深度学习基础知识 BatchNorm、LayerNorm、GroupNorm的用法解析
- 1、BatchNorm
- 2、LayerNorm
- 3、GroupNorm
- 用法:
BatchNorm、LayerNorm 和 GroupNorm 都是深度学习中常用的归一化方式。
它们通过将输入归一化到均值为 0 和方差为 1 的分布中,来防止梯度消失和爆炸,并提高模型的泛化能力
1、BatchNorm

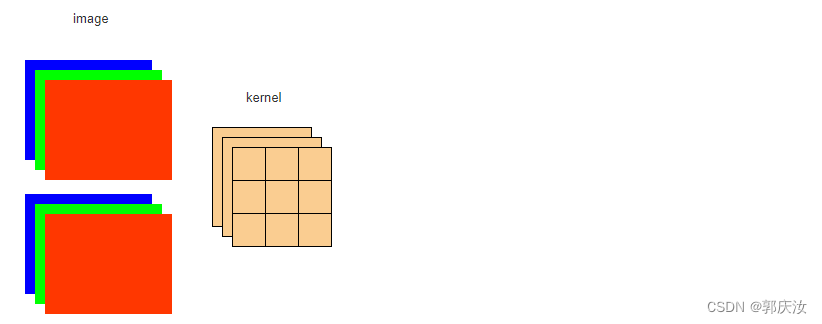


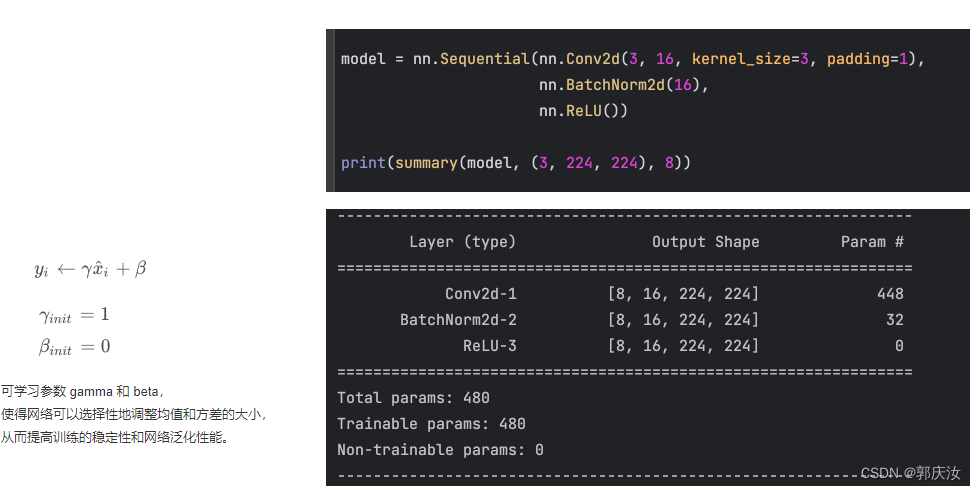
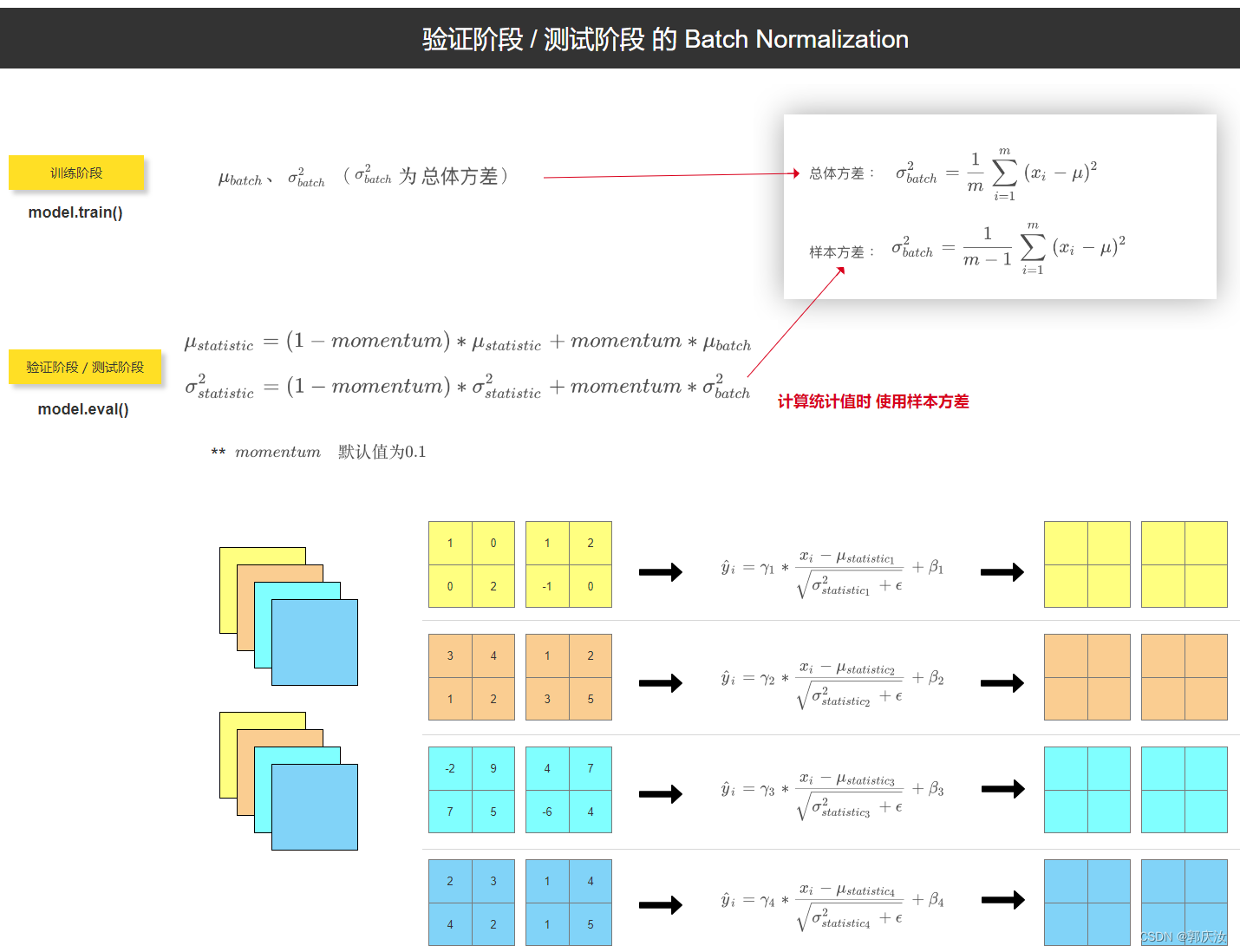
import numpy as np
import torch.nn as nn
import torchdef bn_process(feature, mean, var):feature_shape = feature.shapefor i in range(feature_shape[1]):# [batch, channel, height, width]feature_t = feature[:, i, :, :] # 得到每一个channel的height和widthmean_t = feature_t.mean()# 总体标准差std_t1 = feature_t.std()# 样本标准差std_t2 = feature_t.std(ddof=1)# bn process# 这里记得加上eps和pytorch保持一致feature[:, i, :, :] = (feature[:, i, :, :] - mean_t) / np.sqrt(std_t1 ** 2 + 1e-5)# update calculating mean and varmean[i] = mean[i] * 0.9 + mean_t * 0.1var[i] = var[i] * 0.9 + (std_t2 ** 2) * 0.1print(feature)# 随机生成一个batch为2,channel为2,height=width=2的特征向量
# [batch, channel, height, width]
feature1 = torch.randn(2, 2, 2, 2)
# 初始化统计均值和方差
calculate_mean = [0.0, 0.0]
calculate_var = [1.0, 1.0]
# print(feature1.numpy())# 注意要使用copy()深拷贝
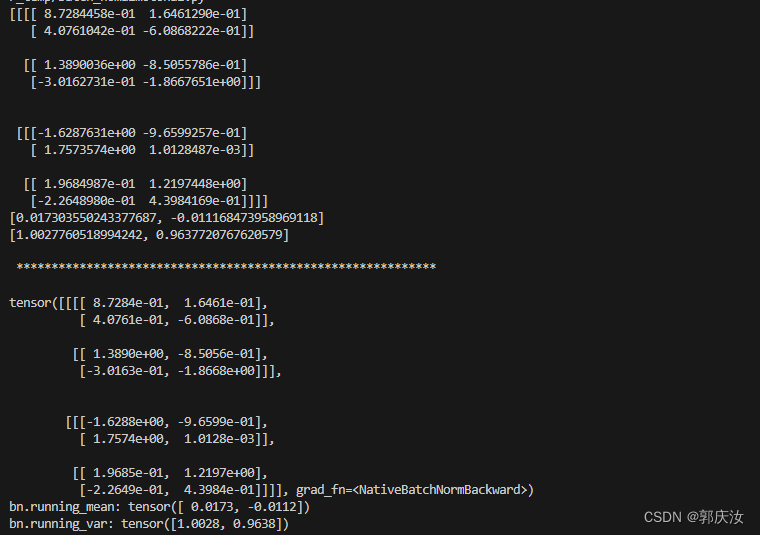
bn_process(feature1.numpy().copy(), calculate_mean, calculate_var)bn = nn.BatchNorm2d(2, eps=1e-5)
output = bn(feature1)
print(output)显示结果如下:

代码:
import torch
import torch.nn as nn
import numpy as npfeatuer_array=(np.random.rand(2,4,2,2)).astype(np.float32)
print(featuer_array.dtype)featuer_tensor=torch.tensor(featuer_array,dtype=torch.float32)
bn_out=nn.BatchNorm2d( num_features=featuer_array.shape[1],eps=1e-5)(featuer_tensor)
print(bn_out)print("-----")for i in range(featuer_array.shape[1]):channel=featuer_array[:,i,:,:]mean=channel.mean()var=channel.var()print(f"mean---{mean},var---{var}")featuer_array[:,i,:,:]=(channel-mean) / np.sqrt(var + 1e-5)
print(featuer_array)打印结果:
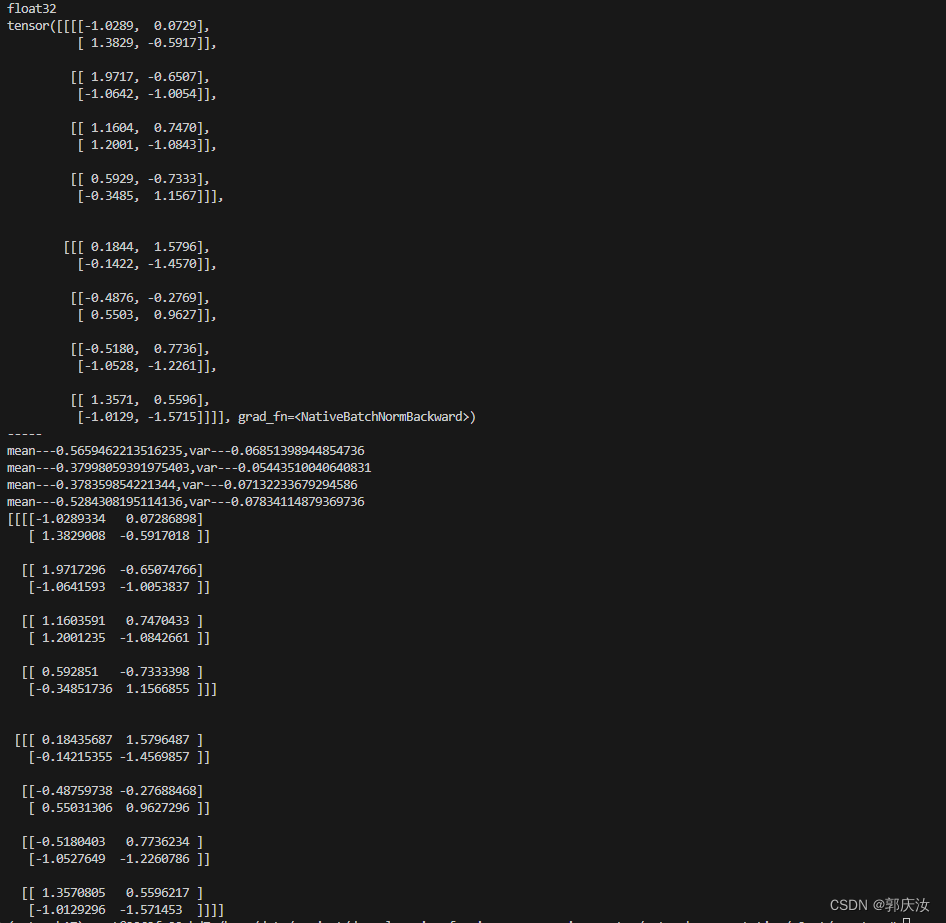
2、LayerNorm
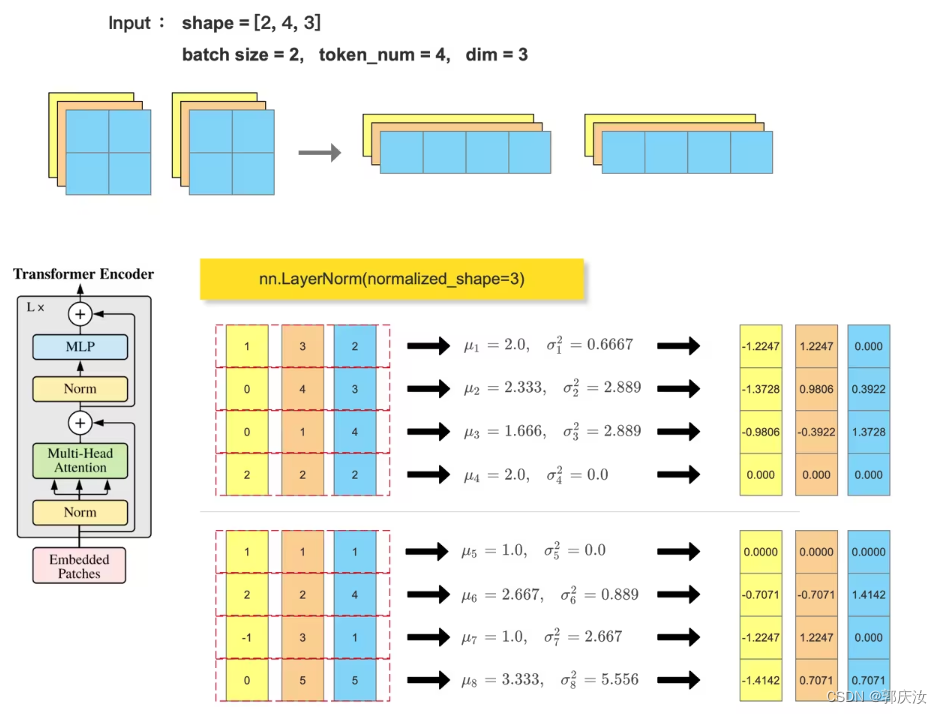
Transformer block 中会使用到 LayerNorm , 一般输入尺寸形为 :(batch_size, token_num, dim),会在最后一个维度做 归一化,其中dim维度为token的特征向量: nn.LayerNorm(dim)
import torch
import torch.nn as nn
import numpy as npfeature_array=(np.random.rand(2,3,2,2).astype(np.float32))# 需要将其转化为[batch,token_num,dim]的形式
feature_array=feature_array.reshape((2,3,-1)).transpose(0,2,1)
print(feature_array.shape) # (2, 4, 3)feature_tensor=torch.tensor(feature_array.copy(),dtype=torch.float32)layer_norm=nn.LayerNorm(normalized_shape=feature_array.shape[2])(feature_tensor)
print(layer_norm)print("\n","*"*50,"\n")
batch,token_num,dim=feature_array.shapefeature_array=feature_array.reshape((-1,dim))
for i in range(batch * token_num):mean=feature_array[i,:].mean()var=feature_array[i,:].var()print(f"mean----{mean},var----{var}")feature_array[i,:]=(feature_array[i,:]-mean) / np.sqrt(var + 1e-5)
print(feature_array.reshape(batch,token_num,dim))打印效果如下所示:
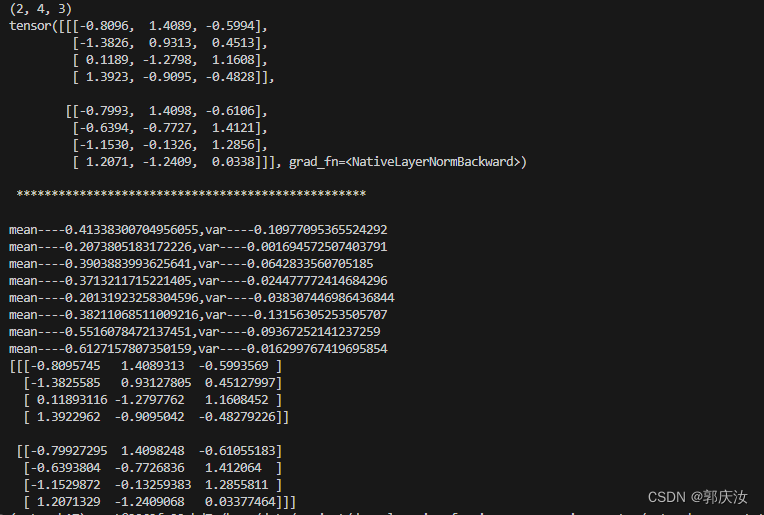
3、GroupNorm

用法:
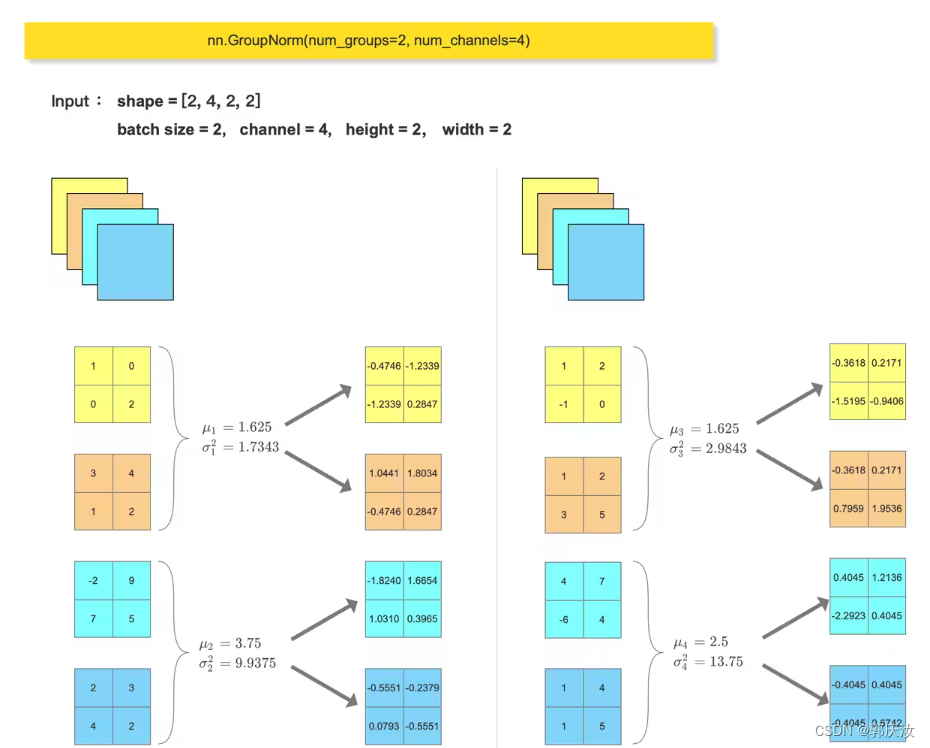
torch.nn.GroupNorm:将channel切分成许多组进行归一化
torch.nn.GroupNorm(num_groups,num_channels)
num_groups:组数
num_channels:通道数量
代码:
import torch
import torch.nn as nn
import numpy as npfeature_array=(np.random.rand(2,4,2,2)).astype(np.float32)
print(feature_array.dtype)feature_tensor=torch.tensor(feature_array.copy(),dtype=torch.float32)
group_result=nn.GroupNorm(num_groups=2,num_channels=feature_array.shape[1])(feature_tensor)
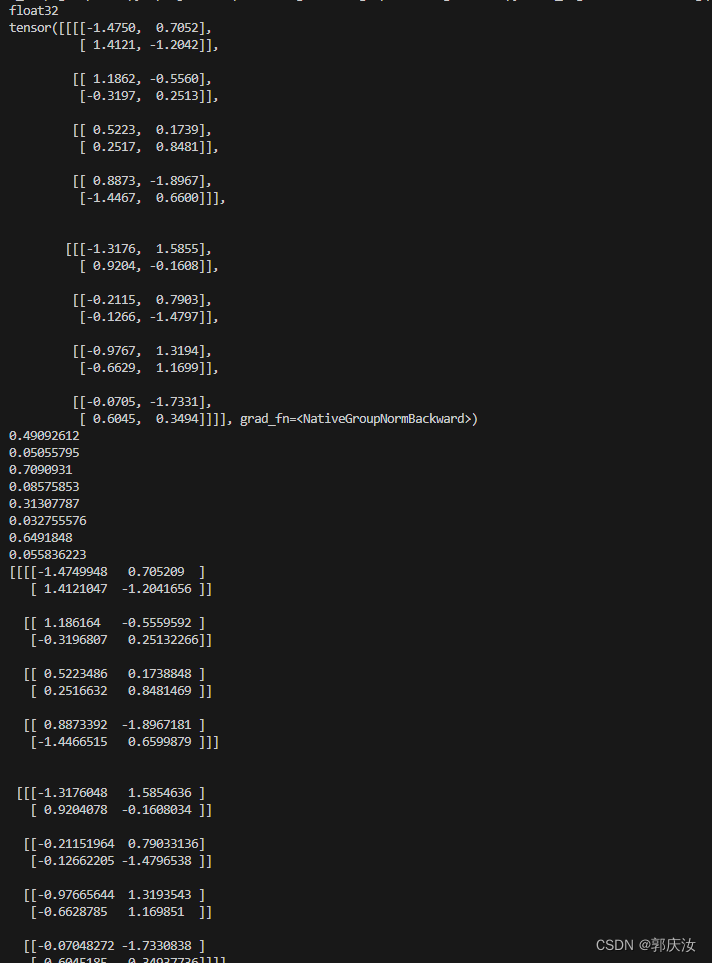
print(group_result)feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((4, 2, 2, 2))for i in range(feature_array.shape[0]):channel = feature_array[i, :, :, :]mean = feature_array[i, :, :, :].mean()var = feature_array[i, :, :, :].var()print(mean)print(var)feature_array[i, :, :, :] = (feature_array[i, :, :, :] - mean) / np.sqrt(var + 1e-5)
feature_array = feature_array.reshape((2, 2, 2, 2, 2)).reshape((2, 4, 2, 2))
print(feature_array)打印结果:

:双链表)







:使用深度残差神经网络ResNet完成图片多分类任务)


)






