简介: 本文主要介绍如何进行MaxCompute存储资源和计算资源的评估及规划管理。
一、MaxCompute资源规划背景介绍
MaxCompute资源主要有两类:存储资源、计算资源(包含cpu和内存)。存储资源用于存储MaxCompute的库表数据,计算资源用于运行sql、mr等任务。最佳的MaxCompute资源规划方案能够达到以下几个目的:
• 数据存储资源足够,既能够存储当前的所有存量库表数据,也能够存储未来一段时间的增量数据;
• 计算资源充足,但是不能浪费。计算资源量能够满足所有数据计算任务,且尽可能减少资源浪费情况。这样耗费的资源费用最少;
• 被处理的数据量巨大、耗费计算资源较多的大型任务,可能会将quota group资源组耗尽,造成其他任务无法获取到计算资源而阻塞。MaxCompute资源规划方案必须能够尽量避免这种情况;
• 不同优先级的计算任务能够尽量互不干扰,有限保证高优先级的任务获取到足够计算资源;
• 能够满足时段的差异化资源需求,满足对资源隔离(生产/开发/自助分析)不同工作负载的能力,避免相互干扰,同时更大化提高资源使用率。
MaxCompute资源规划的最终目标就是能够满足上述几点需求,企业客户消耗最低资源费用的情况下,满足数据存储需求,以及数据处理任务对计算资源的需求。
本文内容主要基于阿里公有云MaxCompute环境。公有云和专有云环境的MaxCompute资源规划有比较大的差异,比如:在公有云环境,存储资源和计算资源是使用整个阿里云区域的资源池,几乎不用担心底层到底有多少台服务器进行支撑,可以近乎认为公有云底层的资源池是无限的;但是在专有云环境,整个专有云都是企业客户独享的资源,必须根据存储资源和计算资源量规划服务器数量&&服务器规格。本文主要探讨公有云MaxCompute的资源规划。
二、MaxCompute存储资源规划
2.1 计存比
在介绍存储方案选择之前,先说一个常用的概念:“计存比”。计存比就是计算CU数量和实际存储数量TB的比值。比如资源分配:50CU计算资源,存储数据量是10TB。那么,50CU/10TB=5,计存比=5。
2.2 存储资源规划建议
对于存储资源,MaxCompute提供两种计费方式:
• 按量付费:MaxCompute以小时级别采集每个项目空间下当前的存储,并以 project 项目空间为基本单位,计算项目空间当天的存储平均值。然后再乘以单价(元/GB/天),最后的得到每天的存储费用。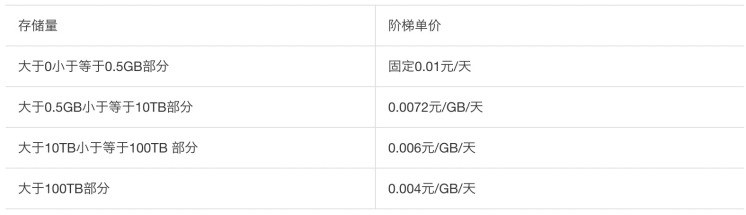
• 套餐资源:MaxCompute包年包月套餐包含预留的计算资源和存储资源,每种套餐固定计算资源CU量和存储资源。套餐中的存储资源是指每天固定的存储资源,超过的部分另外按量计费。套餐资源目前只支持固定的几个套餐,见下图所示:

阿里云提供的第二种方案,三种套餐的计存比是固定的,而且计存比都在1左右。这种固定资源套餐的计存比偏低,适合存储量大、计算任务较少的企业客户。固定资源套餐的计算资源CU量是固定的,无法应对计算资源需求量猛增的情况。比如企业平时的数据批量处理任务可以正常运行,在双11、618等大促活动期间的数据批量处理任务就会出现严重阻塞。
对于存储资源规划,笔者建议:
• 当预估企业客户未来一段时间的数据存储总量比较大(100TB以上)、计算任务少(计存比小于1.5),选择阿里云的固定套餐资源;
• 当客户需要更加灵活的存储资源空间,同时计算资源CU量不受存储空间限制,建议选择按量付费方式。使用多少存储空间,消耗多少存储费用。至于计算资源CU规划,按照企业客户的实际需求,单独进行规划。
三、MaxCompute计算资源规划
3.1 MaxCompute计算资源简介
对于计算资源规划,笔者首先建议:在项目测试阶段,全部都采用按量付费方式。因为开发测试阶段,消耗的计算资源CU数量不多,采用按量付费方式更加便宜。关于MaxCompute计算资源按量付费的计费规则,读者可以详细参考官网文档:https://help.aliyun.com/document_detail/112752.html
项目开发完成,正式进入到上线阶段,建议购买包年包月的计算资源CU配额,因为是固定的CU配额,不会在阿里云公共计算资源池去抢占计算资源,可以顺利地为企业客户预留足够的CU资源。计费方式如下所示: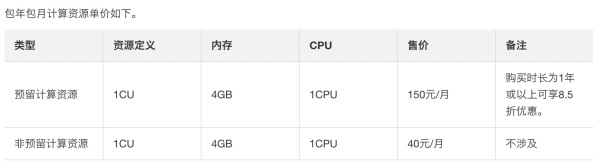
本章节主要介绍项目上线之后,如何购买合适的包年包月固定CU数量。对于计算资源规划,本文介绍在项目实践中常用的两种方案:
方法1:
按照以往经验先确定计存比,然后预估数据容量,最后得到计算计算资源CU量;
方法2:
选择在项目正式上线前、或者在项目正式上线运行一小段时间之后,评估计算资源CU消耗的CPU总时长,然后再根据不同任务单独消耗的CPU时长、任务的优先级、企业客户要求每天所有任务必须在哪个时间段运行完成,综合考虑这几个因素,最后得到计算资源CU量的最小最大值,用数学表达式表示就是:
本文分两个章节分别介绍这两种常用的计算资源预估方法。
3.2按照计存比方法预估计算资源
第一步:评估存储容量
按照3年项目周期计算:存储容量 = 当前数据存量 + 每月预估数据增量*月数。当前数据存量很容易得到,在数据上云完成之后就可以得到当前数据存量。每月预估数据增量需要在数据上云之后两三个月,根据增量总值除以月数,得到每月预估增量平均值。当然,如果还要考虑未来数据中台承载更多业务、每月数据增量会变大等因素,可以将当前计算得到的每月预估数据增量值乘以倍数。
建议每半年预估一次存储总容量,然后每半年调整一次计算资源CU量。
第二步:预估计存比
按照项目开发测试阶段、以及上线运行一两个月的情况,可以大概预估计存比。根据实际情况,计存比一般配置2-10。如果客户每天运行的数据批量处理任务很多,且sql程序计算复杂度高,计存比可以选择10;如果客户每天运行的数据批量处理任务比较少,且sql程序计算复杂度不高,计算比可以选择2;如果客户每天运行的数据批量处理任务适中,sql程序计算复杂度也适中,计存比可以选择2-10之间的合适值。
建议每半年评估一次计存比,然后每半年调整一次计算资源CU量。
第三步:预估计算资源CU量
按照第一步预估的每半年存储资源总量,结合每半年评估的计存比值,存储资源总量 *计存比 = 计算资源CU总量。 预估得到计算资源CU总量,进而每半年利用该企业主账号调整一次MaxCompute计算资源CU总量。
按照计存比预估企业项目需要消耗的计算资源CU总量,有很多需要预估的变量,包括数据存储总量、计存比,很可能预估不准确。因此,该方法要求项目的技术负责人拥有较多的项目实施经验,能够在每一步预估都尽可能准确。
3.3按照项目实际消耗CU量进行资源划分
选择在项目正式上线前、或者在项目正式上线运行一小段时间之后,评估计算资源CU消耗的CPU总时长,然后再根据不同任务单独消耗的CPU时长、任务的优先级、企业客户要求每天所有任务必须在哪个时间段运行完成,综合考虑这几个因素,最后得到计算资源消耗费用最少的最佳CU数量。
3.3.1查看计算资源消耗情况
在进行资源规划之前,需要首先搞清楚过去一段时间MaxCompute计算资源的消耗情况。读者可以参考https://help.aliyun.com/document_detail/135432.html
详细介绍如何开通和查看MaxCompute的information_schema信息。MaxCompute元数据表有很多,本文只需要利用到一张表:TASKS_HISTORY。这张元数据表记录了所有MaxCompute 计算任务的资源消耗情况。读者可以参考
https://help.aliyun.com/document_detail/135433.html#title-r2c-tak-zfi
详细介绍元数据表TASKS_HISTORY的字段信息,其中最重要的字段信息是:cost_cpu 和 cost_mem,分别表示:
本文主要借助CPU消耗量(也就是上图的cost_cpu字段对应的每个任务消耗的cpu数量)进行计算资源CU数量的规划。需要注意的是,cost_cpu字段的含义:MaxCompute计算任务作业的CPU消耗量。100表示1 core*s,比如官网的例子:10 core运行5s,cost_cpu为10*100*5=5000)。那么cost_cpu字段表示的是“cpu核数消耗量 *100 *任务运行时间秒”。因为cost_cpu按照秒统计,对于实际项目评估太过于精细,我们通常将cost_cpu 除以 100、然后再除以3600,得到cores *h (cpu核数 *小时)。这样方便评估实际项目在规定时间段内运行完所有任务需要quota group资源组的最少计算资源CU数量。
如下如所示某个MaxCompute project 的MaxCompute计算任务的资源消耗情况:
3.3.2 规划计算资源CU数量
通过3.3.1章节的内容,我们可以查看到MaxCompute project某一天运行的所有计算任务消耗的CPU核数*小时。
计算资源CU数量规划的细则:
Step1:
首先,计算得到平均每天运行所有任务消耗的cost_cpu总和(需要除以100,才能得到真正的cpu核数 *秒,然后再除以 3600,得到消耗的 “cpu核数 *小时”)。举个例子:MaxCompute project平均每天需要运行1000个任务,这些任务消耗的cost_cpu分别是 W1、W2 …… W1000。那么需要将W1 + W2+ …… + W1000 得到每天运行所有任务消耗的cost_cpu总和Wz。
注意:数据中台一般会划分6个MaxCompute project,分别是:
• ods_dev:贴源层开发测试project;
• ods_prod:贴源层生产project;
• cdm_dev:公共层开发测试project;
• cdm_prod:公共层生产project;
• ads_dev:应用层开发测试project;
• ads_prod:应用层生产project;
需要将这6个MaxCompute project的所有数据计算任务的cost_cpu相加得到cost_cpu总和Wz。
当然,大部分读者使用MaxCompute进行数据处理,并非需要建设数据中台。任何需要使用MaxCompute进行数据处理的应用场景,都可以按照实际划分的MaxCompute project,将这些MaxCompute project涵盖的所有数据处理任务消耗的cost_cpu相加得到总和Wz。
Step2:
按照上述介绍的阿里云官网详情介绍,cost_cpu需要除以100才是真正消耗的CPU核数。同时,cost_cpu按照秒进行度量,我们一般会按照小时进行度量。因此,需要将cost_cpu总和Wz除以100、再除以3600,最后得到平均每天运行所有任务消耗 “cpu核数 *小时”,本文假设这个值为W。
Step3:
咨询客户数据批量处理任务需要在每天的哪些时间段运行完成。举个例子:客户要求在深夜零点之后、凌晨6点之前必须将所有数据批量处理任务运行完成。那么每天能够运行的总时长都是6个小时。本文假设所有任务必须在N个小时运行完成。
Step4:
利用上述得到的每天所有任务[cpu核数 *小时 / 任务运行时长N个小时],就可以得到该客户的MaxCompute project需要分配的计算资源CU数量的最小值:W/N。
W/N的前提是数据处理任务的cost_cpu很稳定,而且在这N个小时内,所有任务都随时在运行,不存在任何空闲的时间。但是,实际项目可能会因为某些原因导致数据计算任务运行时间延长(比如参与计算的数据量增加),相当于W会变大;同时,由于DataWorks/Dataphin调度任务还会产生很多延迟时间、任务获取CU资源也会耽误很多时间,这部分延迟时间会加大任务之间运行的时间间隔,真正用于运行任务的时间会小于N。
W/N的分母实际变大、分子实际变小,进而变相地要求增加计算资源,以便让任务获取更多资源进而运行地更加快速。因此一般情况下,会在上述得到的W/N结果基础上增加一倍。
按照上述4个步骤,可以预估计算得到企业可以需要购买的CU数量。
3.3.3举例规划计算资源CU数量
某企业实施数据中台项目,划分8个MaxCompute project。除了3.3.2章节介绍的6个MaxCompute project之外,还单独规划了两个专门做数据清洗的MaxCompute project。当然,正如前文所述,读者需要按照实际规划的若干个MaxCompute project进行计算。
Step1 和 Step2:
按照3.3.1章节介绍的方法统计过去15天,平均每天8个MaxCompute project消耗的“cpu核数 *小时”的总量为:202 CPU核数 *小时。
Step3:
因为客户的业务系统空闲时间在晚上1点到早上6点,而且每天早上7点之前需要出每天数据批量任务的运行结果。在6点到7点之间,主要产出报表,因此只有5个小时可以运行批量任务。
Step4:
得到MaxCompute计算资源CU数量:202 CPU核数 *小时 / 5小时 = 40.2 cores核数,也就是至少需要41 CU。因此建议客户购买计算资源CU量为 41*2 = 82 CU数量。
根据预估计算结果,我们为客户推荐购买的包年包月固定CU量为82个。先开通MaxCompute 计算资源quota group 资源组的包年包月固定CU资源:
然后配置总CU量为82个。
四、浅谈MaxCompute group quota 资源划分方法
笔者在第3章节详细介绍如何根据最近一段时间的CU消耗情况,预估得到MaxCompute 计算资源CU数量。购买的MaxCompute quota group资源属于“默认预付费Quota”,类似于开源hadoop yarn的root资源队列。在实际项目开发过程中,还需要将“默认预付费Quota”再细分为若干个“子quota group资源组”。当然,一般情况下建议1个MaxCompute project 划分1个子quota group资源组。如何将“默认预付费Quota”划分为若干个子quota group资源组?这是本章节需要详细介绍的内容。
4.1 fuxi伏羲资源调度系统原理简介
为了便于读者理fuxi调度系统关于资源组的资源分配和资源抢占机制,本文以开源hadoop yarn资源队列进行类比。MaxCompute的“默认预付费Quota”类似于yarn的root资源队列,这部分计算资源属于“总计算资源组”,需要将总资源组进行细分。
假设我们购买的“默认预付费Quota”包含Dt个CU资源,然后“默认预付费Quota”被划分了n个子资源组D1、D2 …… Dn 。这n个资源组必须设置两个重要参数:资源组的“预留CU最小配额”minD1、minD2……minDn,以及“预留CU最大配额” maxD1、maxD2……maxDn。这n个资源组必须满足以下条件:
•** minD1 + minD2 + …… + minDn = Dt
• 对于任意的子资源组的maxDi,maxDi <= Dt**
我们划分子资源组必须满足上述两个条件。其中,每个MaxCompute project的min资源量表示该子资源组最低预留的CU数量,无论是否有任务提交,这个子资源组就会占用这么多CU量;每个MaxCompute project的max资源量表示该子资源组能够获取到的最大CU数量,哪怕其他资源组全部都没有任务运行,这个子资源组最多也只能占用max的CU量。
如下图所示,170个CU资源量的“默认预付费Quota”划分了两个子资源组: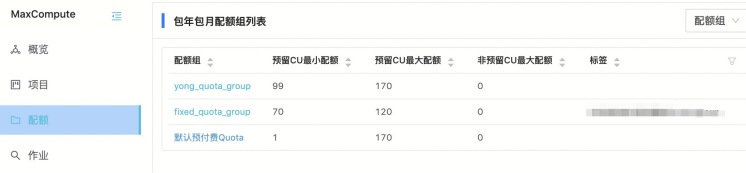
从上图我们看到,划分的两个子资源组yong_quota_group 和 fixed_quota_group设置的最小CU配额、最大CU配额,满足上述两个条件。
4.2 MaxCompute计算资源抢占机制
按照4.1介绍的内容,若干个子资源组的max最大CU配额都可以设置为“默认预付费Quota”,那么一旦所有资源组对应的MaxCompute project都疯狂地运行任务,那么必然存在资源抢占的问题。按照默认规则,MaxCompute资源组的资源抢占按照“fair scheduling”公平调度机制,先提交的任务优先获取CU资源。那么,如果某个MaxCompute project提交超大型任务,必然将会把CU资源消耗殆尽。此时,其他资源组对应的MaxCompute project提交的任务将会因为无法获取到CU资源而被阻塞。
如何更加完美地划分quota group资源组,并且为每个资源组分配最合理的 min资源配额、max资源配额? 如何结合实际项目需求,合理安排任务运行的先后顺序、以及任务运行调度的依赖关系?这是划分子quota group资源组需要考虑的重点因素。
4.3 quota group资源组划分
在第3章节详细介绍如何预估计算企业客户需要购买的包年包月预留CU量,也就是 “默认预付费Quota”,比如3.3.3章节的实际案例里面介绍的170个CU。下一步就是创建子quota group资源组,并为每个quota group分配 min、max资源量。笔者结合多年hadoop yarn资源分配经验,以及使用MaxCompute的一些经验,总结了一些实际的经验。
第1条方法:
每个MaxCompute project 对应1个独立的quota group子资源组;
第2条方法:
每个quota group子资源组的min 资源量不小于 “默认预付费Quota”的5%,建议也不大于“默认预付费Quota”的20%。具体原因:如果将子资源组的min资源量设置太大,比如超过20%,那么各个资源组的min资源量之和就会接近或者超过“默认预付费Quota”,那么划分子资源组将会失去意义,最终造成资源大量浪费。
第3条方法:
每个quota group子资源组的max 资源量不小于“默认预付费Quota”的40%,当然最大可以设置到“默认预付费Quota”。如果子资源组的max 资源量设太小,在集群运行任务空闲的时候,资源会造成极大浪费。
除了上述三条基本方法之外,还有几个比较实用的方法:
第4条方法:
对于企业客户划分的多个MaxCompute project,需要统计每个project 的cost_cpu消耗量“cpu核数 *小时”,并按照消耗量进行排序。消耗量最大的MaxCompute project对应的子资源组的max资源量可以设置为“默认预付费Quota”的80%以上,其他project对应的子资源组按照排序,设置的max资源量以此减少,直到最后的子资源组的max资源量不小于“默认预付费Quota”的40%。
第5条方法:考虑任务调度与依赖关系
对于很多企业客户,使用DataWorks/Dataphin需要做任务调度。任务调度就必然有父子任务关系。比如笔者在本文列举的实际案例,对于数据中台项目,划分了8个MaxCompute project,分别是:数据清洗的两个project、ods贴源层的两个project、cdm公共层的两个project、ads应用层的两个project。每个project分配一个独立的quota group子资源组。数据分层有严格的先后顺序:数据清洗的任务是ods层任务的父任务;ods层任务是cdm层任务的父任务;cdm层任务是ads层任务的父任务,他们之间的任务调度关系如下所示:
对于这类常见的不同MaxCompute project的任务之间有严格的调度依赖关系,不能简单的按照上述的方法设置资源组的min资源量和max资源量。因为上一个层次有几百个任务需要运行、下一个层次也有几百个任务需要运行,而且这些任务之间是混合运行的。比如:某个工作流的几十个ods层任务运行完成,那么接下来将会运行对应的几十个cdm层任务;与此同时,数据清洗层和ods层还会运行新的任务;cdm层和ads层也会运行所有上游都运行完成的任务。这些任务之间混合在一起运行,为资源组划分资源量添加了很多变数。此时需要根据实际项目经验,为这些资源组分配min资源量和max资源量。
比如笔者这边的项目情况如下:数据清洗层因为涉及很多业务系统原始数据表的join操作,非常消耗CU资源;ods层经常是导入清洗之后的数据即可,不需要消耗太多资源;cdm层规范建模,任务运行方法比较固定,因为我们在数据清洗层已经将数据做规范化处理,因此cdm层消耗的CU资源也很少;最后,将cdm的派生指标融合进ads层,需要做很多复杂的join操作,因此消耗的CU资源非常多。并且,从晚上1点到凌晨7点之间,这四个层次对应的项目运行消耗的资源量呈现“错峰”情况。下图是我们在进行测试环节统计的情况:
可以明显看出来,四个层次运行任务的数量呈现“错峰”情况,每个层次出现的任务高峰会以此延后一段时间,该层次MaxCompute project消耗的资源量也是呈现错峰。鉴于上述场景分析,我们考虑在第4条方法的基础上,将不同层次“错峰”高峰运行的因素也考虑在内。尽可能让消耗资源多的项目分配的max资源量更大,但是因为“错峰”运行因素,消耗资源少的项目分配的max资源量也不能太小,尽可能分配大一些,让资源得到合理应用。笔者为该项目设计4个quota 资源组:
• 数据清洗层project对应的quota 资源组:min资源量为“默认预付费Quota”的10%,max资源量为“默认预付费Quota”的70%;
• ods贴源层project对应的quota 资源组:min资源量为“默认预付费Quota”的10%,max资源量为“默认预付费Quota”的50%;
• cdm公共层project对应的quota 资源组:min资源量为“默认预付费Quota”的10%,max资源量为“默认预付费Quota”的50%;
• ads应用层project对应的quota 资源组:min资源量为“默认预付费Quota”的10%,max资源量为“默认预付费Quota”的80%。
五、总结
当然,实际如何为MaxCompute project划分资源组?每个资源组的min/max资源量占据“默认预付费Quota”的百分比多少?需要综合考虑不同MaxCompute project内部的数据处理任务的优先级、任务之间依赖关系、任务错峰运行情况,还需要特别考虑某些超大型数据计算任务是否有必要与其他普通任务进行资源组隔离。
原文链接
本文为阿里云原创内容,未经允许不得转载。