1.进程
1.1基本概念
课本概念 :进程是程序的一个执行实例,是正在执行的程序。当程序被执行时,系统会为其创建一个进程,包含程序代码、数据以及运行时所需的资源。
内核观点 :进程是担当分配系统资源(CPU 时间、内存)的实体。操作系统内核通过进程来管理和调度系统资源,确保每个进程都能合理地使用 CPU、内存等硬件资源。
1.2 描述进程-PCB
1.2.1 基本概念
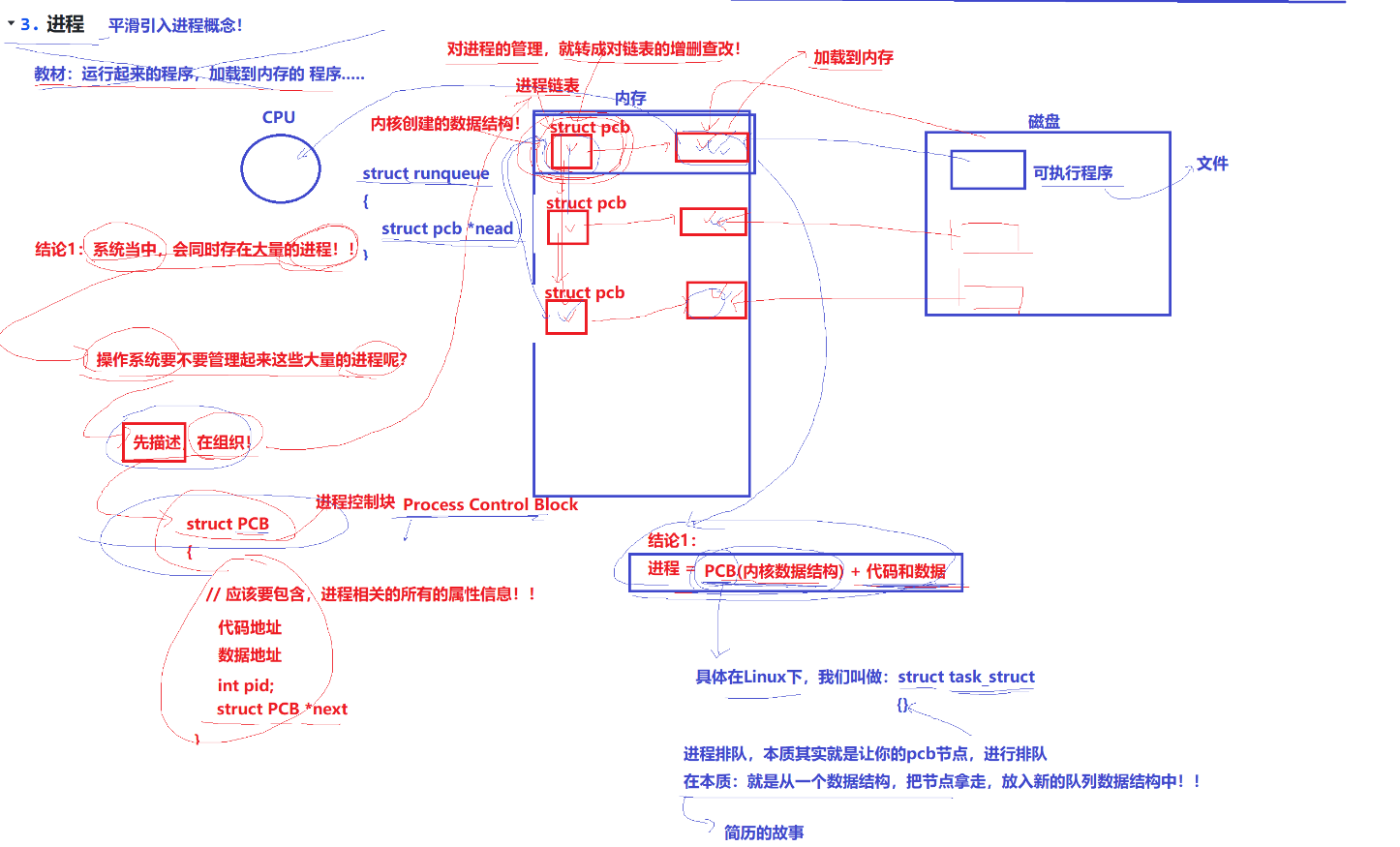
进程控制块(PCB) :进程的信息被存放在一个名为进程控制块的数据结构中,它是进程属性的集合,就好比一个档案袋,里面装着进程的各种信息,比如进程的状态、优先级、内存分配情况等。
Linux 中的 PCB(task_struct) :在 Linux 操作系统下,PCB 是通过 task_struct 这个结构体来实现的。
1.2.2 task_struct 相关内容
task_struct 的定义:task_struct 是 Linux 内核中定义的一个复杂的数据结构,包含在内核源代码的 include/linux/sched.h 文件中。它是内核用来表示和管理进程的核心数据结构,包含进程的各种信息,如进程标识符、状态、内存管理信息、I/O 信息、调度参数等。
task_struct 的作用 :用于在 Linux 中描述进程的结构体,它承载着进程相关的各类信息,是内核管理和调度进程的关键依据。
存储位置 :task_struct 是 Linux 内核的一种数据结构,会被装载到 RAM(内存)里,这样内核可以快速地访问和修改进程的信息,以实现对进程的有效管理,比如进程的创建、切换、销毁等操作都依赖于对 task_struct 的操作。
1.2.3 内容分类
1)标示符
作用 :用于唯一标识一个进程,区分系统中的不同进程。
具体信息 :通常包括进程 ID(PID)、父进程 ID(PPID)等信息。
2)状态
作用 :反映进程当前的执行状态,以及进程退出时的相关信息。
具体信息 :包括进程是处于运行态、就绪态、等待态等,还有进程的退出代码(用于表示进程正常结束或异常终止的原因)、退出信号(用于通知其他进程该进程已结束)等。
3)优先级
作用 :决定进程调度的优先顺序,优先级高的进程更容易获得 CPU 资源进行执行。
具体信息 :包括动态优先级和静态优先级,不同的进程调度算法会根据优先级来安排进程的执行顺序。
4)程序计数器
作用 :指示处理器当前正在执行的指令位置,控制程序的执行流程。
具体信息 :指向进程在程序中即将被执行的下一条指令的内存地址,当进程被调度执行时,处理器根据程序计数器的值来获取并执行相应的指令。
5)内存指针
作用 :描述进程在内存中的布局和内存资源的使用情况,以及与其他进程共享内存的区域
具体信息 :包括指向进程的程序代码段、数据段、堆、栈等内存区域的指针。还有指向与其他进程共享的内存块的指针,用于实现进程间通信(IPC)和共享资源等功能。
6)上下文数据
作用 :保存进程执行时处理器的寄存器状态,用于在进程切换时恢复进程的执行环境。
具体信息 :包括处理器的各种寄存器(如通用寄存器、控制寄存器、状态寄存器等)的值,当进程被中断或切换时,系统会保存当前的上下文数据,以便在该进程再次被调度执行时能够恢复到之前的状态继续执行。
7)I/O 状态信息
作用 :记录进程的 I/O 操作相关信息,方便系统进行 I/O 管理和调度。
具体信息 :包括进程已发出的 I/O 请求、分配给进程的 I/O 设备(如磁盘、网络设备等)以及进程打开和使用的文件列表等。
8)记账信息
作用 :用于记录进程的资源使用情况,可用于系统资源管理和计费等目的。
具体信息 :包括进程使用的处理器时间总和(如用户态和内核态的 CPU 时间)、使用的时钟数总和、时间限制(如超时时间)、记账号等。
9)其他信息
作用 :包含一些其他与进程相关的信息,这些信息可能因不同的内核版本或特定的系统配置而有所不同。
具体信息 :例如进程的创建时间、所属的用户和组、安全上下文信息(在支持安全模块的系统中)等。
1.3 进程的查看
1.3.1 PID与PPID
1) PID(Process ID)
-
定义
-
PID 是操作系统分配给每个进程的唯一标识符,用于区分系统中的不同进程,是进程存在的标志。
-
-
作用
-
唯一标识进程 :在 Linux 系统中,每个进程都有一个唯一的 PID,通过 PID 可以准确地识别和操作特定的进程。
-
进程管理 :系统和用户可以根据 PID 对进程进行管理,如发送信号、终止进程、获取进程信息等。
-
资源分配 :操作系统利用 PID 来管理进程的资源分配,如内存、CPU 时间等。
-
-
范围
-
在 Linux 系统中,PID 是一个正整数。传统的 PID 范围是 1 到 32768,但具体范围可能因系统配置而有所不同。可以通过查看
/proc/sys/kernel/pid_max文件来确定系统中 PID 的最大值。
-
2) PPID(Parent Process ID)
-
定义
-
PPID 是创建该进程的父进程的 ID。每个进程(除了 init 进程)都有一个父进程,PPID 用于标识这个父进程。
-
-
作用
-
父子进程关系 :PPID 建立了进程之间的父子关系,有助于理解进程的层次结构和来源。例如,通过查看 PPID 可以知道某个进程是由哪个父进程启动的。
-
进程管理 :在进程管理中,父进程可以利用 PPID 来管理和控制其子进程,如等待子进程结束、获取子进程状态等。
-
孤儿进程处理 :当父进程终止时,其子进程将成为孤儿进程。系统会将孤儿进程的 PPID 改为 1,由 init 进程(PID 为 1)收养这些孤儿进程,确保它们能够正常结束
-
3) 创建子进程的方式
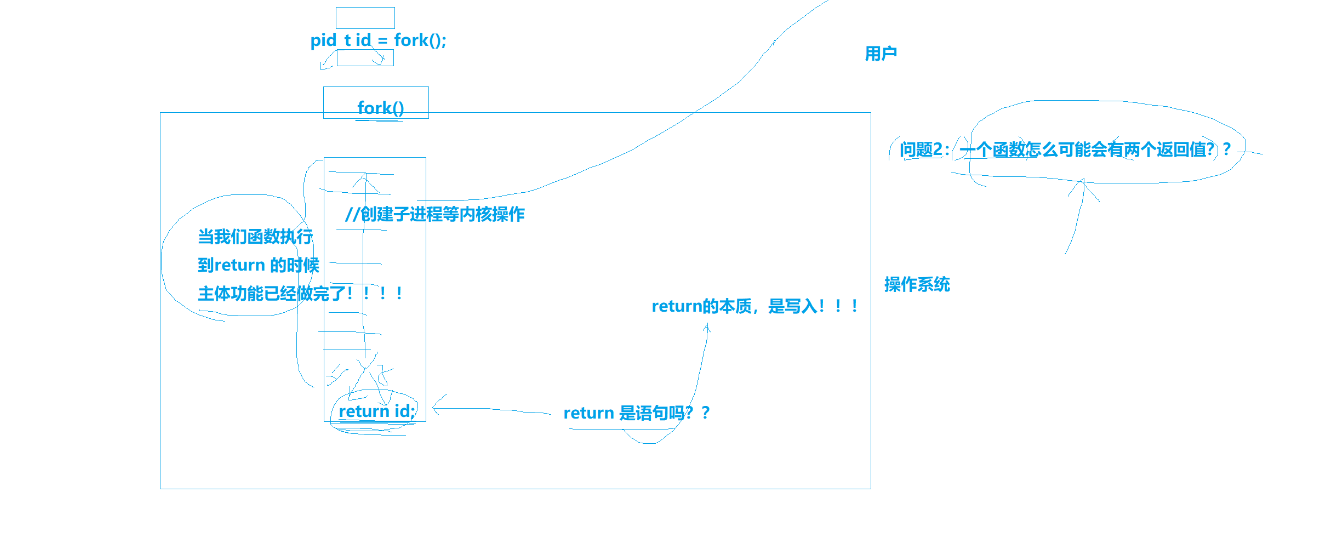
在 Linux 系统中,父进程通过 fork() 系统调用创建子进程。
fork() 的功能是创建一个与父进程几乎完全相同的子进程。子进程会复制父进程的地址空间、环境变量、打开的文件等。
1.3. 2 查看进程的可执行文件
1)使用 /proc 文件系统:
/proc 文件系统提供了关于进程的信息,每个进程在 /proc 中有一个以 PID 命名的目录。可以使用 ls -l /proc/<PID>/exe 查看进程对应的可执行文件的链接。
2)示例:
假设有一个名为 myprocess 的进程,其 PID 为 1234,可以使用以下命令查看其可执行文件:
ls -l /proc/1234/exe输出可能如下:
lrwxrwxrwx 1 root root 0 Mar 31 20:03 /proc/1234/exe -> /home/user/bin/myprocess
这表明进程 1234 的可执行文件位于 /home/user/bin/myprocess。
1.3.3 查看进程及父进程
使用 getpid 和 getppid 函数
-
功能:
-
getpid函数返回当前进程的 ID(PID)。 getppid函数返回当前进程的父进程 ID(PPID)。
函数原型:
#include <sys/types.h>
#include <unistd.h>pid_t getpid(void);
pid_t getppid(void);应用:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>int main() {pid_t pid = getpid(); // 获取当前进程的 PIDpid_t ppid = getppid(); // 获取当前进程的 PPIDprintf("Current process ID: %d\n", pid);printf("Parent process ID: %d\n", ppid);return 0;
}最后附上老师板书:

1.3.4 fork
1) 基本概念
fork 的作用是创建一个新进程,这个新进程称为子进程,而调用 fork 的进程称为父进程。子进程是父进程的副本,它继承了父进程的几乎所有资源和状态。
2)工作原理
复制父进程资源
当 fork 被调用时,操作系统会创建一个新进程,并将父进程的代码段、数据段、堆、栈等资源复制到子进程中。子进程在创建时几乎与父进程完全相同,包括代码、变量、文件描述符、环境变量等。但是,子进程有自己独立的进程标识符(PID),并且它与父进程是两个独立的进程实体
写时拷贝
现代操作系统通常采用“写时复制”技术来优化 fork 的性能。在 fork 调用时,操作系统并不会立即复制父进程的所有资源,而是将父进程的资源标记为“共享”。只有当父进程或子进程对这些资源进行写操作时,操作系统才会真正复制被修改的部分资源,从而避免了不必要的复制操作,节省了时间和内存。
3) 返回值
fork 的返回值用于区分父进程和子进程
在父进程中
fork 返回子进程的进程标识符(PID),这是一个正整数。父进程可以通过这个 PID 来监控子进程的状态,例如使用 wait 或 waitpid 等系统调用等待子进程结束。
在子进程中
fork 返回 0。子进程可以通过返回值为 0 来判断自己是子进程,并执行相应的逻辑。
出错时
如果 fork 调用失败(例如系统资源不足或超出进程限制),它会返回 -1,并设置错误码 errno。
4)代码示例
#include <stdio.h>
#include <unistd.h>
#include <sys/wait.h>int main()
{pid_t pid = fork(); // 调用 fork 创建子进程if (pid < 0) {// fork 失败perror("fork failed");return 1;}else if (pid == 0) {// 子进程printf("I am the child process, my PID is %d\n", getpid());} else {// 父进程printf("I am the parent process, my PID is %d, my child's PID is %d\n", getpid(), pid); wait(NULL); // 等待子进程结束}return 0;
}假设父进程的 PID 是 1234,子进程的 PID 是 1235,程序的输出可能是:

也许此时会有人疑惑,为什么if和else都进去了??难道是程序出错了吗?还是说我们碰到了编程领域的量子力学了??实际上,这里是多线程编程,可以同时都进的。
5)代码详解
fork 调用后,程序会分为两部分继续执行:一部分在父进程中运行,另一部分在子进程中运行。因此,if 和 else 语句分别对应父进程和子进程的逻辑。
当程序执行到 pid_t pid = fork(); 时,操作系统会创建一个子进程。在调用 fork 之前,父进程和子进程是同一个进程,共享相同的代码和数据。调用 fork 之后,程序会分为两部分继续执行:父进程和子进程。
在父进程中,fork 返回子进程的进程标识符(PID),这是一个正整数。因此,pid > 0,程序会进入 else 分支。
在子进程中,fork 返回 0。因此,pid == 0,程序会进入 else if 分支。
实际上,if 和 else 并不是同时进入的,而是分别在父进程和子进程中执行不同的分支。
父进程 执行 else 分支。子进程 执行 else if 分支。
从程序的整体运行角度来看,if 和 else 的逻辑分别在两个不同的进程中执行,因此看起来像是“都进去了”,但实际上它们是在不同的上下文中运行的。
有一点值得注意的是:当我们创建出子进程后,父子两个进程,谁先运行不确定,具体由OS的调度原则来确定。

忌(阶)秘(技)术(巧)【第七式】程序的编译)










工程优化)

)




)