1946 年 , 世界上诞生了第一台电脑 , 而今借由这台电脑的发展 , 互联网已经成为一个独立的世界 .
在过去几十年里 , 许多技术和产业在互联网的舞台上兴衰交替 .
然而 , 有一门技术却从未消失 , 甚至日益强大 , 那就是SQL . SQL ( Structured Query Language,结构化查询语言 ) 是一种使用关系模型的数据库应用语言m 它的设计初衷是用来与数据直接交互 .
上世纪 70 年代 , IBM的研究员发布了一篇关于数据库技术的论文 < < SEQUEL : 一门结构化的英语查询语言 > > , 这可以说是SQL的奠基之作 .
而到了现如今 , 虽然有一些细微的变化 , 但SQL作为一门结构化的查询语言并没有发生太大的变化 . 无论是前端工程师还是后端算法工程师 , 都需要与数据打交道 , 并且需要了解如何高效地提取他们所需的数据 .
尤其是对于数据分析师而言 , 他们的工作就是与数据打交道 , 整理不同的报告以引导业务决策 . SQL有多个版本和标准 , 最重要的是SQL92和SQL99 .
它们分别代表了 1992 年和 1999 年发布的SQL标准 .
我们今天使用的SQL语言仍然遵循这些标准 . 需要提醒的是 , 不同的数据库厂商支持SQL语句 , 但每个厂商可能会有一些特殊的内容或扩展 .
因此 , 在使用SQL时需要根据具体的数据库系统来选择合适的语法和功能 .
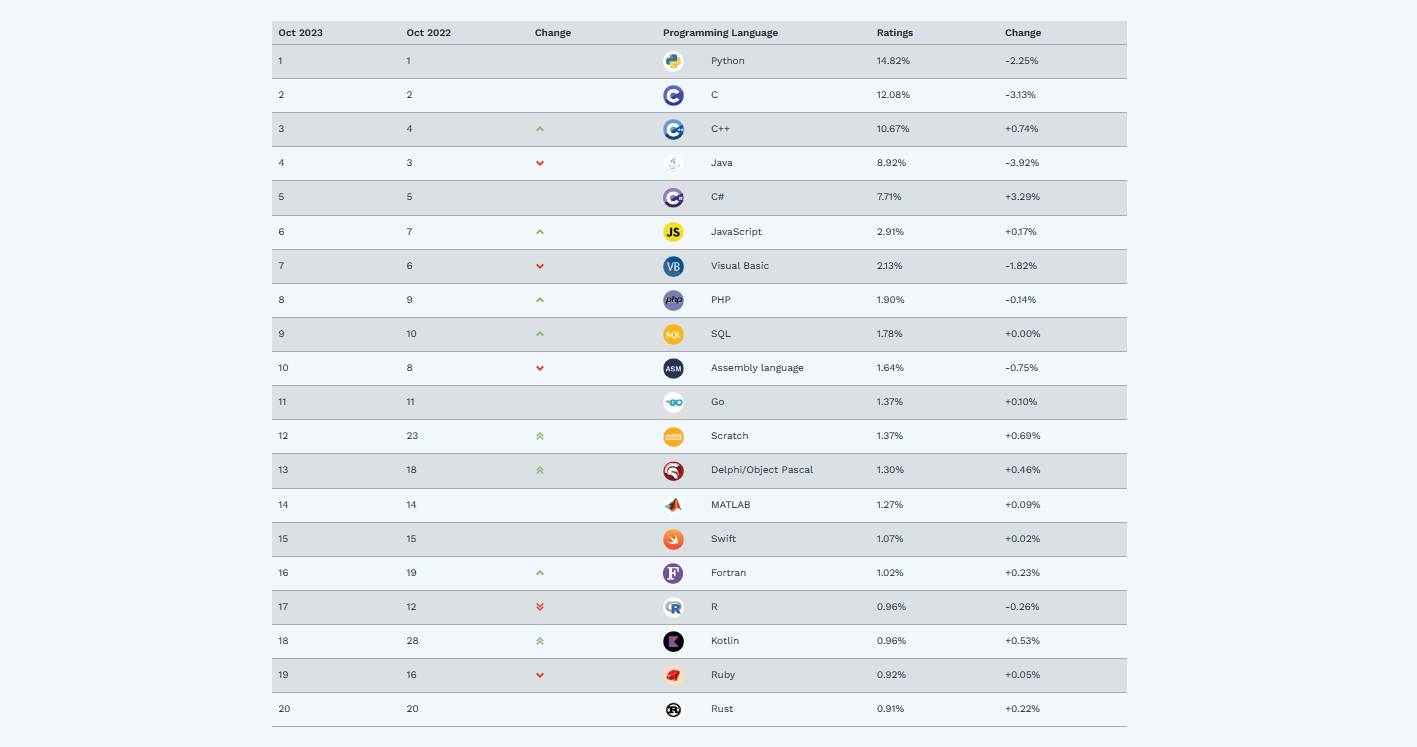
TIOBE编程语言排行榜是一个根据搜索引擎查询结果和编程语言讨论的数据来评估编程语言受欢迎程度的指标 . SQL之所以一直保持高排名 , 是因为它作为一种用于管理关系型数据库的标准语言 , 被广泛应用于各个行业和领域 .
无论是大型企业还是小型公司 , 几乎都需要使用关系型数据库进行数据存储和查询 .
而SQL作为关系型数据库的标准查询语言 , 成为了处理和管理数据的核心工具 . 排行榜地址 : https : / / www . tiobe . com / tiobe-index /
SQL是一种用于管理和操作关系型数据库的标准化查询语言 .
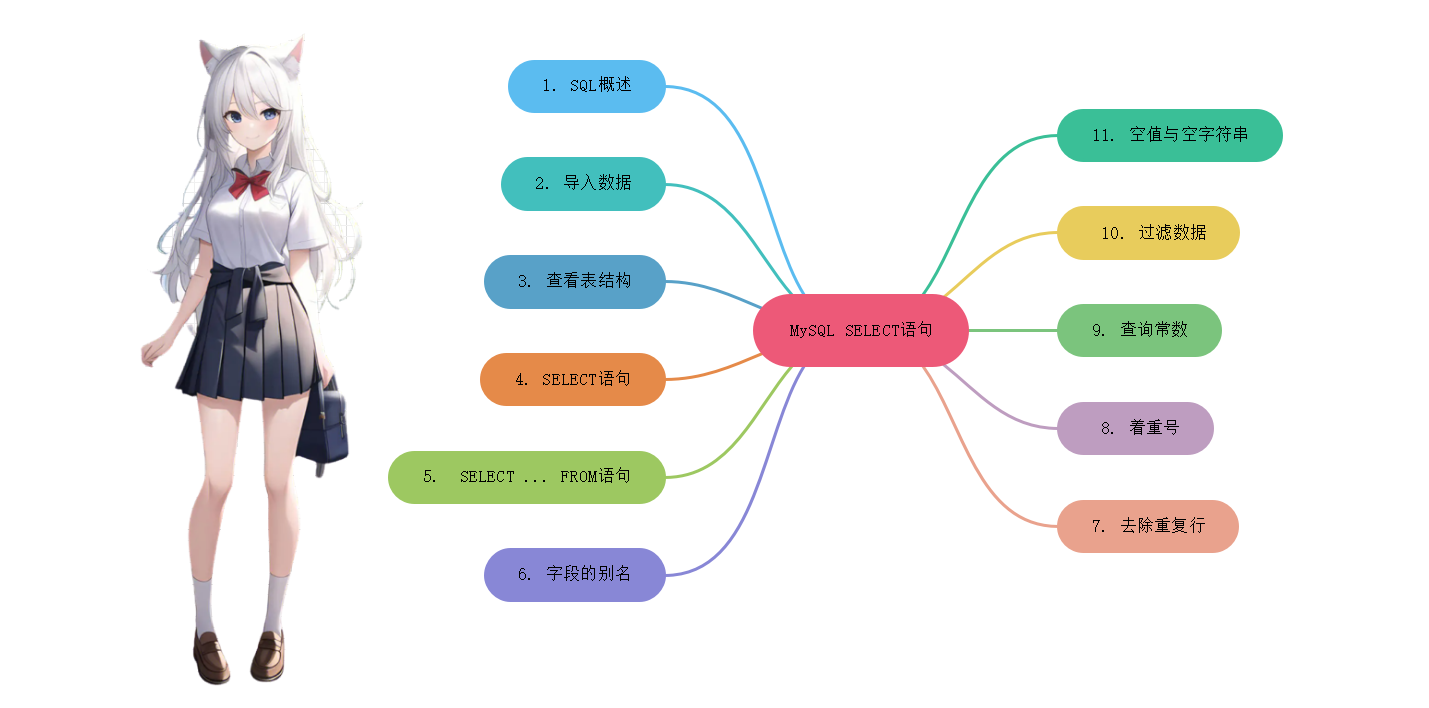
根据应用领域和功能特点 , 可以将SQL分为以下几个主要的分类 :
* 1. 数据定义语言 ( DDL ) : DDL语句用于定义和管理数据库的结构 , 包括创建 , 修改和删除数据库 , 表 , 索引 , 视图等 . 常见的DDL语句包括CREATE , ALTER和DROP等 . * 2. 数据操作语言 ( DML ) : DML语句用于对数据库中的数据进行操作 , 包括查询 , 插入 , 更新和删除数据 . 常见的DML语句包括SELECT , INSERT , UPDATE和DELETE等 . * 3. 数据查询语言 ( DQL ) : DQL语句用于从数据库中提取数据 , 常用于查询和检索数据的需求 . DQL的核心命令是SELECT语句 , 可以通过选择特定的列 , 过滤条件和排序来获取需要的数据 . * 4. 数据控制语言 ( DCL ) : DCL语句用于控制数据库用户的访问权限和数据完整性 , 包括授权和回收权限 , 事务处理和数据约束等 . 常见的DCL语句包括GRANT , REVOKE和COMMIT等 . * 5. 事务控制语言 ( TCL ) : TCL语句用于管理和控制事务 , 可用于维护数据的一致性和完整性 . 常见的TCL语句包括BEGIN TRANSACTION , COMMIT和ROLLBACK等 . * 6. 数据库管理语言 ( DML ) : DML语句用于管理数据库的元数据 , 包括数据库 , 表和索引的创建 , 修改和删除 . 常见的DML语句包括CREATE DATABASE , CREATE TABLE和CREATE INDEX等 . 除了以上分类 , 还有其他一些衍生的SQL语言和扩展 , 如存储过程语言 ( 如PL / SQL和T-SQL ) , 面向对象数据库语言 ( 如SQL / OLB ) 等 ,
它们通过扩展SQL的功能 , 提供了更强大和灵活的数据库操作能力 .
当涉及到使用SQL语言时 , 遵守一些规则和规范是至关重要的 .
遵守以下的规则和规范将有助于提高SQL代码的可读性 , 可维护性和一致性 .
以下是SQL语言的一些常用规则和约定 :
* 1. 编写风格 : - 为了增加可读性 , 可以将SQL语句写在一行或多行 , 并使用适当的缩进 . - 每条命令应以分号 ( ; ) , \ g或 \ G结束 , 标志着命令的结束 .
SELECT column1, column2
FROM table_name
WHERE condition;
* 2. 标点符号 : - 必须使用成对的括号 , 单引号和双引号 , 并正确结束 . - 在输入SQL时,请使用英文状态下的半角输入方式。 - 用单引号表示字符串型和日期时间类型的数据 . ( 双引号可以使用 , 但是不推荐 . ) - 可以使用双引号 ( "" ) 给列取别名 , 并尽使用as关键字取别名 . ( 单引号可以使用 , 但是不推荐 . )
SELECT id AS 编号, name AS 姓名 FROM t_stu;
SELECT id 编号, name 姓名 FROM t_stu;
SELECT id AS "编 号" , name AS "姓 名" FROM t_stu;
* 3. 大小写规范 ( 建议遵守 ) : - 在Windows环境下 , MySQL对大小写不敏感 ( 因为Windows系统对大小写不敏感 ) ; 在Linux环境下 , MySQL对大小写敏感 . - 数据库名 , 表名 , 表的别名和变量名是区分大小写的 . - SQL关键字 , 函数名 , 列名和列的别名不区分大小写 . - 建议采用统一的书写规范 , 例如数据库名 , 表名 , 表别名 , 字段名和字段别名都使用小写 , 而SQL关键字和函数名则使用大写 .
show databases ;
SHOW DATABASES ;
SELECT column1, column2
FROM table_name
WHERE condition;
* 4. 注释 : - 可以使用适当的注释结构来注释代码 , 增加代码的可读性和可理解性 . - 行级注释 : # 注释单行 ( MySQL特有的方式 ) - 行级注释:-- 注释单行 ( -- 后面必须包含一个空格 ) - 块级注释: / * 注释多行 * /
* 5. 命名规则 : - 数据库名和表名不得超过 30 个字符 , 变量名限制为 29 个字符 . - 对象名只能包含A–Z , a–z , 0 – 9 和下划线 , 共计 63 个字符 . - 对象名中不应包含空格 . - 在同一个MySQL软件中 , 数据库名和表名应保持唯一性 . - 如果字段名与保留字 , 数据库系统或常用方法冲突 , 应使用 ` ` ( 着重号 ) 引起来 .
CREATE CREATE student_info( . . . ) ;
CREATE TABLE ` order` ( ) ;
* 6. 保持字段名和类型的一致性 : - 在为字段命名并指定其数据类型时 , 应确保一致性 . - 如果一个表中的某一字段是整数类型 , 同名字段在其他表中也应保持整数类型 .
CREATE CREATE student( id int , name varchat, . . . )
CREATE CREATE teacher( id int , name varchat, . . . )
首先学习数据的查询 , 这里准备了一张表 , 将数据导入到数据自己MySQL数据库中 .
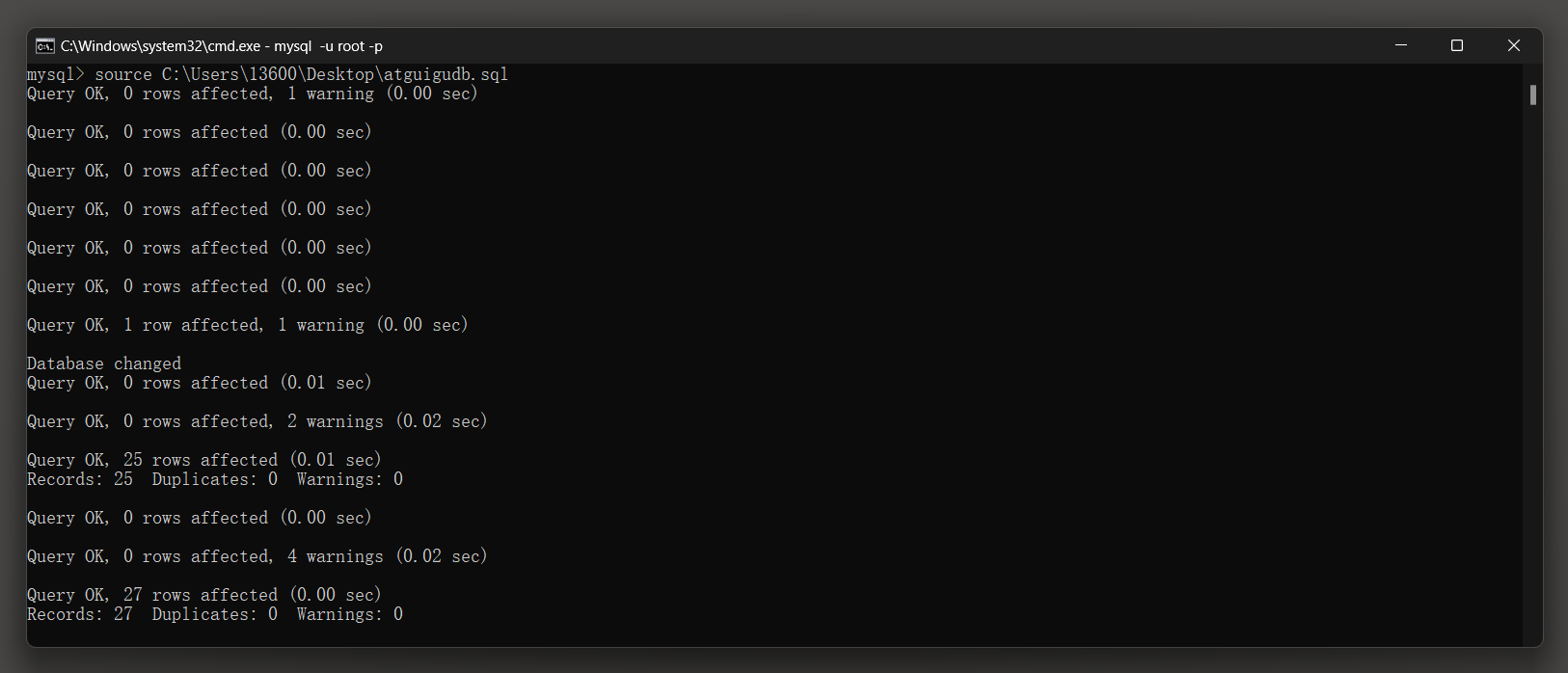
导入数据命令 : source sql文件路径
mysql> source C:\Users\13600 \Desktop\atguigudb. sql
Query OK, 0 rows affected, 1 warning ( 0.00 sec)
. . .
mysql> show databases ;
+
| Database |
+
| atguigudb |
| information_schema |
| mysql |
| performance_schema |
| sys |
| test1 |
+
6 rows in set ( 0.02 sec)
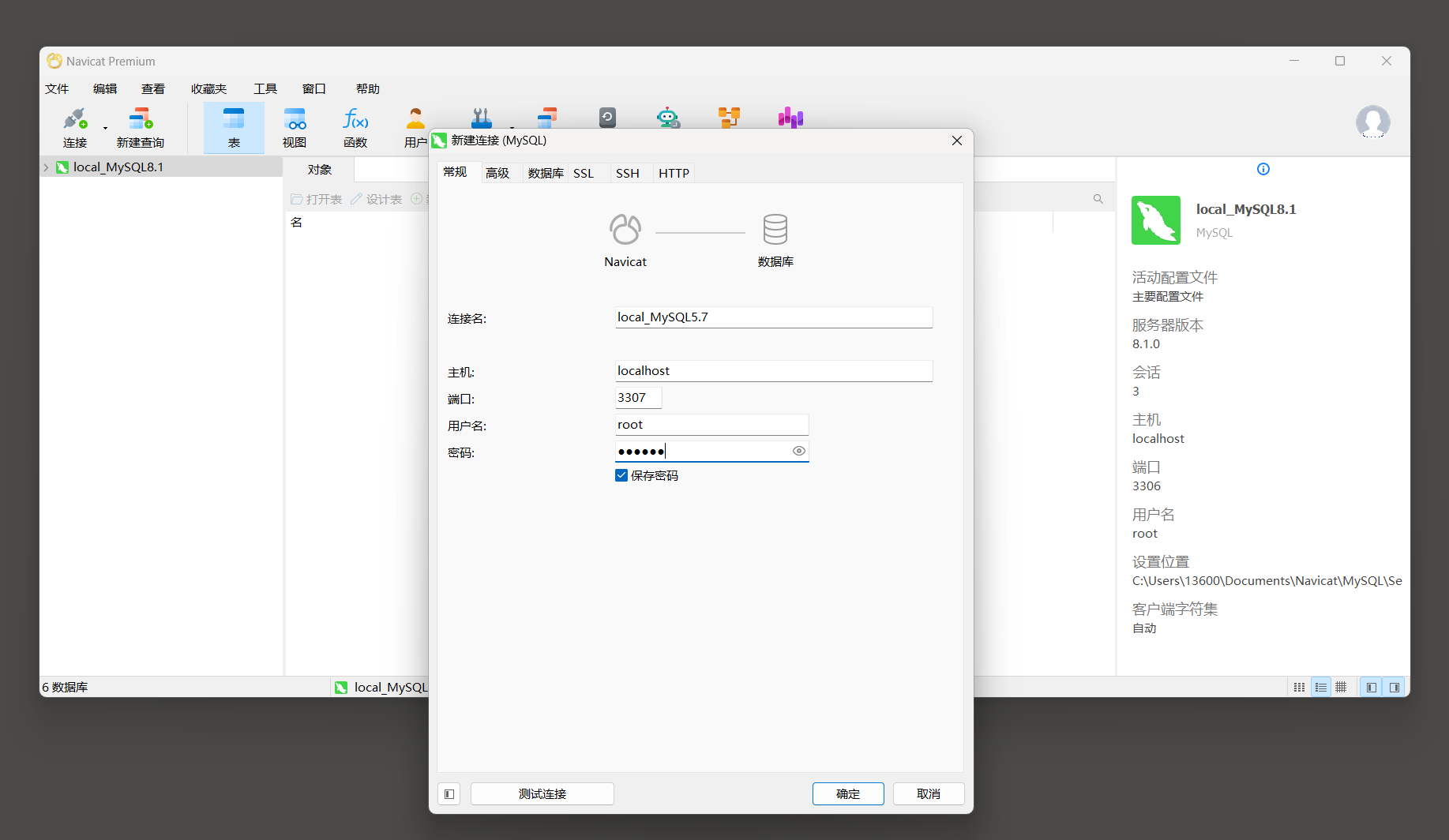
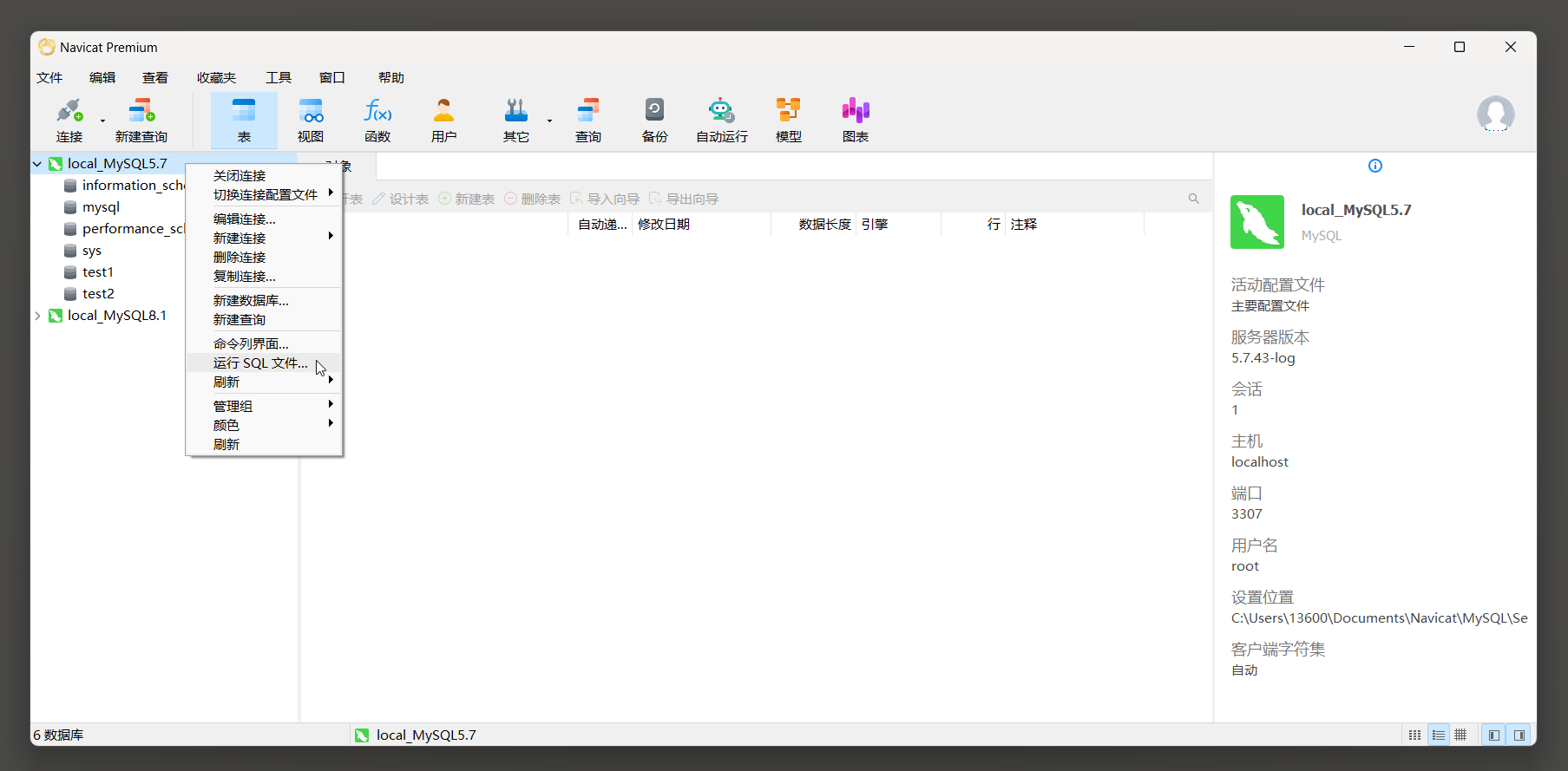
* 1. 先使用Navicat 连接MySQL 5.7 的服务器 .
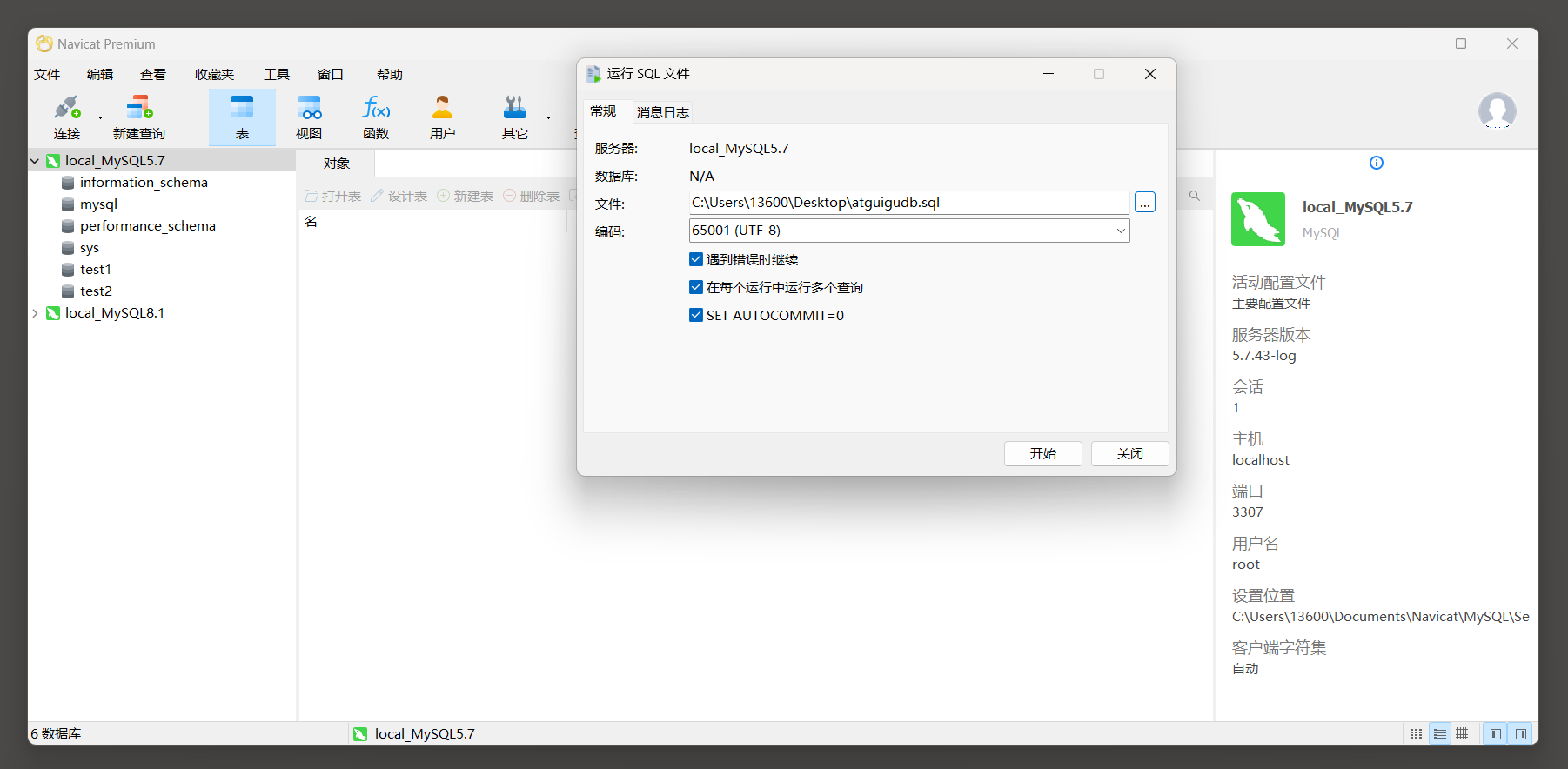
* 2. 选中数据右击选择运行SQL文件 .
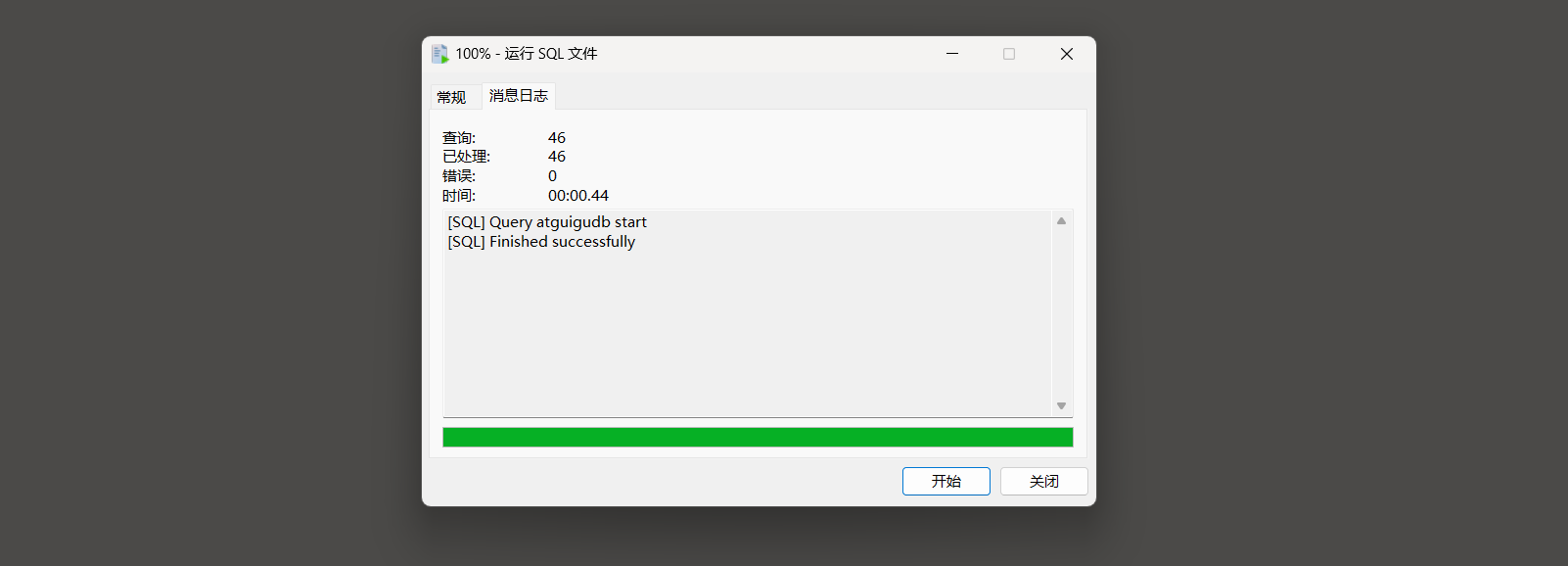
* 3. 选择sql文件的路径 . 点击开始进行导入 .
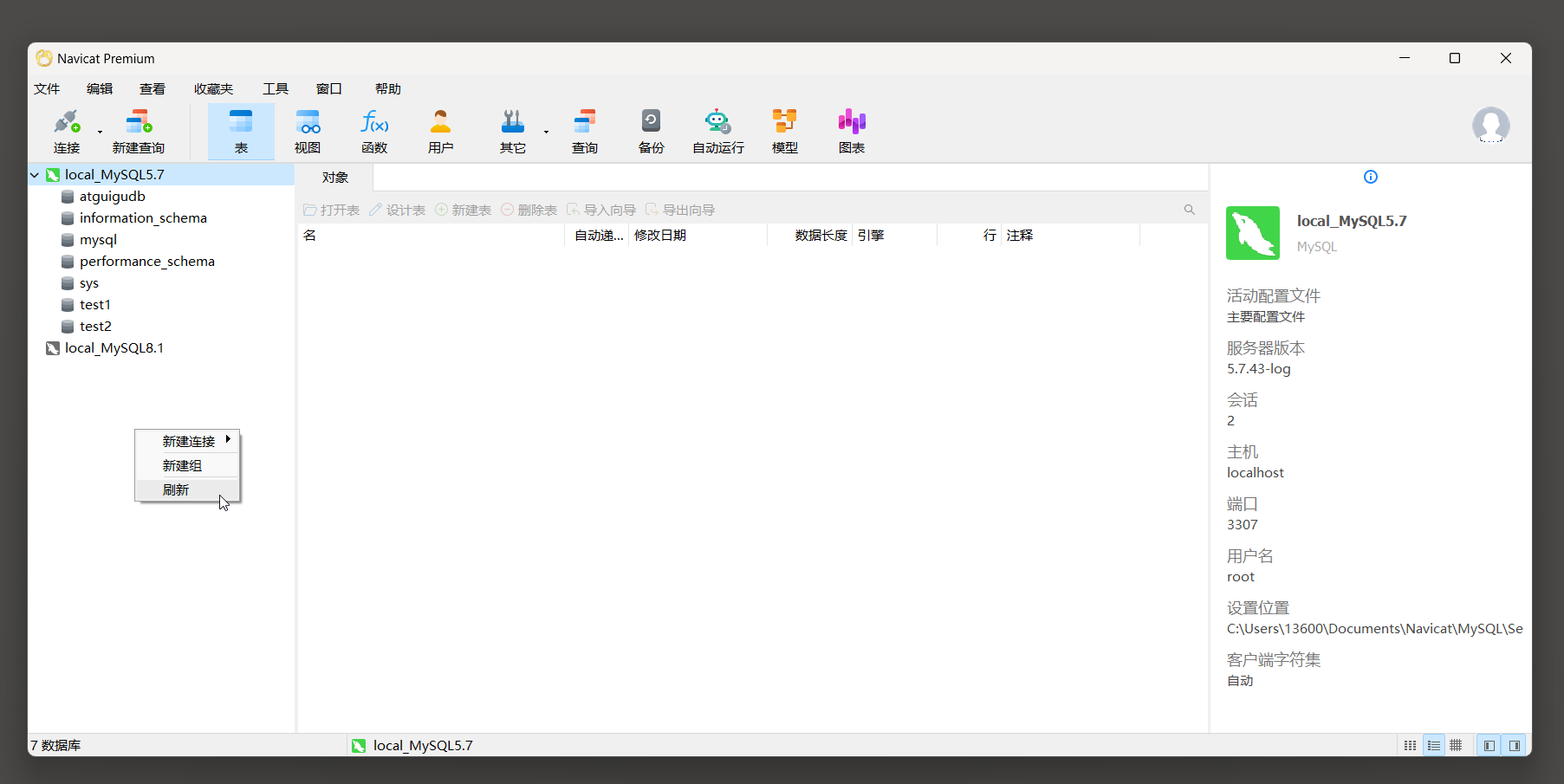
* 4. 导入成功后点开关闭 .
* 5. 刷新后展示数据库 .
查看表结构 : desc 表名称 ;
mysql> use atguigudb
Database changed
mysql> desc employees;
+
| Field | Type | Null | Key | Default | Extra |
+
| employee_id | int | NO | PRI | 0 | |
| first_name | varchar ( 20 ) | YES | | NULL | |
| last_name | varchar ( 25 ) | NO | | NULL | |
| email | varchar ( 25 ) | NO | UNI | NULL | |
| phone_number | varchar ( 20 ) | YES | | NULL | |
| hire_date | date | NO | | NULL | |
| job_id | varchar ( 10 ) | NO | MUL | NULL | |
| salary | double ( 8 , 2 ) | YES | | NULL | |
| commission_pct | double ( 2 , 2 ) | YES | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| department_id | int | YES | MUL | NULL | |
+
11 rows in set ( 0.01 sec)
其中 , 各个字段的含义分别解释如下 :
* 1. Field : 表示字段名称 .
* 2. Type : 表示字段类型 , 这里barcode , goodsname是文本型的 , price是整数类型的 .
* 3. Null : 表示该列是否可以存储NULL值 .
* 4. Key : 表示该列是否已编制索引 . PRI表示该列是表主键的一部分 ; UNI表示该列是UNIQUE索引的一部分 ; MUL表示在列中某个给定值允许出现多次 .
* 6. Default : 表示该列是否有默认值 .
* 6. Extra : 表示可以获取的与给定列有关的附加信息 , 例如AUTO_INCREMENT ( 自动递增主键 ) 等 .
mysql> SELECT 1 ;
+
| 1 |
+
| 1 |
+
1 row in set ( 0.00 sec)
mysql> SELECT 9 / 2 ;
+
| 9 / 2 |
+
| 4.5000 |
+
1 row in set ( 0.00 sec)
SELECT . . . FROM语句有两种语法 :
* 1. 选择全部字段查询语法 : SELECT * FROM 表名 ;
* 2. 选择字段查询语法 : SELECT 字段 1 , . . . FROM 表名 ;
一般情况下 , 除非需要使用表中所有的字段数据 , 最好不要使用通配符 "*" .
使用通配符虽然可以节省输入查询语句的时间 , 但是获取不需要的列数据通常会降低查询和所使用的应用程序的效率 .
通配符的优势是 , 当不知道所需要的列的名称时 , 可以通过它获取它们 .
在生产环境下 , 不推荐你直接使用 SELECT * 进行查询 .
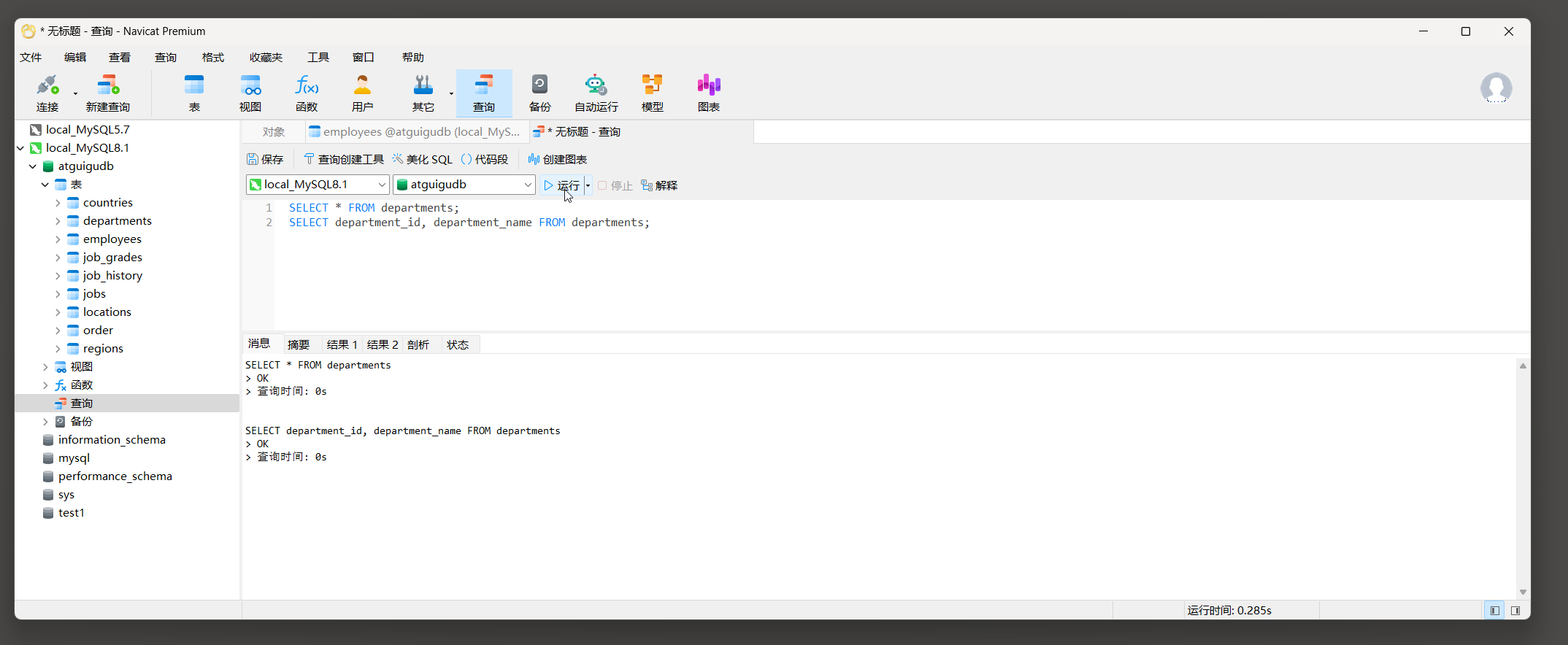
mysql> SELECT * FROM departments;
+
| department_id | department_name | manager_id | location_id |
+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| 30 | Purchasing | 114 | 1700 |
| 40 | Human Resources | 203 | 2400 |
| 50 | Shipping | 121 | 1500 |
| . . . | . . . | . . . | . . . |
| 260 | Recruiting | NULL | 1700 |
| 270 | Payroll | NULL | 1700 |
+
27 rows in set ( 0.00 sec)
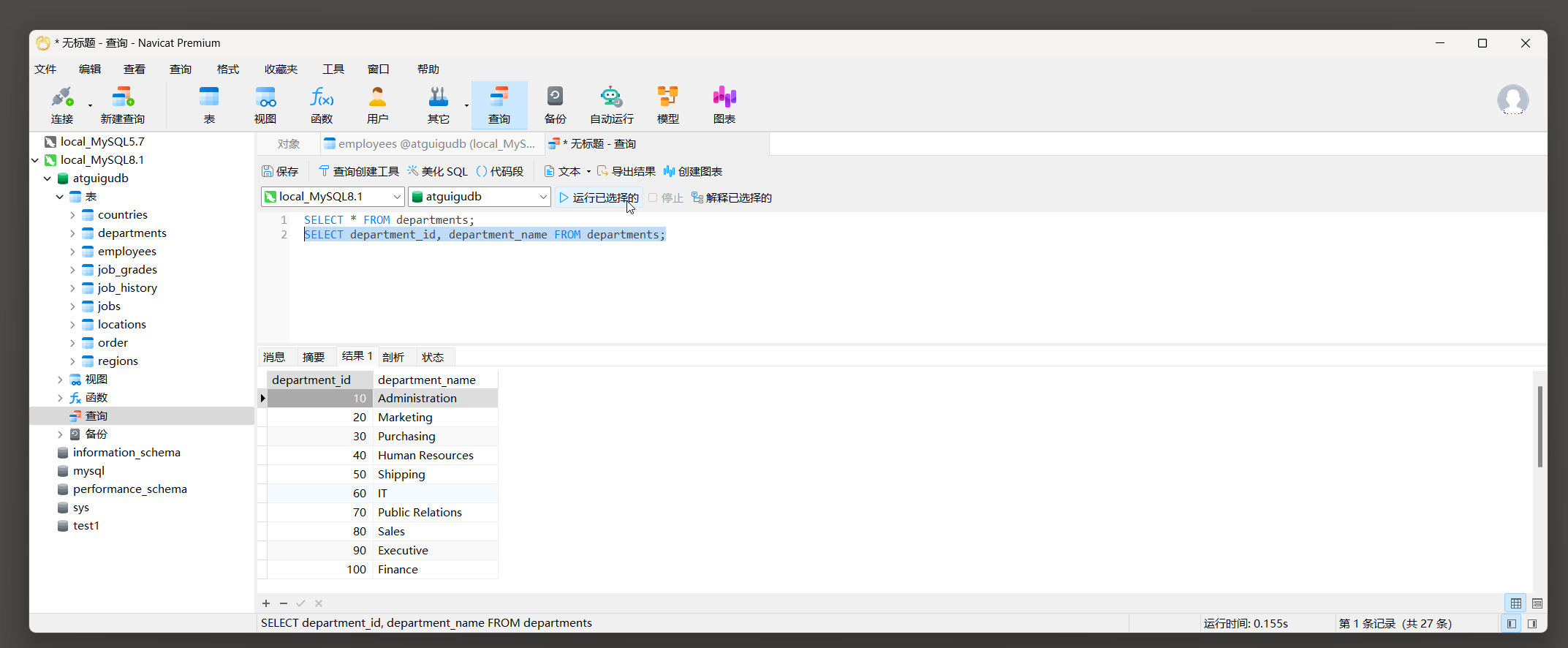
mysql> SELECT department_id, department_name FROM departments;
+
| department_id | department_name |
+
| 10 | Administration |
| 20 | Marketing |
| 30 | Purchasing |
| 40 | Human Resources |
| 50 | Shipping |
| . . . | . . . |
| 260 | Recruiting |
| 270 | Payroll |
+
27 rows in set ( 0.00 sec)
Navicat的查询方式 :
* 1. 点击菜单栏的查询 -- > 点击新建查询 .
* 2. 选择服务器名称与数据库 .
查询方式 1 : 输入命令后点击运行 , 会执行编辑器上所有的命令 . 在下面的信息栏中可以点开结果的信息查看 .
查询方式 2 : 选中想要运行命令 , 这是执行选项会变成运行与选择的命令 .
美化SQL功能 .
给字段起别名的好处主要包括以下几点 :
* 1. 增加可读性 : 别名可以使得数据更易于理解和解释 . 在某些情况下 , 原始字段名可能过于复杂或含糊不清 , 使用别名可以解决这个问题 .
* 2. 简化操作 : 通过给长字段名或复杂字段名设置别名 , 可以简化查询和数据处理的操作 .
* 3. 保护隐私 : 在涉及到敏感数据的情况下 , 别名可以用于隐藏原始字段名 , 从而保护个人隐私 .
* 4. 提高可维护性 : 如果字段名需要更改 , 只需更改别名而无需更改所有相关的查询和代码 , 这可以降低维护成本 .
总的来说 , 别名可以使数据和查询更易于理解 , 使用和维护 .
mysql> SELECT department_id AS dept_id, department_name AS dept_name FROM departments;
+
| dept_id | dept_name |
+
| 10 | Administration |
| 20 | Marketing |
| 30 | Purchasing |
| 40 | Human Resources |
| 50 | Shipping |
| 60 | IT |
| . . . | . . . |
| 270 | Payroll |
+
27 rows in set ( 0.00 sec)
mysql> SELECT first_name "name" , salary * 12 AS "Annual Salary" FROM employees;
+
| name | Annual Salary |
+
| Steven | 288000.00 |
| Neena | 204000.00 |
| Lex | 204000.00 |
| Alexander | 108000.00 |
| Bruce | 72000.00 |
| . . . | . . . |
| Michael | 156000.00 |
| Pat | 72000.00 |
| Susan | 78000.00 |
| Hermann | 120000.00 |
| Shelley | 144000.00 |
| William | 99600.00 |
+
107 rows in set ( 0.00 sec)
默认情况下 , 查询会返回全部行 , 这些行中就可能包含一些重复的信息 .
mysql> SELECT department_id FROM employees;
+
| department_id |
+
| NULL |
| 10 |
| 20 |
| 20 |
| 30 |
| 30 |
| 30 |
|
| 110 |
| 110 |
+
107 rows in set ( 0.00 sec)
在SELECT语句中使用关键字DISTINCT去除重复行 .
mysql> SELECT DISTINCT department_id FROM employees;
+
| department_id |
+
| NULL |
| 10 |
| 20 |
| 30 |
| 40 |
| 50 |
| 60 |
| 70 |
| 80 |
| 90 |
| 100 |
| 110 |
+
12 rows in set ( 0.00 sec)
mysql> SELECT DISTINCT department_id, salary FROM employees;
+
| department_id | salary |
+
| 90 | 24000.00 |
| 90 | 17000.00 |
| 60 | 9000.00 |
| 60 | 6000.00 |
| 60 | 4800.00 |
| 60 | 4200.00 |
| . . | . . . . . |
| 40 | 6500.00 |
| 70 | 10000.00 |
| 110 | 12000.00 |
| 110 | 8300.00 |
+
74 rows in set ( 0.00 sec)
注意事项 :
* 1. DISTINCT 需要放到所有列名的前面 , 如果写成 SELECT salary , DISTINCT department_id FROM employees 会报错 .
* 2. DISTINCT 其实是对后面所有列名的组合进行去重 , 最后的结果是 74 条 , 因为这 74 个部门id不同 , 都有salary这个属性值 . 如果你想要看都有哪些不同的部门 ( department_id ) , 只需要写 DISTINCT department_id即可 , 后面不需要再加其他的列名了 .
设计表名和字段时 , 避免使用数据库的保留字或常用方法名称是非常重要的 .
如果使用这些名称 , 可能会导致SQL查询出现错误或混淆 . 当名称冲突时 , 可以使用反引号 ( ` ) 将表名或字段名括起来 ; 反引号在键盘上通常与波浪号 ( ~ ) 共享一个键 .
mysql> show tables ;
+
| Tables_in_atguigudb |
+
| countries |
| . . . |
| order |
| regions |
+
10 rows in set ( 0.01 sec)
mysql> SELECT * FROM order ;
ERROR 1064 ( 42000 ) : You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version for the right syntax to use near 'order' at line 1 错误 1064 ( 42000 ) : 您的 SQL 语法有误;
请检查与您的 MySQL 服务器版本相对应的手册, 以了解在第 1 行 'order' 附近应使用的正确语法.
mysql> SELECT * FROM ` order` ;
+
| order_id | order_name |
+
| 1 | shkstart |
| 2 | tomcat |
| 3 | dubbo |
+
3 rows in set ( 0.00 sec)
在SQL中 , 可以使用SELECT语句对常数进行查询 , 并在查询结果中添加一列固定的常数列 .
这样做的原因可能是为了整合不同的数据源 , 并使用常数列作为表的标记 . 如果你想对employees数据表中的员工的姓进行查询 ,
同时增加一列字段corporation ( 团队 ) , 这个字段的固定值为 'MySQL' , 可以使用以下查询语句 :
mysql> SELECT 'MySQL' AS corporation, last_name FROM employees;
+
| corporation | last_name |
+
| MySQL | King |
| MySQL | Kochhar |
| MySQL | De Haan |
| MySQL | Hunold |
| MySQL | Ernst |
| . . . | . . . |
| MySQL | Higgins |
| MySQL | Gietz |
+
107 rows in set ( 0.00 sec)
可以使用WHERE子句 , 将不满足条件的行过滤掉 .
注意事项 : WHERE子句紧随FROM子句 语法 : SELECT 字段 1 , 字段 2 , . . . FROM 表名 WHERE 过滤条件 ;
mysql> SELECT - > employee_id, - > first_name, - > job_id, - > department_id - > FROM - > employees- > WHERE - > department_id = 90 ;
+
| employee_id | first_name | job_id | department_id |
+
| 100 | Steven | AD_PRES | 90 |
| 101 | Neena | AD_VP | 90 |
| 102 | Lex | AD_VP | 90 |
+
3 rows in set ( 0.00 sec) MySQL中 , 空值 ( NULL ) 和空字符串 ( "" ) 是两种不同的概念 , 具有不同的特性和用法 . * 1. 空值 : 表示数据项不存在或未知 . 在MySQL中 , NULL是一种特殊的标记 , 表示字段或数据项没有值或值未知 . 当一个字段被设置为NULL时 , 表示该字段没有存储任何有效的数据 . 在存储NULL值的字段上 , 不会分配任何实际的存储空间 . 相反 , MySQL会在记录中存储一个指示该字段为NULL的标记 . 在查询中 , 需要使用 IS NULL 或 IS NOT NULL 运算符来判断某列是否为空值 , 例如 : SELECT * FROM table WHERE column IS NULL . * 2. 空字符串 : 则表示一个字符串中没有任何字符 , 即长度为 0 的字符串 . 它是一个实际存在的值 , 但与NULL不同 , 空字符串是一个有效的数据项 . 在查询中 , 空字符串可以与其他字符串进行比较 , 例如 : SELECT * FROM table WHERE column = "" . 空字符串对于可变长度字符串类型会占用 1 个字节的存储空间 , 而对于固定长度字符串类型则会占用字段定义的存储空间 . 以下是空值和空字符串的一些区别 :
存储空间 : NULL不需要占用实际的存储空间 , 而空字符串 ( "" ) 需要占用一定的存储空间 , 因为它是一个实际存在的值 .
数据比较 : 在MySQL中 , NULL不能和任何其他值进行直接比较 , 包括自身 . 而空字符串 ( "" ) 可以进行比较操作 .
数据处理 : 在进行数据插入或更新操作时 , 如果没有为字段指定值 , MySQL将默认将其设置为NULL , 而不是空字符串 ( "" ) .
空值与任何其他值进行运算的结果通常都是NULL .
这是因为空值表示缺失或未知的值 , 因此无法与其他值进行准确的运算 .
mysql> SELECT - > employee_id, - > salary, - > commission_pct, - > 12 * salary * ( 1 + commission_pct) - > AS - > "annual_sal" - > FROM - > employees;
+
| employee_id | salary | commission_pct | annual_sal |
+
| 100 | 24000.00 | NULL | NULL |
| . . . | . . . | . . . | . . . |
| 145 | 14000.00 | 0.40 | 235200.00 |
+
107 rows in set ( 0.00 sec)
如果commission_pct的值可能为NULL , 那么在计算年薪时可能会出现问题 , 因为NULL值会导致计算结果也是NULL .
为了处理这种情况 , 可以使用COALESCE函数或IFNULL函数来将NULL值替换为 0 或其他默认值 .
例 : COALESCE ( commission_pct , 0 ) , 如果commission_pct的值为NULL , 则返回 0 ; 否则返回commission_pct本身的值 .
这样可以确保在计算年薪时不会因为NULL值而出现错误 . 以下是使用COALESCE函数修改后的查询语句 :
mysql> SELECT - > employee_id, - > salary, - > commission_pct, - > 12 * salary * ( 1 + COALESCE ( commission_pct, 0 ) ) - > AS - > "annual_sal" - > FROM - > employees;
+
| employee_id | salary | commission_pct | annual_sal |
+
| 100 | 24000.00 | NULL | 288000.00 |
| . . . | . . . | . . . | . . . |
| 145 | 14000.00 | 0.40 | 235200.00 |
+
* 1. 查询员工 12 个月的工资总和 , 并起别名为ANNUAL SALARY .
mysql> SELECT - > 12 * salary * ( 1 + COALESCE ( commission_pct, 0 ) ) - > AS - > "ANNUAL SALARY" - > FROM - > employees;
+
| ANNUAL SALARY |
+
| 288000.00 |
| 204000.00 |
| 204000.00 |
| 108000.00 |
| . . . |
+
107 rows in set ( 0.02 sec)
* 2. 查询employees表中去除重复的job_id以后的数据 .
mysql> SELECT DISTINCT - > job_id- > FROM - > employees;
+
| job_id |
+
| AC_ACCOUNT |
| AC_MGR |
| AD_ASST |
| . . . |
| SA_REP |
| SH_CLERK |
| ST_CLERK |
| ST_MAN |
+
19 rows in set ( 0.01 sec)
* 3. 查询工资大于 12000 的员工姓名和工资 .
mysql> SELECT - > first_name, - > last_name, - > salary- > FROM - > employees- > WHERE - > salary > 12000 ;
+
| first_name | last_name | salary |
+
| Steven | King | 24000.00 |
| Neena | Kochhar | 17000.00 |
| Lex | De Haan | 17000.00 |
| John | Russell | 14000.00 |
| Karen | Partners | 13500.00 |
| Michael | Hartstein | 13000.00 |
+
6 rows in set ( 0.00 sec)
* 4. 查询员工号为 176 的员工的姓名和部门号 .
mysql> SELECT - > first_name, - > last_name, - > department_id- > FROM - > employees- > WHERE - > employee_id = 176 ;
+
| first_name | last_name | department_id |
+
| Jonathon | Taylor | 80 |
+
1 row in set ( 0.01 sec)
* 5. 显示表departments的结构 , 并查询其中的全部数据 .
mysql> DESC departments;
+
| Field | Type | Null | Key | Default | Extra |
+
| department_id | int | NO | PRI | 0 | |
| department_name | varchar ( 30 ) | NO | | NULL | |
| manager_id | int | YES | MUL | NULL | |
| location_id | int | YES | MUL | NULL | |
+
4 rows in set ( 0.00 sec) mysql> SELECT - > * - > FROM - > departments;
+
| department_id | department_name | manager_id | location_id |
+
| 10 | Administration | 200 | 1700 |
| 20 | Marketing | 201 | 1800 |
| . . . | . . . | . . . | . . . |
| 270 | Payroll | NULL | 1700 |
+
27 rows in set ( 0.01 sec)















)

)
软件构造)

