成果
- 1.7.1、精度速度对比
- 1.7.2、Autonomous Driving竞赛
- 1.8、网络训练
- 2、测试
- 2.1、官方脚本测试
- 2.1.1、torch 模型测试
- 2.1.2、onnx 模型测试
- 2.1.3、opencv dnn测试
- 2.2、测试汇总对比
0、前言
YOLOX是旷视科技在2021年发表,对标YOLO v5。YOLOX中引入了当年的黑科技主要有三点,decoupled head、anchor-free以及advanced label assigning strategy(SimOTA)。YOLOX的性能如何呢,可以参考原论文图一如下图所示。YOLOX比当年的YOLO v5略好一点,并且利用YOLOX获得当年的Streaming Perception Challenge第一名。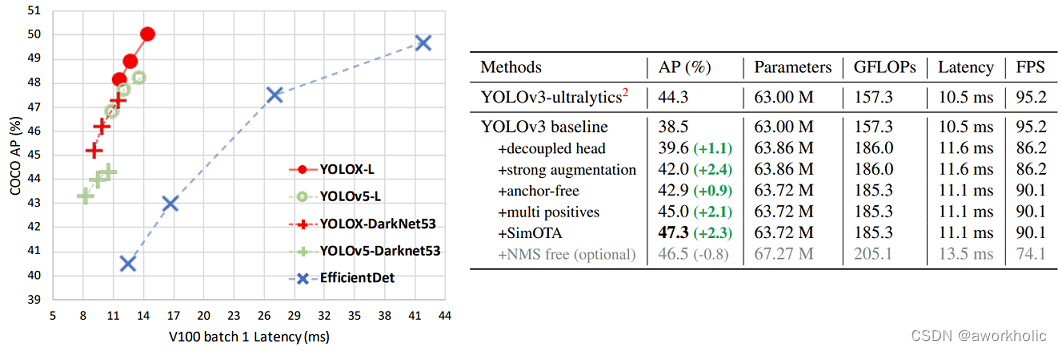
那这里可能有人会问了,在自己的项目中在YOLO v5和YOLOX到底应该选择哪个(后面还有yolov7,yolov8…)。如果数据集图像分辨率不是很高,比如640x640,那么两者都可以试试。如果分辨率很高,比如1280x1280,那么使用YOLO v5。因为YOLO v5官方仓库有提供更大尺度的预训练权重,而YOLOX当前只有640x640的预训练权重(YOLOX官方仓库说后续会提供更大尺度的预训练权重,目前一年多也毫无音讯)。
主要的模型内容:
- 对Yolov3 baseline基准模型,添加各种trick,比如Decoupled Head、SimOTA等,得到Yolox-Darknet53版本;
- 对Yolov5的四个版本,采用这些有效的trick,逐一进行改进,得到Yolox-s、Yolox-m、Yolox-l、Yolox-x四个版本;
- 设计了Yolox-Nano、Yolox-Tiny轻量级网络,并测试了一些trick的适用性;
1、网络介绍
以Yolox-Darknet53为例,给出网络结构
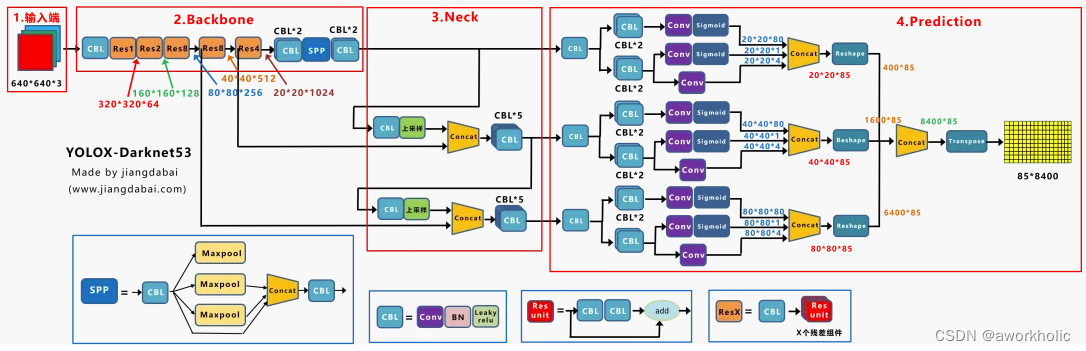
为了便于分析改进点,我们对Yolox-Darknet53网络结构进行拆分,变为四个板块:
- 输入端:Strong augmentation数据增强
- BackBone主干网络:主干网络没有什么变化,还是Darknet53。
- Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
- Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
在经过一系列的改进后,Yolox-Darknet53最终达到AP47.3的效果。
1.1、输入
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。而采用了这两种数据增强,直接将Yolov3 baseline,提升了2.4个百分点。
有两点需要注意:(1)在训练的最后15个epoch,这两个数据增强会被关闭掉。而在此之前,Mosaic和Mixup数据增强,都是打开的,这个细节需要注意。(2)由于采取了更强的数据增强方式,作者在研究中发现,ImageNet预训练将毫无意义,因此,所有的模型,均是从头开始训练的。
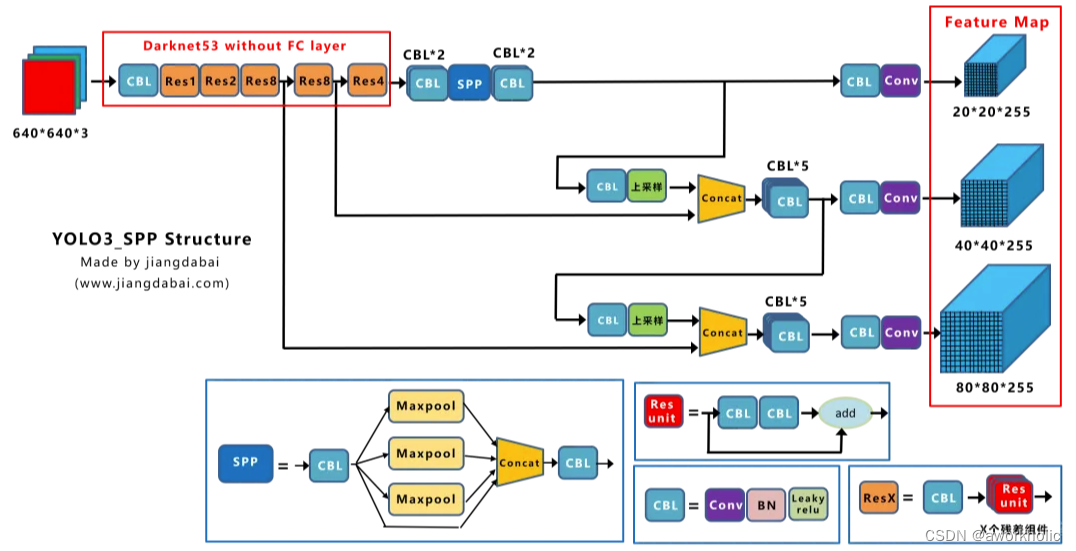
1.2、Backbone主干网络
Yolox-Darknet53和原本的Yolov3 baseline的主干网络都是采用Darknet53的网络结构。
1.3、Neck
Yolox-Darknet53和Yolov3 baseline的Neck结构都是采用FPN的结构进行融合。
如下图所示,FPN自顶向下,将高层的特征信息,通过上采样的方式进行传递融合,得到进行预测的特征图。
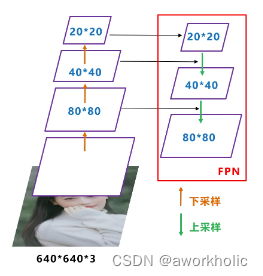
1.4、Prediction预测输出
在输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算。
1.4.1、Decoupled Head解耦头
目前在很多一阶段网络中都有类似应用,比如RetinaNet、FCOS等。而在Yolox中,作者增加了三个Decoupled Head。
基准网络中,Yolov3 baseline的AP值为38.5。作者想继续改进,比如输出端改进为End-to-end的方式(即无NMS的形式)后的AP值只有34.3。在对FCOS改进为无NMS时,在COCO上,达到了与有NMS的FCOS,相当的性能。为什么在Yolo上改进,会下降这么多?在偶然间,作者将End-to-End中的Yolo Head,修改为Decoupled Head的方式。
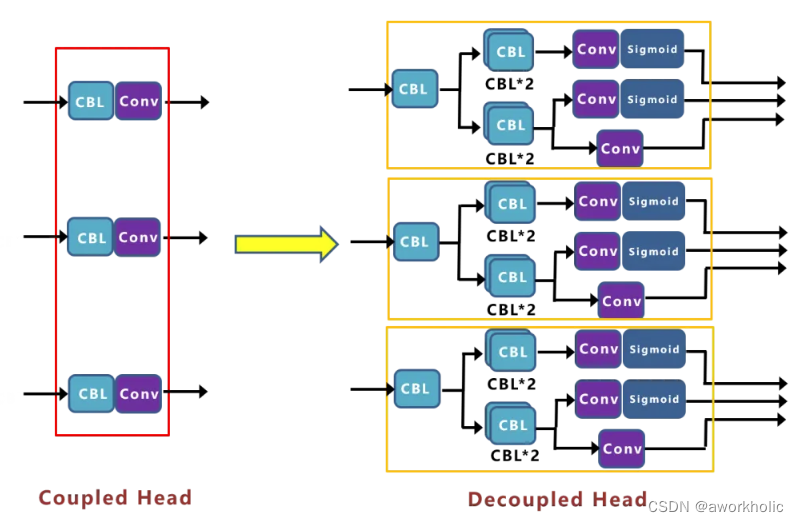
测试发现,End-to-end Yolo的AP值,从34.3增加到38.8。作者又将Yolov3 baseline 中Yolo Head,也修改为Decoupled Head,发现AP值,从38.5,增加到39.6。还发现,不单单是精度上的提高,网络的收敛速度也加快了。结论:目前Yolo系列使用的检测头,表达能力可能有所欠缺,没有Decoupled Head的表达能力更好。对比曲线如下
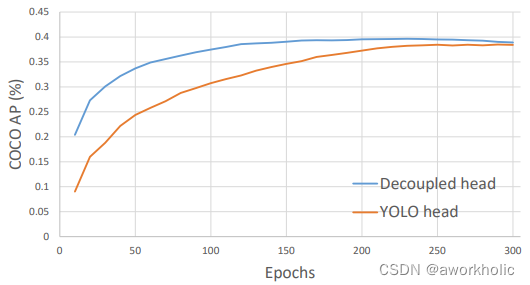
曲线表明:Decoupled Head的收敛速度更快,且精度更高一些。但是需要注意的是:将检测头解耦,会增加运算的复杂度。因此作者经过速度和性能上的权衡,最终使用 1个1x1 的卷积先进行降维,并在后面两个分支里,各使用了 2个3x3 卷积,最终调整到仅仅增加一点点的网络参数。而且这里解耦后,还有一个更深层次的重要性:Yolox的网络架构,可以和很多算法任务,进行一体化结合。比如:(1)YOLOX + Yolact/CondInst/SOLO ,实现端侧的实例分割。(2)YOLOX + 34 层输出,实现端侧人体的 17 个关键点检测。
Yolox-Darknet53的decoupled detection head的细节如图,对于预测Cls.、Reg.以及IoU参数分别使用三个不同的分支,将三者进行解耦。注意一点,在YOLOX中对于不同的预测特征图采用不同的head,即参数不共享。第一个Head 输出长度为20*20。Concat前总共有三个分支:Concat前总共有三个分支:
(1)cls_output:主要对目标框的类别,预测分数。因为COCO数据集总共有80个类别,且主要是N个二分类判断,因此经过Sigmoid激活函数处理后,变为20*20*80大小。
(2)obj_output:主要判断目标框是前景还是背景,因此经过Sigmoid处理好,变为20*20*1大小。
(3)reg_output:主要对目标框的坐标信息(x,y,w,h)进行预测,因此大小为20*20*4。
最后三个output,经过Concat融合到一起,得到20*20*85的特征信息。当然,这只是Decoupled Head①的信息,再对Decoupled Head②和③进行处理。
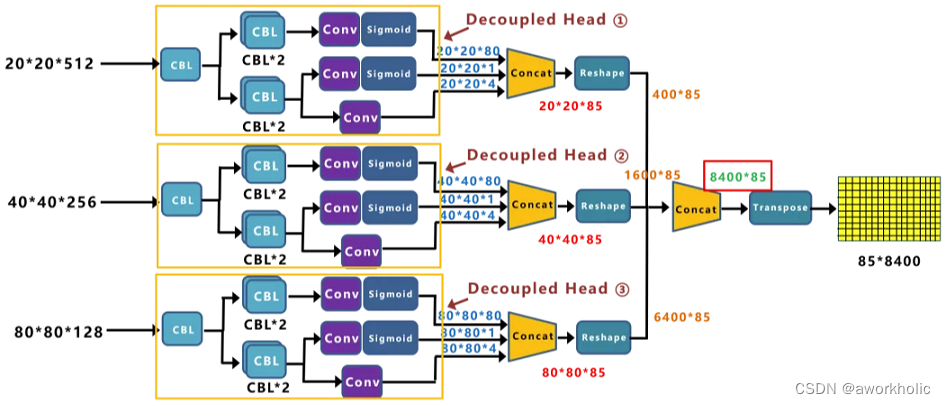
Decoupled Head②输出特征信息,并进行Concate,得到404085特征信息。Decoupled Head③输出特征信息,并进行Concate,得到808085特征信息。再对①②③三个信息,进行Reshape操作,并进行总体的Concat,得到8400*85的预测信息。
1.4.2、Anchor-Free
目前行业内,主要有Anchor Based和Anchor Free两种方式,在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
① Anchor Based方式
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。这时,就要设置一些Anchor规则,将预测框和标注框进行关联。从而在训练中,计算两者的差距,即损失函数,再更新网络参数。比如在下图的,最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。
输入为416*416时,网络最后的三个特征图大小为13*13,26*26,52*52。每个特征图上的格点都预测三个锚框。当采用COCO数据集,即有80个类别时。基于每个锚框,都有x、y、w、h、obj(前景背景)、class(80个类别),共85个参数。因此会产生3*(13*13+26*26+52*52)*85=904995个预测结果。如果输入为640*640,最后的三个特征图大小为20*20,40*40,80*80,则会产生3*(20*20+40*40+80*80)*85=2142000个预测结果。
② Anchor Free方式
Yolox-Darknet53中,则采用Anchor Free的方式。网络的输出不同于Yolov3中的FeatureMap,而是 8400*85 的特征向量。通过计算,8400*85=714000个预测结果,比基于Anchor Based的方式,少了2/3的参数量。
Anchor框信息在前面Anchor Based中,我们知道每个Feature map的单元格,都有3个大小不一的锚框。Yolox-Darknet53仍然有,只是巧妙的将前面Backbone中下采样的大小信息引入进来。
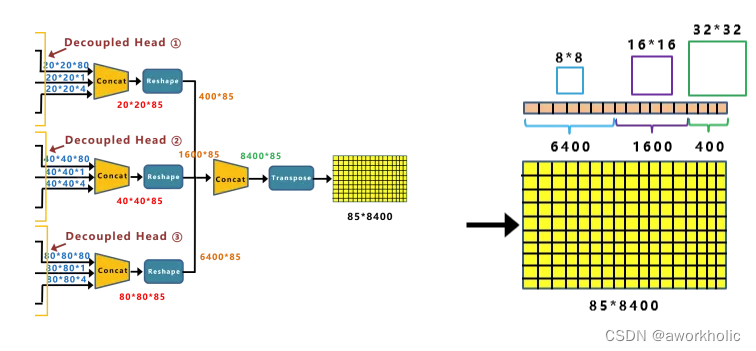
最上面的分支,下采样了5次,2的5次方为32,并且Decoupled Head①的输出,为202085大小。中间的分支,有1600个预测框,所对应锚框的大小为16*16。最后分支有6400个预测框,所对应锚框的大小,为8*8。
1.4.3、标签分配
1.4.4、Loss计算
1.5、Yolox-s、l、m、x系列
Yolov5s的网络结构图
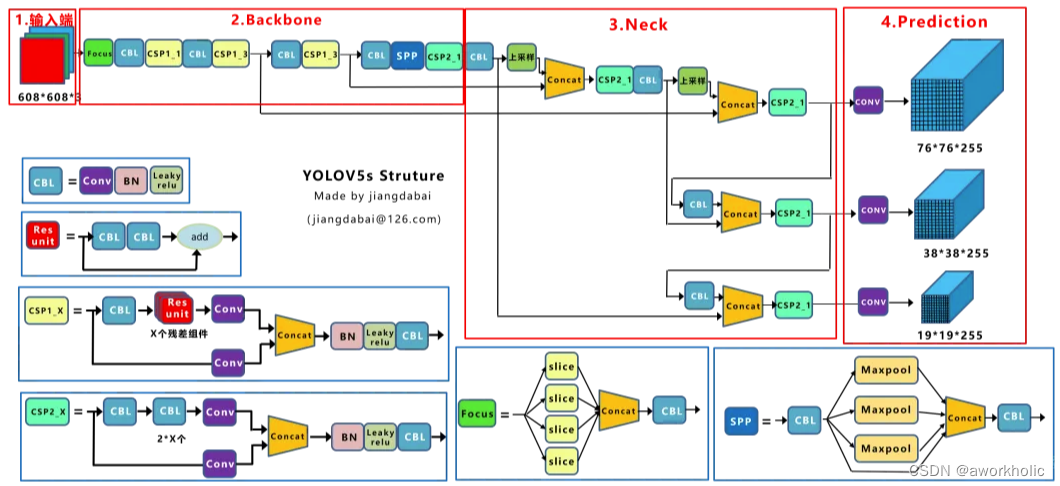
Yolox-s的网络结构:
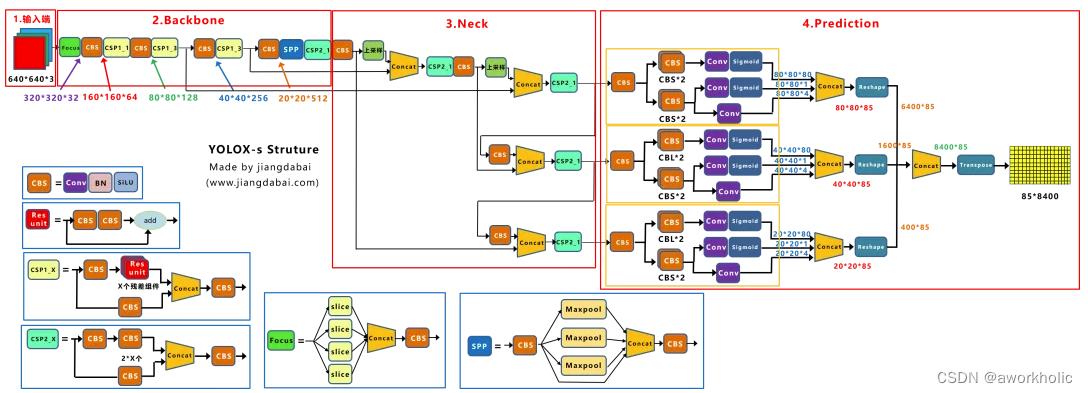
由上面两张图的对比,及前面的内容可以看出,Yolov5s和Yolox-s主要区别在于:(1)输入端:在Mosa数据增强的基础上,增加了Mixup数据增强效果;(2)Backbone:激活函数采用SiLU函数;(3)Neck:激活函数采用SiLU函数;(4)输出端:检测头改为Decoupled Head、采用anchor free、multi positives、SimOTA的方式。在前面Yolov3 baseline的基础上,以上的tricks,取得了很不错的涨点。
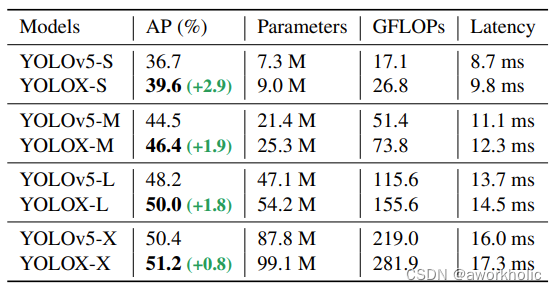 可以看出,在速度增加1ms左右的情况下,AP精度实现了0.8~2.9的涨点。且网络结构越轻,比如Yolox-s的时候,涨点最多,达到2.9的涨点。随着网络深度和宽度的加深,涨点慢慢降低,最终Yolox-x有0.8的涨点。
可以看出,在速度增加1ms左右的情况下,AP精度实现了0.8~2.9的涨点。且网络结构越轻,比如Yolox-s的时候,涨点最多,达到2.9的涨点。随着网络深度和宽度的加深,涨点慢慢降低,最终Yolox-x有0.8的涨点。
1.6、轻量级网络研究
在对Yolov3、Yolov5系列进行改进后,作者又设计了两个轻量级网络,与Yolov4-Tiny、和Yolox-Nano进行对比。在研究过程中,作者有两个方面的发现,主要从轻量级网络,和数据增强的优缺点,两个角度来进行描述。
1.6.1、轻量级网络
因为实际场景的需要将Yolo移植到边缘设备中。因此针对Yolov4-Tiny,构建了Yolox-Tiny网络结构;针对FCOS 风格的NanoDet,构建了Yolox-Nano网络结构。
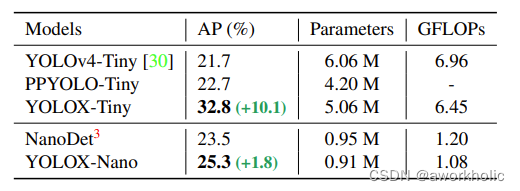
从上表可以看出:(1)和Yolov4-Tiny相比,Yolox-Tiny在参数量下降1M的情况下,AP值实现了9个点的涨点。(2)和NanoDet相比,Yolox-Nano在参数量下降,仅有0.91M的情况下,实现了1.8个点的涨点。(3)因此可以看出,Yolox的整体设计,在轻量级模型方面,依然有很不错的改进点。
1.6.2、数据增强的优缺点
在Yolox的很多对比测试中,都使用了数据增强的方式。但是不同的网络结构,有的深有的浅,网络的学习能力不同,那么无节制的数据增强是否真的更好呢?作者团队,对这个问题也进行了对比测试。
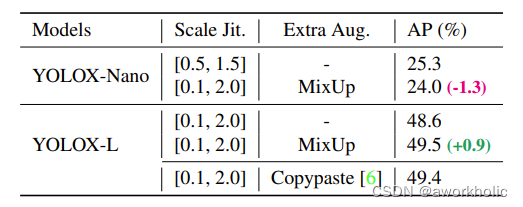
通过以上的表格有以下发现:
① Mosaic和Mixup混合策略(1)对于轻量级网络,Yolox-nano来说,当在Mosaic基础上,增加了Mixup数据增强的方式,AP值不增反而降,从25.3降到24。(2)而对于深一些的网络,Yolox-L来说,在Mosaic基础上,增加了Mixup数据增强的方式,AP值反而有所上升,从48.6增加到49.5。(3)因此不同的网络结构,采用数据增强的策略也不同,比如Yolox-s、Yolox-m,或者Yolov4、Yolov5系列,都可以使用不同的数据增强策略进行尝试。
② Scale 增强策略在Mosaic数据增强中,代码Yolox/data/data_augment.py中的random_perspective函数,生成仿射变换矩阵时,对于图片的缩放系数,会生成一个随机值。
对于Yolox-l来说,随机范围scale设置在[0.1,2]之间,即文章中设置的默认参数;而当使用轻量级模型,比如YoloNano时,一方面只使用Mosaic数据增强,另一方面随机范围scale,设置在[0.5,1.5]之间,弱化Mosaic增广的性能。
1.7、Yolox的实现成果
1.7.1、精度速度对比
前面我们了解了Yolox的各种trick改进的原因以及原理,下面我们再整体看一下各种模型精度速度方面的对比:
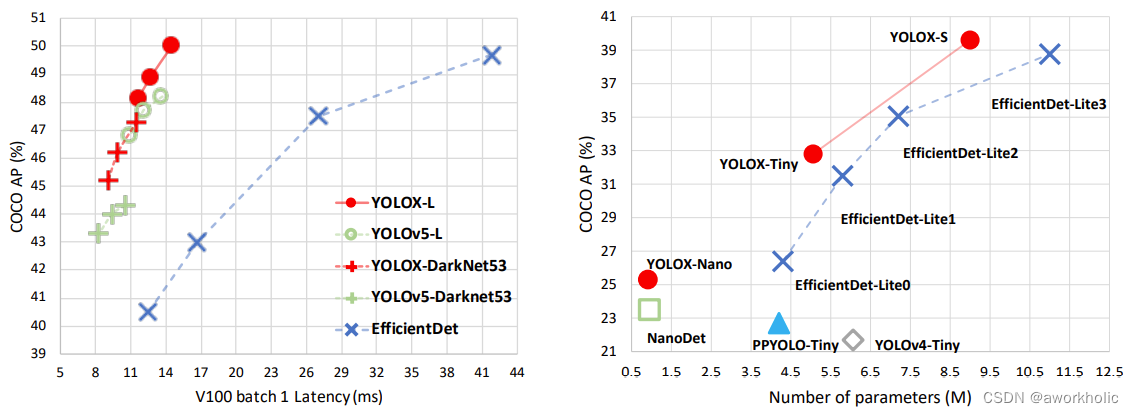
左面的图片是相对比较标准的,网络结构的对比效果,主要从速度和精度方面,进行对比。而右面的图片,则是轻量级网络的对比效果,主要对比的是参数量和精度。
从左面的图片可以得出:(1)和与Yolov4-CSP相当的Yolov5-l进行对比,Yolo-l在COCO数据集上,实现AP50%的指标,在几乎相同的速度下超过Yolov5-l 1.8个百分点。(2)而Yolox-Darknet53和Yolov5-Darknet53相比,实现AP47.3%的指标,在几乎同等速度下,高出3个百分点。
而从右面的图片可以得出:(1)和Nano相比,Yolox-Nano参数量和GFLOPS都有减少,参数量为0.91M,GFLOPS为1.08,但是精度可达到25.3%,超过Nano1.8个百分点。(2)而Yolox-Tiny和Yolov4-Tiny相比,参数量和GFLOPS都减少的情况下,精度远超Yolov4-Tiny 9个百分点。
1.7.2、Autonomous Driving竞赛
在CVPR2021自动驾驶竞赛的,Streaming Perception Challenge赛道中,挑战的主要关注点之一,是自动驾驶场景下的实时视频流2D目标检测问题。由一个服务器收发图片和检测结果,来模拟视频流30FPS的视频,客户端接收到图片后进行实时推断。竞赛地址: https://eval.ai/web/challenges/challenge-page/800/overview
在竞赛中旷视科技采用Yolox-l作为参赛模型,同时使用TensorRT进行推理加速,最终获得了full-track和detection-only track,两个赛道比赛的第一。因此Yolox的各种改进方式还是挺不错,值得好好学习,深入研究一下。
1.8、网络训练
参考链接 https://github.com/Megvii-BaseDetection/YOLOX/blob/main/docs/train_custom_data.md
2、测试
首先clone项目并安装
git clone git@github.com:Megvii-BaseDetection/YOLOX.git
cd YOLOX
pip3 install -v -e . # or python3 setup.py develop
我们以yolox-m模型为例进行测试,下载链接使用wget工具下载
wget https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_m.pth
2.1、官方脚本测试
2.1.1、torch 模型测试
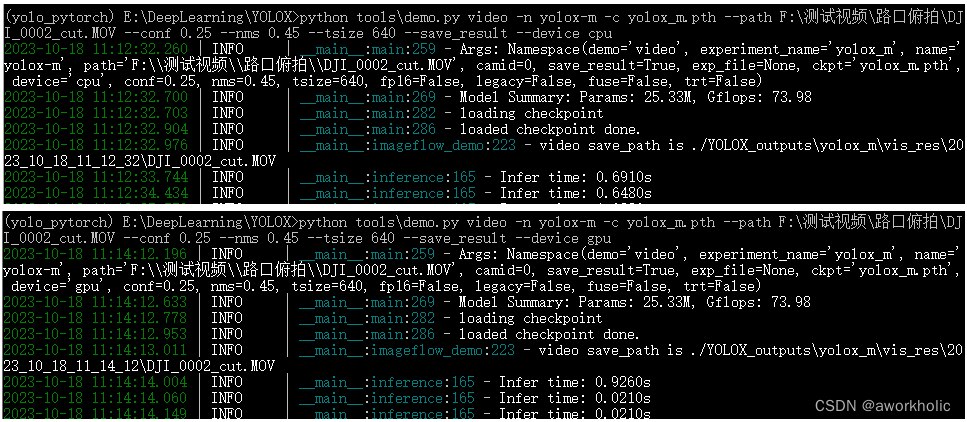
python tools/demo.py image -n yolox-m -c yolox_m.pth --path assets/dog.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
针对一个 1080p是视频,分别用 cpu和gpu测试,每一帧推理耗时分别为 650ms、20ms。
2.1.2、onnx 模型测试
官方提供了模型下载链接 https://ghproxy.com/https://github.com/Megvii-BaseDetection/YOLOX/releases/download/0.1.1rc0/yolox_m.onnx。
或者,通过脚本从 .pth 转换得到
python tools/export_onnx.py --output-name yolox_m.onnx -f exps/default/yolox_m.py -c yolox_m.pth
测试代码
python demo\ONNXRuntime\onnx_inference.py -m yolox_m.onnx -i assets\bus.jpg -o output -s 0.3 --input_shape 640,640
执行后的结果图将保存在 output 文件夹下。
2.1.3、opencv dnn测试
注意输出的后处理流程,yolox的输出为原始输出,需要解码。根据不同特征图大小、偏移和步长,计算映射到输入图像大小上的目标框,最后进行缩放到原图上。
当80类输入640*640时,输出[8400,85], 8400为目标框总个数,85为目标框的信息,格式为
[center_x, center_y, w,h, obj-score, cls1-score, cls2-score, ... , cls80-score]
8400个目标框基于anchor free,在三个不同特征图上生成, [80,80],[40,40],[20,20],对应特征图步长为 strides = 8,16, 32。首先是特征图[80,80],存在6400个位置,每个位置对应 80类目标的信息(85维);之后同理,[40,40]存在1600个位置,[20,20]存在400个位置。
center_x, center_y :表示位于当前特征图的格点位置偏移,例如 在40x40上, 格点(1,2),那么 center_x = 0.12,center_y = 0.08, 那么映射到 输入图上是位置为 [(1+0.12)*16,( 2 + 0.08) *16 ]
w,h :目标框的宽高,映射到输入图上宽高 需要乘以当前目标框所在特征图上的对应步长。
obj-score:存在目标的置信度
cls1-score, cls2-score, … , cls80-score : 每一类的置信度, 实际目标置信度要再乘以 obj-score
以下直接给出代码如下
#pragma once#include "opencv2/opencv.hpp"#include <fstream>
#include <sstream>#include <random>using namespace cv;
using namespace dnn;float inpWidth;
float inpHeight;
float confThreshold, scoreThreshold, nmsThreshold;
std::vector<std::string> classes;
std::vector<cv::Scalar> colors;bool letterBoxForSquare = true;cv::Mat formatToSquare(const cv::Mat &source);void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& out, Net& net);void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame);std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);struct GridAndStride
{int grid0;int grid1;int stride;
};static void generate_grids_and_stride(std::vector<int>& strides, std::vector<GridAndStride>& grid_strides)
{for(auto stride : strides) {int num_grid_y = inpHeight / stride;int num_grid_x = inpWidth / stride;for(int g1 = 0; g1 < num_grid_y; g1++) {for(int g0 = 0; g0 < num_grid_x; g0++) {grid_strides.push_back(GridAndStride{g0, g1, stride});}}}
}std::vector<GridAndStride> grid_strides;int NUM_CLASSES;int testYolo_x()
{// 根据选择的检测模型文件进行配置 confThreshold = 0.25;scoreThreshold = 0.45;nmsThreshold = 0.5;float scale = 1; // 1 / 255.0; //0.00392Scalar mean = {0,0,0};bool swapRB = true;inpWidth = 640;inpHeight = 640;String modelPath = R"(E:\DeepLearning\YOLOX\yolox_m.onnx)";String configPath;String framework = "";//int backendId = cv::dnn::DNN_BACKEND_OPENCV;//int targetId = cv::dnn::DNN_TARGET_CPU;int backendId = cv::dnn::DNN_BACKEND_CUDA;int targetId = cv::dnn::DNN_TARGET_CUDA;String classesFile = R"(E:\DeepLearning\darknet-yolo3-master\data\coco.names)";// Open file with classes names.if(!classesFile.empty()) {const std::string& file = classesFile;std::ifstream ifs(file.c_str());if(!ifs.is_open())CV_Error(Error::StsError, "File " + file + " not found");std::string line;while(std::getline(ifs, line)) {classes.push_back(line);colors.push_back(cv::Scalar(dis(gen), dis(gen), dis(gen)));}}NUM_CLASSES = classes.size();std::vector<int> strides = {8, 16, 32};generate_grids_and_stride(strides, grid_strides);// Load a model.Net net = readNet(modelPath, configPath, framework);net.setPreferableBackend(backendId);net.setPreferableTarget(targetId);std::vector<String> outNames = net.getUnconnectedOutLayersNames();{int dims[] = {1,3,inpHeight,inpWidth};cv::Mat tmp = cv::Mat::zeros(4, dims, CV_32F);std::vector<cv::Mat> outs;net.setInput(tmp);for(int i = 0; i<10; i++)net.forward(outs, outNames); // warmup}// Create a windowstatic const std::string kWinName = "Deep learning object detection in OpenCV";cv::namedWindow(kWinName, 0);// Open a video file or an image file or a camera stream.VideoCapture cap;cap.open(R"(E:\DeepLearning\yolov5\data\images\bus.jpg)");cv::TickMeter tk;Mat frame, blob;while(waitKey(1) < 0) {cap >> frame;if(frame.empty()) {waitKey();break;}// Create a 4D blob from a frame.cv::Mat modelInput = frame;if(letterBoxForSquare && inpWidth == inpHeight)modelInput = formatToSquare(modelInput);blobFromImage(modelInput, blob, scale, cv::Size2f(inpWidth, inpHeight), mean, swapRB, false);// Run a model.net.setInput(blob);std::vector<Mat> outs;//tk.reset();//tk.start();auto tt1 = cv::getTickCount();net.forward(outs, outNames);auto tt2 = cv::getTickCount();tk.stop();postprocess(frame, modelInput.size(), outs, net);//tk.stop();std::string label = format("Inference time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);cv::putText(frame, label, Point(0, 15), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));cv::imshow(kWinName, frame);}return 0;
}cv::Mat formatToSquare(const cv::Mat &source)
{int col = source.cols;int row = source.rows;int _max = MAX(col, row);cv::Mat result = cv::Mat::zeros(_max, _max, CV_8UC3);source.copyTo(result(cv::Rect(0, 0, col, row)));return result;
}void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{// yolox has an output of shape (batchSize, 8400, 85) (box[x,y,w,h] + confidence[c] + Num classes )auto tt1 = cv::getTickCount();float x_factor = inputSz.width / inpWidth;float y_factor = inputSz.height / inpHeight;std::vector<int> class_ids;std::vector<float> confidences;std::vector<cv::Rect> boxes;float *feat_blob = (float *)outs[0].data;const int num_anchors = grid_strides.size();// 后处理部分,可以简化for(int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++) {const int grid0 = grid_strides[anchor_idx].grid0;const int grid1 = grid_strides[anchor_idx].grid1;const int stride = grid_strides[anchor_idx].stride;const int basic_pos = anchor_idx * (NUM_CLASSES + 5);float box_objectness = feat_blob[basic_pos + 4];for(int class_idx = 0; class_idx < NUM_CLASSES; class_idx++) {float box_cls_score = feat_blob[basic_pos + 5 + class_idx];float box_prob = box_objectness * box_cls_score;if(box_prob > scoreThreshold) {class_ids.push_back(class_idx);confidences.push_back(box_prob);// yolox/models/yolo_head.py decode logicfloat x_center = (feat_blob[basic_pos + 0] + grid0) * stride;float y_center = (feat_blob[basic_pos + 1] + grid1) * stride;float w = exp(feat_blob[basic_pos + 2]) * stride;float h = exp(feat_blob[basic_pos + 3]) * stride;int left = int((x_center - 0.5 * w) * x_factor);int top = int((y_center - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);boxes.push_back(cv::Rect(left, top, width, height));}} // class loop}std::vector<int> indices;NMSBoxes(boxes, confidences, scoreThreshold, nmsThreshold, indices);auto tt2 = cv::getTickCount();std::string label = format("NMS time: %.2f ms", (tt2 - tt1) / cv::getTickFrequency() * 1000);cv::putText(frame, label, Point(0, 30), FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 255, 0));for(size_t i = 0; i < indices.size(); ++i) {int idx = indices[i];Rect box = boxes[idx];drawPred(class_ids[idx], confidences[idx], box.x, box.y,box.x + box.width, box.y + box.height, frame);}
}void drawPred(int classId, float conf, int left, int top, int right, int bottom, Mat& frame)
{rectangle(frame, Point(left, top), Point(right, bottom), Scalar(0, 255, 0));std::string label = format("%.2f", conf);Scalar color = Scalar::all(255);if(!classes.empty()) {CV_Assert(classId < (int)classes.size());label = classes[classId] + ": " + label;color = colors[classId];}int baseLine;Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);top = max(top, labelSize.height);rectangle(frame, Point(left, top - labelSize.height),Point(left + labelSize.width, top + baseLine), color, FILLED);cv::putText(frame, label, Point(left, top), FONT_HERSHEY_SIMPLEX, 0.5, Scalar());
}
后处理中,可以精简,仅处理每个目标框最大概率的类别数据,以提高运行速度,以及能极大的提高NMS的时间。
void postprocess(Mat& frame, cv::Size inputSz, const std::vector<Mat>& outs, Net& net)
{....for(int anchor_idx = 0; anchor_idx < num_anchors; anchor_idx++) {const int grid0 = grid_strides[anchor_idx].grid0;const int grid1 = grid_strides[anchor_idx].grid1;const int stride = grid_strides[anchor_idx].stride;const int basic_pos = anchor_idx * (NUM_CLASSES + 5);float *data = feat_blob + basic_pos;float confidence = data[4];if(confidence < confThreshold)continue;cv::Mat scores(1, classes.size(), CV_32FC1, data + 5);cv::Point class_id;double max_class_score;minMaxLoc(scores, 0, &max_class_score, 0, &class_id);float box_prob = confidence * max_class_score;if(box_prob > scoreThreshold) {class_ids.push_back(class_id.x);confidences.push_back(box_prob);// yolox/models/yolo_head.py decode logicfloat x_center = (feat_blob[basic_pos + 0] + grid0) * stride;float y_center = (feat_blob[basic_pos + 1] + grid1) * stride;float w = exp(feat_blob[basic_pos + 2]) * stride;float h = exp(feat_blob[basic_pos + 3]) * stride;int left = int((x_center - 0.5 * w) * x_factor);int top = int((y_center - 0.5 * h) * y_factor);int width = int(w * x_factor);int height = int(h * y_factor);boxes.push_back(cv::Rect(left, top, width, height));} }... // nms + draw
}
测试结果:
cuda 36ms, cpu 420ms, fp16 650ms。

2.2、测试汇总对比
使用onnx在其他框架上测试的汇总
opencv cuda: 36ms
opencv cpu: 420ms,
opencv cuda fp16: 650ms
以下包含 预处理+推理+后处理
openvino(CPU): 199ms
onnxruntime(GPU):22ms
trt:13ms






)
)








)


