背景
我们应对并发场景时一般会采用下面方式去预估线程池的线程数量,比如QPS需求是1000,平均每个任务需要执行的时间是t秒,那么我们需要的线程数是t * 1000。
但是在一些情况下,这个t是不好估算的,即便是估算出来了,在实际的线程环境上也需要进行验证和微调。比如在本文所阐述分页查询的数据项组合场景中。
1、数据组合依赖不同的上游接接口, 它们的响应时间参差不齐,甚至差距还非常大。有些接口支持批量查询而另一些则不支持批量查询。有些接口因为性能问题还需要考虑降级和平滑方案。
2、为了提升用户体验,这里的查询设计了动态列,因此每一次访问所需要组合的数据项和数量也是不同的。
因此这里如果需要估算出一个合理的t是不太现实的。
方案
一种可动态调节的策略,根据监控的反馈对线程池进行微调。整体设计分为装配逻辑和线程池封装设计。
1、装配逻辑
查询结果,拆分分片(水平拆分),并行装配(垂直拆分),获得装配项列表(动态列), 并行装配每一项。
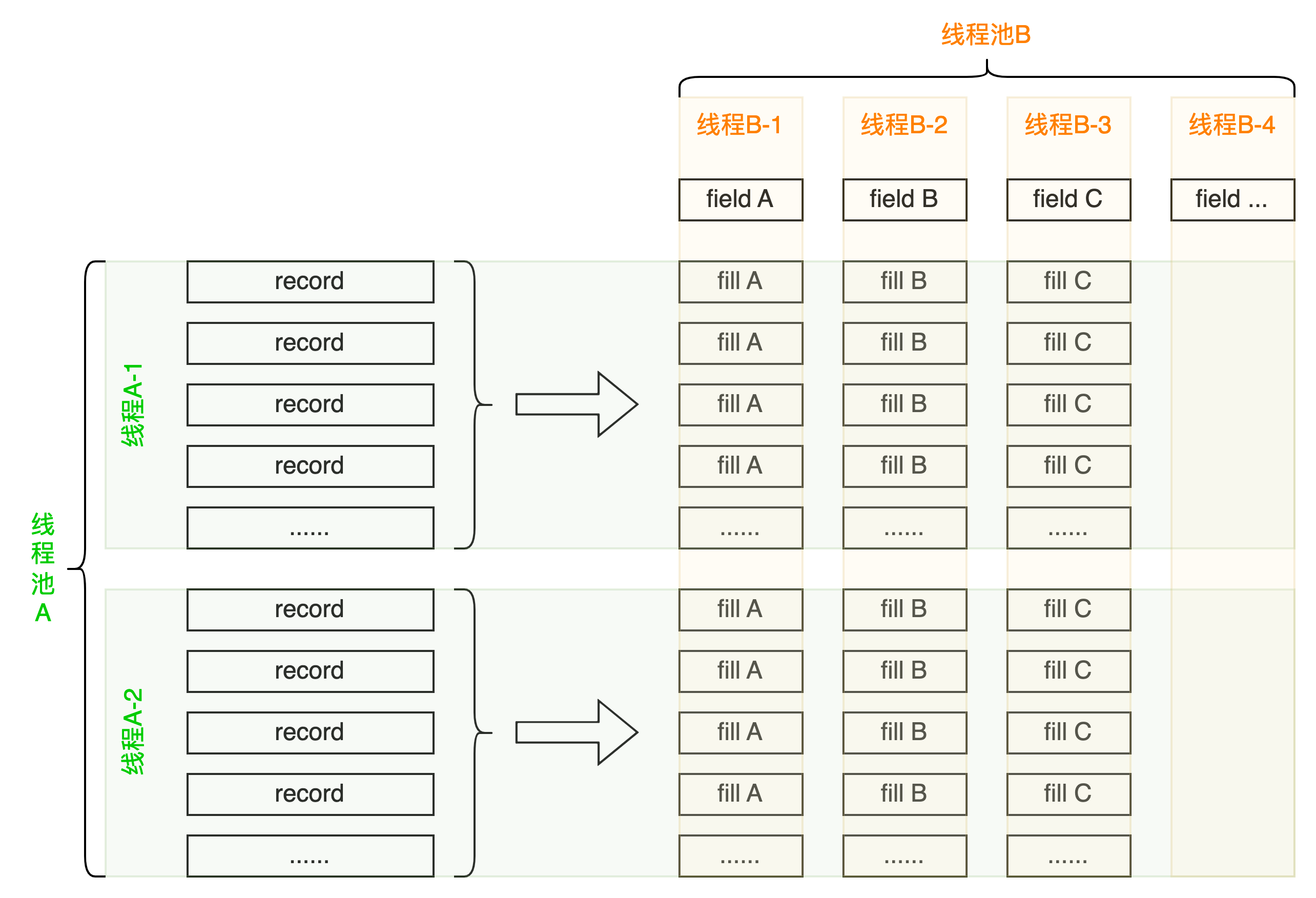
2、线程池封装
可调节的核心线程数、最大线程数、线程保持时间,队列大小,提交任务重试等待时间,提交任务重试次数。 固定异常拒绝策略。
调节参数:
| 字段 | 名称 | 说明 |
|---|---|---|
| corePoolSize | 核心线程数 | 参考线程池定义 |
| maximumPoolSize | 最大线程数 | 参考线程池定义 |
| keepAliveTime | 线程存活时间 | 参考线程池定义 |
| queueSize | 队列长度 | 参考线程池定义 |
| resubmitSleepMillis | 提交任务重试等待时间 | 添加任务被拒绝后重试时的等待时间 |
| resubmitTimes | 提交任务重试次数 | 添加任务被拒绝后重试添加的最大次数 |
@Dataprivate static class PoolPolicy {/** 核心线程数 */private Integer corePoolSize;/** 最大线程数 */private Integer maximumPoolSize;/** 线程存活时间 */private Integer keepAliveTime;/** 队列容量 */private Integer queueSize;/** 重试等待时间 */private Long resubmitSleepMillis;/** 重试次数 */private Integer resubmitTimes;}创建线程池:
线程池的创建考虑了动态的需求,满足根据压测结果进行微调的要求。首先缓存旧的线程池后再创建新的线程,当新的线程池创建成功后再去关闭旧的线程池。保证在这个替换过程中不影响正在执行的业务。线程池使用了中断策略,用户可以及时感知到系统繁忙并保证了系统资源占用的安全。
public void reloadThreadPool(PoolPolicy poolPolicy) {if (poolPolicy == null) {throw new RuntimeException("The thread pool policy cannot be empty.");}if (poolPolicy.getCorePoolSize() == null) {poolPolicy.setCorePoolSize(0);}if (poolPolicy.getMaximumPoolSize() == null) {poolPolicy.setMaximumPoolSize(Runtime.getRuntime().availableProcessors() + 1);}if (poolPolicy.getKeepAliveTime() == null) {poolPolicy.setKeepAliveTime(60);}if (poolPolicy.getQueueSize() == null) {poolPolicy.setQueueSize(Runtime.getRuntime().availableProcessors() + 1);}if (poolPolicy.getResubmitSleepMillis() == null) {poolPolicy.setResubmitSleepMillis(200L);}if (poolPolicy.getResubmitTimes() == null) {poolPolicy.setResubmitTimes(5);}// - 线程池策略没有变化直接返回已有线程池。ExecutorService original = this.executorService;this.executorService = new ThreadPoolExecutor(poolPolicy.getCorePoolSize(),poolPolicy.getMaximumPoolSize(),poolPolicy.getKeepAliveTime(), TimeUnit.SECONDS,new ArrayBlockingQueue<>(poolPolicy.getQueueSize()),new ThreadFactoryBuilder().setNameFormat(threadNamePrefix + "-%d").setDaemon(true).build(),new ThreadPoolExecutor.AbortPolicy());this.poolPolicy = poolPolicy;if (original != null) {original.shutdownNow();}
}任务提交:
线程池封装对象中使用的线程池拒绝策略是AbortPolicy,因此在线程数和阻塞队列到达上限后会触发异常。另外在这里为了保证提交的成功率利用重试策略实现了一定程度的延迟处理,具体场景中可以结合业务特点进行适当的调节和配置。
public <T> Future<T> submit(Callable<T> task) {RejectedExecutionException exception = null;Future<T> future = null;for (int i = 0; i < this.poolPolicy.getResubmitTimes(); i++) {try {// - 添加任务future = this.executorService.submit(task);exception = null;break;} catch (RejectedExecutionException e) {exception = e;this.theadSleep(this.poolPolicy.getResubmitSleepMillis());}}if (exception != null) {throw exception;}return future;
}监控:
1、submit提交的监控
见代码中的「监控点①」,在submit方法中添加监控点,监控key的需要添线程池封装对象的线程名称前缀,用于区分具体的线程池对象。
「监控点①」用于监控添加任务的动作是否正常,以便对线程池对象及策略参数进行微调。
public <T> Future<T> submit(Callable<T> task) {// - 监控点①CallerInfo callerInfo = Profiler.registerInfo(UmpConstant.THREAD_POOL_WAP + threadNamePrefix,UmpConstant.APP_NAME,UmpConstant.UMP_DISABLE_HEART,UmpConstant.UMP_ENABLE_TP);RejectedExecutionException exception = null;Future<T> future = null;for (int i = 0; i < this.poolPolicy.getResubmitTimes(); i++) {try {// - 添加任务future = this.executorService.submit(task);exception = null;break;} catch (RejectedExecutionException e) {exception = e;this.theadSleep(this.poolPolicy.getResubmitSleepMillis());}}if (exception != null) {// - 监控点①Profiler.functionError(callerInfo);throw exception;}// - 监控点①Profiler.registerInfoEnd(callerInfo);return future;
}2、线程池并行任务
见代码的「监控点②」,分别在添加任务和任务完成后。
「监控点②」实时统计在线程中执行的总任务数量,用于评估线程池的任务的数量的满载水平。
/** 任务并行数量统计 */
private AtomicInteger parallelTaskCount = new AtomicInteger(0);public <T> Future<T> submit(Callable<T> task) {RejectedExecutionException exception = null;Future<T> future = null;for (int i = 0; i < this.poolPolicy.getResubmitTimes(); i++) {try {// - 添加任务future = this.executorService.submit(()-> {T rst = task.call();// - 监控点②log.info("{} - Parallel task count {}", this.threadNamePrefix, this.parallelTaskCount.decrementAndGet());return rst;});// - 监控点②log.info("{} + Parallel task count {}", this.threadNamePrefix, this.parallelTaskCount.incrementAndGet());exception = null;break;} catch (RejectedExecutionException e) {exception = e;this.theadSleep(this.poolPolicy.getResubmitSleepMillis());}}if (exception != null) {throw exception;}return future;
}3、调节
线程池封装对象策略的调节时机
1)上线前基于流量预估的压测阶段;
2)上线后跟进监控数据和线程池中任务的满载水平进行人工微调,也可以通过JOB在指定的时间自动调整;
3)大促前依据往期大促峰值来调高相关参数。
线程池封装对象策略的调节经验
1)访问时长要求较低时,我们可以考虑调小线程数和阻塞队列,适当调大提交任务重试等待时间和次数,以便降低资源占用。
2)访问时长要求较高时,就需要调大线程数并保证相对较小的阻塞队列,调小提交任务的重试等待时间和次数甚至分别调成0和1(即关闭重试提交逻辑)。
作者:京东零售 王文明
来源:京东云开发者社区 转载请注明来源








)



)






