文章目录
- I、项目任务要求
- II、原理描述
- KMeans
- KMeans++
- 二分K均值
- 评价指标-轮廓系数
- III、数据集描述
- IV、具体实现过程
- V、结果分析
- VI、完整代码
- VII、深度学习与图片分割(补充)
- CNN
- 1. 卷积层(Convolutional Layer):
- 2. 激活函数(Activation Function):
- 3. 池化层(Pooling Layer):
- 4. 全连接层(Fully Connected Layer):
- 工作原理:
- 分割效果
I、项目任务要求
- 图像分割 是图像处理和计算机视觉中重要的一环,在实际生活中得到了广泛的应用。例如:
- 在医学上,用于测量医学图像中组织体积、三维重建、手术模拟等;
- 在遥感图像中,分割合成孔径雷达图像中的目标、提取遥感云图中不同云系与背景等、定位卫星图像中的道路和森林等。
- 图像分割也可作为预处理将最初的图像转化为若干个更加抽象、更便于计算机处理的形式,既保留了图像中的重要特征信息,又有效减少了图像中的无用数据、提高了后续图像处理的准确率和效率。例如:
- 在通信方面,可事先提取目标的轮廓结构、区域内容等,保证不失有用信息的同时,有针对性地压缩图像,以提高网络传输效率;
- 在交通领域可用来对车辆进行轮廓提取、识别或跟踪,行人检测等。
- 总的来说,凡是与目标的检测、提取和识别等相关的内容,都需要利用到图像分割技术。因此,无论是从图像分割的技术和算法,还是从对图像处理、计算机视觉的影响以及实际应用等各个方面来深入研究和探讨图像分割,都具有十分重要的意义。
- 聚类技术 是图像分割技术中重要组成部分,其中特征空间聚类法,如Kmeans算法及其相应变体是划分聚类方法中的典范。利用特征空间聚类法进行图像分割是将图像空间中的像素用对应的特征空间点表示,根据它们在特征空间的聚集对特征空间进行分割,然后将它们映射回原图像空间,得到分割结果。
任务描述
- 本次实验利用图像的灰度、颜色、纹理、形状等特征,把图像分成若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域之间存在明显的差异性。然后就可以将分割的图像中具有独特性质的区域提取出来用于不同的研究。
- 实验内容:分别用Kmeans、Kmeans++和二分K均值三种聚类方法对图片进行图像分割,并写出实验结果分析。
主要任务要求
- 简述三种算法思想和实现原理。
- 小组每人准备一张自己喜欢的图片(图片种类多样化)
- 写出实验结果分析:
- 实验运行环境描述。如开发平台、编程语言、调参情况等。
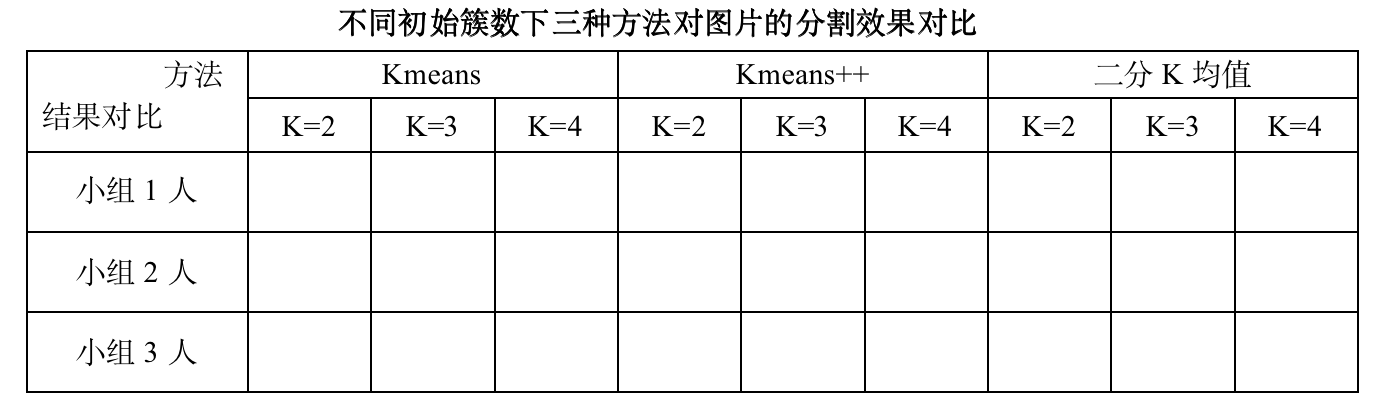
- 不同初始簇数下三种方法对图片的分割效果对比、分析。
- 对比表样式如下所示,可将分割效果图分别粘贴到对应位置;
- 采用轮廓系数(或其它评价指标)评估三种方法的聚类效果(见参考资料网址);
- 结合对比表(表样如下)结果和评估结果对实验结果进行分析说明。
II、原理描述
KMeans
KMeans++
二分K均值
评价指标-轮廓系数
III、数据集描述
IV、具体实现过程
V、结果分析




VI、完整代码
import numpy as np
import PIL.Image as Image
from sklearn.cluster import KMeans, Birch
from sklearn.metrics import silhouette_score, pairwise_distances
import matplotlib.pyplot as plt# 设置Matplotlib的文本渲染器和支持中文字符的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 或者 ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False # 用于显示负号(-)的正常显示# Todo: 准备数据集 ------------------------------------------------------------
# todo: 定义函数loadData来处理图片
# 常量
NORMALIZATION_FACTOR = 256# todo: 加载数据的函数
def load_data(file_path):with open(file_path, 'rb') as f:img = Image.open(f)m, n = img.sizedata = []for i in range(m):for j in range(n):x, y, z = img.getpixel((i, j))data.append([x / NORMALIZATION_FACTOR, y / NORMALIZATION_FACTOR, z / NORMALIZATION_FACTOR])return np.asarray(data), m, n# Todo: 计算轮廓系数的函数 ------------------------------------------------------------
def silhouette_coefficient(X, labels):cluster_centers = [np.mean(X[labels == i], axis=0) for i in range(len(set(labels)))]distances = pairwise_distances(X, cluster_centers)a = np.array([np.mean(distances[labels == i, i]) for i in range(len(set(labels)))])b = np.array([np.min(distances[labels != i, i]) for i in range(len(set(labels)))])s = (b - a) / np.maximum(a, b)return np.mean(s)# Todo: 使用KMeans、KMeans++和二分K均值进行图像分割 ------------------------------------------------------------
# 加载图片并处理
image_paths = ["data/demo3/input/img1.jpg","data/demo3/input/img2.jpg","data/demo3/input/img3.jpg","data/demo3/input/img4.jpg"]k_values = [2, 3, 4]# 初始化轮廓系数列表
kmeans_silhouette_scores = []
kmeans_plus_silhouette_scores = []
birch_silhouette_scores = []print("使用KMeans、KMeans++和二分K均值进行图像分割")
# 分割图片并计算轮廓系保存分割图片
for k in k_values:kmeans_scores = []kmeans_plus_scores = []birch_scores = []for idx, path in enumerate(image_paths):img_data, rows, cols = load_data(path)# 计算KMeans聚类的轮廓系数kmeans_labels = KMeans(n_clusters=k, init='random', n_init=10).fit_predict(img_data)kmeans_silhouette_avg = silhouette_coefficient(img_data, kmeans_labels.flatten())kmeans_scores.append(kmeans_silhouette_avg)# 计算KMeans++聚类的轮廓系数kmeans_plus_labels = KMeans(n_clusters=k, init='k-means++', n_init=10).fit_predict(img_data)kmeans_plus_silhouette_avg = silhouette_coefficient(img_data, kmeans_plus_labels.flatten())kmeans_plus_scores.append(kmeans_plus_silhouette_avg)# 计算二分K均值聚类的轮廓系数birch_labels = Birch(n_clusters=k, threshold=0.01, branching_factor=50).fit_predict(img_data)birch_silhouette_avg = silhouette_coefficient(img_data, birch_labels.flatten())birch_scores.append(birch_silhouette_avg)print(f"使用{k}个聚类中心的K均值聚类对图片{idx + 1}的轮廓系数为: {kmeans_silhouette_avg}")print(f"使用{k}个聚类中心的K++均值聚类对图片{idx + 1}的轮廓系数为: {kmeans_plus_silhouette_avg}")print(f"使用{k}个聚类中心的二分K均值聚类对图片{idx + 1}的轮廓系数为: {birch_silhouette_avg}")# 保存分割的图片kmeans_output_path = f"data/demo3/output/KMeans{k}-{idx + 1}.jpg"kmeans_plus_output_path = f"data/demo3/output/KMeans++{k}-{idx + 1}.jpg"birch_output_path = f"data/demo3/output/Birch{k}-{idx + 1}.jpg"segmented_img_kmeans = np.reshape(kmeans_labels, (rows, cols))segmented_img_kmeans = (segmented_img_kmeans * 255 / k).astype(np.uint8)segmented_img_kmeans = Image.fromarray(segmented_img_kmeans)segmented_img_kmeans.save(kmeans_output_path)segmented_img_kmeans_plus = np.reshape(kmeans_plus_labels, (rows, cols))segmented_img_kmeans_plus = (segmented_img_kmeans_plus * 255 / k).astype(np.uint8)segmented_img_kmeans_plus = Image.fromarray(segmented_img_kmeans_plus)segmented_img_kmeans_plus.save(kmeans_plus_output_path)segmented_img_birch = np.reshape(birch_labels, (rows, cols))segmented_img_birch = (segmented_img_birch * 255 / k).astype(np.uint8)segmented_img_birch = Image.fromarray(segmented_img_birch)segmented_img_birch.save(birch_output_path)# 计算平均轮廓系数mean_kmeans_score = np.mean(kmeans_scores)mean_kmeans_plus_score = np.mean(kmeans_plus_scores)mean_birch_score = np.mean(birch_scores)# 存储平均轮廓系数kmeans_silhouette_scores.append(mean_kmeans_score)kmeans_plus_silhouette_scores.append(mean_kmeans_plus_score)birch_silhouette_scores.append(mean_birch_score)# Todo: 可视化KMeans、KMeans++和二分K均值聚类的轮廓系数 ------------------------------------------------------------
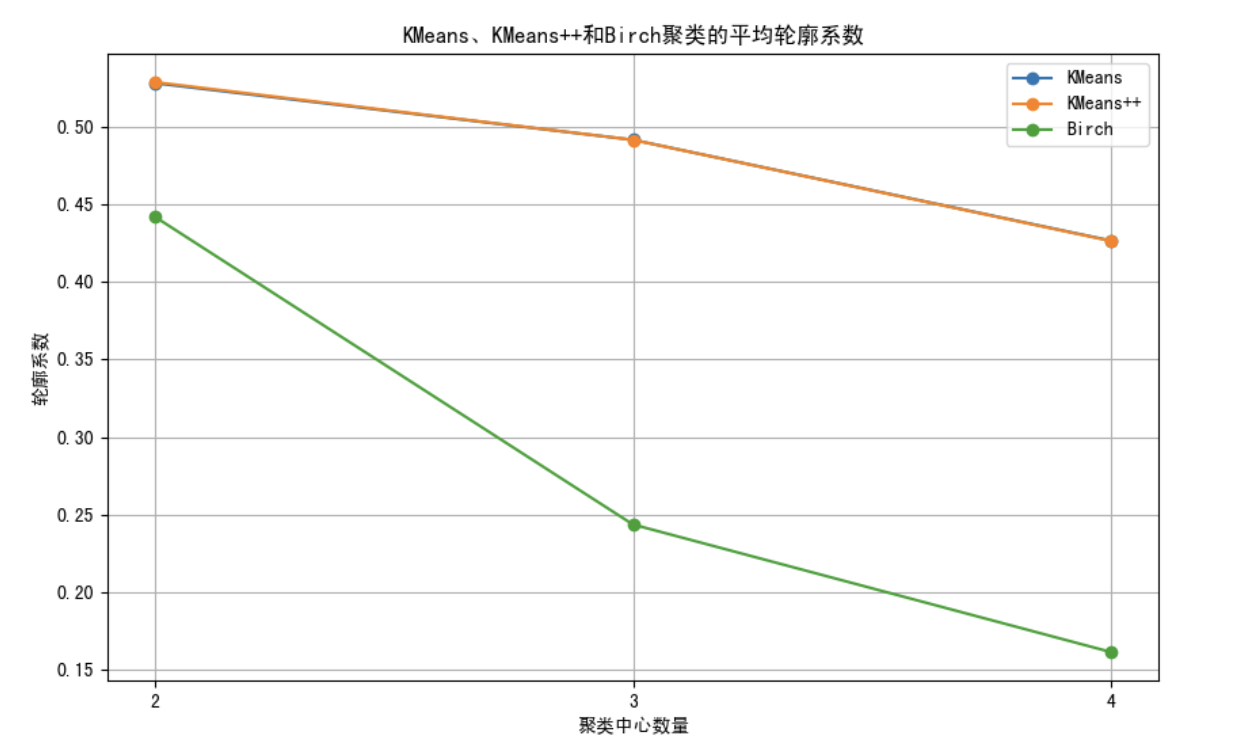
print("【平均轮廓系数】")
print(f"K均值:{kmeans_silhouette_scores}")
print(f"K++均值:{kmeans_plus_silhouette_scores}")
print(f"二分K均值:{birch_silhouette_scores}")plt.figure(figsize=(10, 6))
plt.plot(k_values, kmeans_silhouette_scores, marker='o', label='KMeans')
plt.plot(k_values, kmeans_plus_silhouette_scores, marker='o', label='KMeans++')
plt.plot(k_values, birch_silhouette_scores, marker='o', label='Birch')
plt.xlabel('聚类中心数量')
plt.ylabel('轮廓系数')
plt.title('KMeans、KMeans++和Birch聚类的平均轮廓系数')
plt.xticks(k_values)
plt.legend()
plt.grid(True)
plt.show()# Todo: 可视化聚类结果 ------------------------------------------------------------
plt.figure(figsize=(12, 8))
for i, k in enumerate(k_values):plt.subplot(1, len(k_values), i + 1)for idx, path in enumerate(image_paths):segmented_img = Image.open(f"data/demo3/output/KMeans{k}-{idx + 1}.jpg")plt.imshow(segmented_img, cmap='gray')plt.axis('off')plt.title(f'KMeans 聚类结果\n(聚类数:{k})')plt.show()plt.figure(figsize=(12, 8))
for i, k in enumerate(k_values):plt.subplot(1, len(k_values), i + 1)for idx, path in enumerate(image_paths):segmented_img = Image.open(f"data/demo3/output/KMeans++{k}-{idx + 1}.jpg")plt.imshow(segmented_img, cmap='gray')plt.axis('off')plt.title(f'KMeans++ 聚类结果\n(聚类数:{k})')plt.show()plt.figure(figsize=(12, 8))
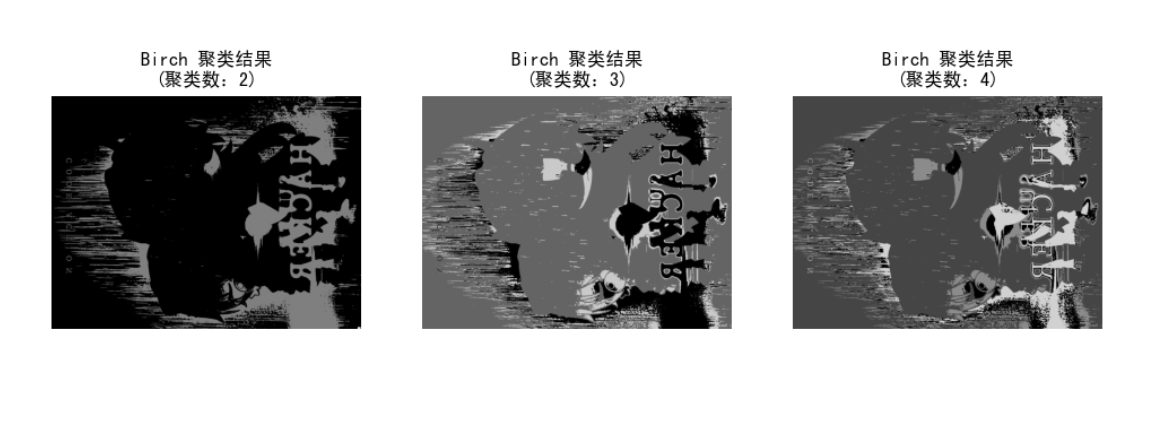
for i, k in enumerate(k_values):plt.subplot(1, len(k_values), i + 1)for idx, path in enumerate(image_paths):segmented_img = Image.open(f"data/demo3/output/Birch{k}-{idx + 1}.jpg")plt.imshow(segmented_img, cmap='gray')plt.axis('off')plt.title(f'Birch 聚类结果\n(聚类数:{k})')plt.show()VII、深度学习与图片分割(补充)
CNN
卷积神经网络(CNN)是一种专门用于处理网格状数据(比如图像和视频)的深度学习模型。CNN在图像识别、物体检测、图像生成等任务上取得了很大的成功,它的核心特点是可以自动从数据中学习到特征,而不需要手动设计特征提取器。
以下是CNN的主要组成部分和工作原理:
1. 卷积层(Convolutional Layer):
卷积层是CNN的核心。它使用卷积操作来提取图像中的特征。卷积操作通过一个小的窗口(卷积核)在输入图像上滑动,计算每个窗口内的值,然后生成输出特征图。这种操作可以捕捉到图像中的局部特征,因此非常适合处理图像数据。
2. 激活函数(Activation Function):
激活函数引入了非线性性质,使得网络可以学习复杂的模式。常用的激活函数包括ReLU(Rectified Linear Unit)函数,Sigmoid函数和TanH函数。
3. 池化层(Pooling Layer):
池化层用于减小特征图的空间尺寸,同时保留重要的特征。最常见的池化操作是最大池化(Max Pooling),它选择每个区域内的最大值作为输出,从而减小特征图的大小。
4. 全连接层(Fully Connected Layer):
全连接层将前面卷积层和池化层提取到的特征映射转化为网络最终的输出。全连接层的每个神经元与前一层的所有神经元相连接,通过学习权重来进行特征的组合和分类。
工作原理:
-
输入数据:CNN的输入通常是一个三维数组,表示图像的高度、宽度和通道数(比如RGB图像有三个通道,灰度图像只有一个通道)。
-
卷积和激活:输入数据经过卷积层和激活函数,得到一系列特征图,每个特征图代表不同的特征。
-
池化:特征图通过池化层进行下采样,减小空间尺寸,同时保留重要特征。
-
全连接:池化层的输出被展开成一个一维向量,输入到一个或多个全连接层中,进行分类或回归等任务。
CNN的主要优势在于它可以自动学习到输入数据中的空间结构特征,而不需要手动设计特征提取器。这使得它在图像识别等任务上表现得非常出色。







![[一带一路金砖 2023 CTF]Crypto](http://pic.xiahunao.cn/[一带一路金砖 2023 CTF]Crypto)

)








)
