Transformer
对文本输入进行tokenizer时,调用的接口batch_encode_plus,过程大致是这样的(参考:tokenizer用法)
#这里以bert模型为例,使用上述提到的函数
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "It's a nice day today!"
#tokenize,#仅用于分词
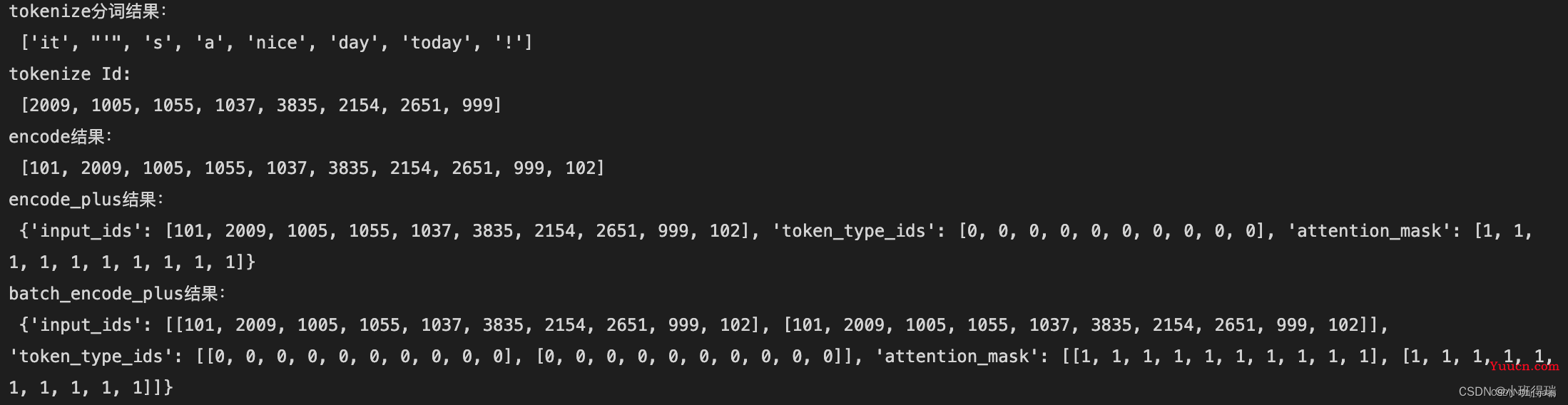
seg_words = tokenizer.tokenize(text)
print("tokenize分词结果:\n",seg_words)
#convert_tokens_to_ids,将token转化成id,在分词之后。
#convert_ids_to_tokens,将id转化成token,通常用于模型预测出结果,查看时使用。
seg_word_id = tokenizer.convert_tokens_to_ids(seg_words)
print("tokenize Id:\n",seg_word_id)
#encode,进行分词和token转换,encode=tokenize+convert_tokens_to_ids
encode_text = tokenizer.encode(text)
print("encode结果:\n",encode_text)
#encode_plus,在encode的基础之上生成input_ids、token_type_ids、attention_mask
encode_plus_text = tokenizer.encode_plus(text)
print("encode_plus结果:\n",encode_plus_text)
#batch_encode_plus,在encode_plus的基础之上,能够批量梳理文本。
batch_encode_plus_text = tokenizer.batch_encode_plus([text,text])
print("batch_encode_plus结果:\n",batch_encode_plus_text)

 但是它将不会被安装)
---让你瞬间明白如何安装jdk)



docker:建立oracle数据库mount startup)

)










