简介: 本文重点介绍Hologres如何落地阿里巴巴飞猪实时数仓场景,并助力飞猪双11实时数据大屏3秒起跳,全程0故障。
摘要:刚刚结束的2020天猫双11中,MaxCompute交互式分析(下称Hologres)+实时计算Flink搭建的云原生实时数仓首次在核心数据场景落地,为大数据平台创下一项新纪录。借此之际,我们将陆续推出云原生实时数仓双11实战系列内容,本文重点介绍Hologres如何落地阿里巴巴飞猪实时数仓场景,并助力飞猪双11实时数据大屏3秒起跳,全程0故障。
今年双十一较以往最大的变化就是活动的整体节奏从原来“单节”调整为今年的“双节”,自然地形成两波流量高峰,大屏和营销数据的统计周期变长,指标维度变得更多,同时集团GMV媒体大屏首次直接复用飞猪大屏链路数据,所以如何保障集团GMV媒体大屏、飞猪数据大屏以及双十一整体数据的实时、准确、稳定是一个比较大的挑战。
本次双十一飞猪实时大屏零点3秒起跳,全程0故障,顺利护航阿里巴巴集团媒体大屏,做到了指标精确、服务稳定、反馈实时。
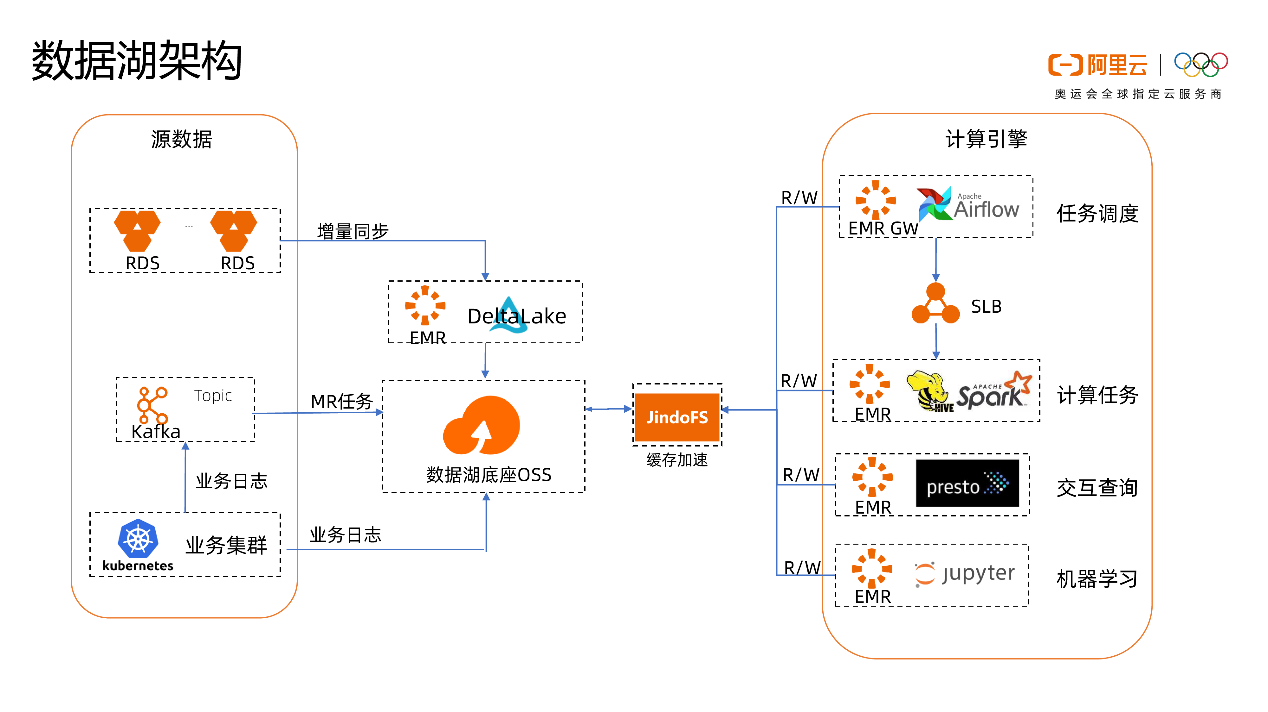
而这一切都离不开大屏背后实时数据全链路的技术升级和保障。飞猪实时数据整体架构如下图所示: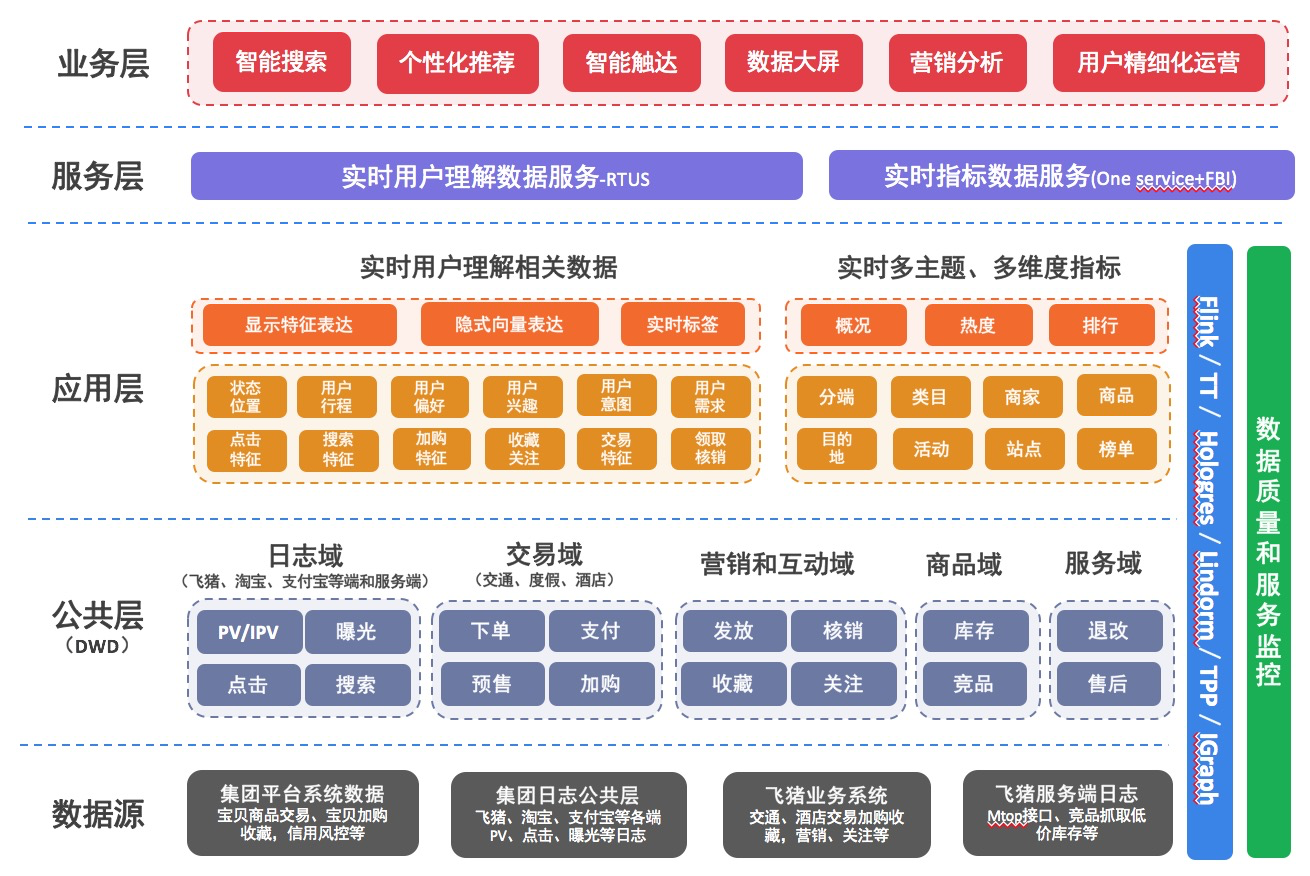
下面将会介绍,为了实现快、准、稳的双11实时数据大屏,业务针对实时数据全链路做了哪些升级改进和优化。
一、公共层加固,抵御洪峰流量
抵御双十一流量洪峰,首先发力的是实时数据公共层。经过近两年的迭代完善,多端、多源的实时数据公共层已经实现了日志、交易、营销互动、服务域的全域覆盖,作业吞吐和资源效率也在不断的提升,本次双十一为了平稳通过流量双峰,对其进行了多轮的全链路的压测和进一步的夯实加固:
1)维表迁移,分散热点依赖
维表是实时公共层的核心逻辑和物理依赖,热点维表在大促时可能就是服务的风险点和瓶颈。飞猪商品表是各类实时作业依赖最多的Hbase维表,其中包括大促时流量暴涨的飞猪淘宝端流量公共层作业。去年通过对淘系PV流量提取的深度逻辑优化,将该维表的日常QPS由几十w降低到了几w,但随着后续点击公共层以及其他业务作业的不断新增依赖,日常QPS很快升到了5w+,大促压测时一路飙升到十多w,且维表所在的Hbase集群比较老旧且为公共集群,大促稳定性风险较大。所以将飞猪商品表及其他大流量公共层依赖维表都迁移到性能更佳的lindorm集群,将其他非核心的应用层维表继续保留原有habse集群,分散大促洪峰时对维表的压力。
2)作业隔离,防止资源挤压
实时作业的资源消耗也符合二八原理,小部分的作业消耗了大部分的计算资源。飞猪淘系的曝光作业双十一大促时至少需要1000+CU保障资源,PV公共层任务需要600CU,整个流量公共层9个作业至少需要集群一半以上的资源来进行保障。为防止洪峰袭来是单队列内的多个大作业资源超用(大流量时作业消耗会超出配置资源)时发生挤压,影响吞吐,将大作业分散不同资源队列。同样对于各个类目的交易公共层任务也会分散在各个资源队列,防止单一集群突发极端异常,导致指标数据跌0。
3)双十一性能表现
双十一期间,实时公共层顺利抵御淘系源头较日常交易流量250倍和日志流量3倍,整体流量公共层最高约几千万条/秒的洪峰冲击,淘系交易公共层任务无任何时延,流量公共层分钟级时延并很快消退。
二、架构升级,提效开发
双十一大促的核心三个阶段预售、预热、正式,正式阶段最重要的事情就是付尾款。本次双十一业务侧比较大的变化就是付尾款由原来的一天变成了三天,导致去年的关于尾款的营销数据都无法复用。除了要保留之前大盘、类目、天、小时等多维度尾款支付相关的指标,还需要新增商品、商家粒度的尾款,同时因为尾款周期变长,为了业务更高效的催尾款,临时可能需要新增更多维度的数据(尾款的最后一天就接到了需要拉取未支付尾款订单明细的需求)。所以为了应对本次双十一尾款数据指标长周期、多维度、易变化的挑战,将大屏和营销数据的数据架构由预计算模式升级为预计算+批流一体的即席查询混合模式,整体的开发效率至少提升1倍以上,且可以方便的适应需求变更。
1)新的营销数据架构:

- 即席查询部分:Hologres+Flink流批一体的数据架构,使用了Hologres的分区表和即时查询能力。将公共层的实时明细数据写入当日分区,离线侧公共层明细数据由MaxCompute直接导入覆盖Hologres次日覆盖分区(对于准确性和稳定性非严苛的场景,可以选择都去掉离线merge的步骤),同时写入时注意配置主键覆盖,防止实时任务异常时,可以回刷。各位维度的指标计算,直接在Hologres中通过sql聚合,即时返回查询结果,非常方便的适应统计指标的需求变更。
- 预计算部分:保留了之前比较成熟的Flink+Hbase+Onservice的计算、存储和服务架构。主要通过Flink实时聚合指标,并写入Hbase,onservice做查询服务和链路切换。高可用和稳定性场景,构建主备链路,可能还会配合离线指标数据回流,修复实时链路可能出现的异常和误差。
2)简单高效的指标计算
由Hologress搭建的即席查询服务,除了架构简单高效,指标计算更是简单到令人发指,极大的解放了实时指标数据的开发效率。
对于尾款支付部分,有一个很常规,但如果通过Flink SQL来实现就会比较鸡肋或者代价较大的指标,就是从零点到各小时累计尾款支付金额或支付率。flink的group by本质是分组聚合,可以很方便对小时数据分组聚合,但是很难对从0-2点,0-3点,0-4点这类累计数据构建分组来进行计算,只能构建0点到当前小时max(hour)的数据分组做聚合。带来的问题就是,一旦数据出错需要回刷,只会更新最后一个小时的数据,中间的小时累计情况都无法更新。
而对于通过Hologres的即时查询的引擎来说,只需要对小时聚合之后再来一个窗口函数,一个统计sql搞定,极大的提升了开发效率。示例如下:
select stat_date,stat_hour,cnt,gmv --小时数据
,sum(cnt) over(partition by stat_date order by stat_hour asc) as acc_cnt --小时累计数据
,sum(gmv) over(partition by stat_date order by stat_hour asc) as acc_gmv
from(select stat_date,stat_hour,count(*) cnt,sum(gmv) as gmvfrom dwd_trip_xxxx_pay_riwhere stat_date in('20201101','20201102')group by stat_date,stat_hour
) a ;三、链路和任务优化,保障稳定
1)主备双链3备份
阿里巴巴集团GMV媒体大屏一直由集团DT团队自主把控,今年双十一的集团大屏,为了保证口径的一致和完整性,首次直接复用飞猪实时链路数据,所以对大屏指标计算和链路的稳定性和时效提出了更高的要求。
为了保证系统高可用,各个类目的交易从源头数据库的DRC同步到交易明细公共层分别构建张北、南通集群主备双链路,对于应用层的GMV统计任务和Hbase结果存储在双链的基础上又增加上海集群的备份。整体的链路架构如下: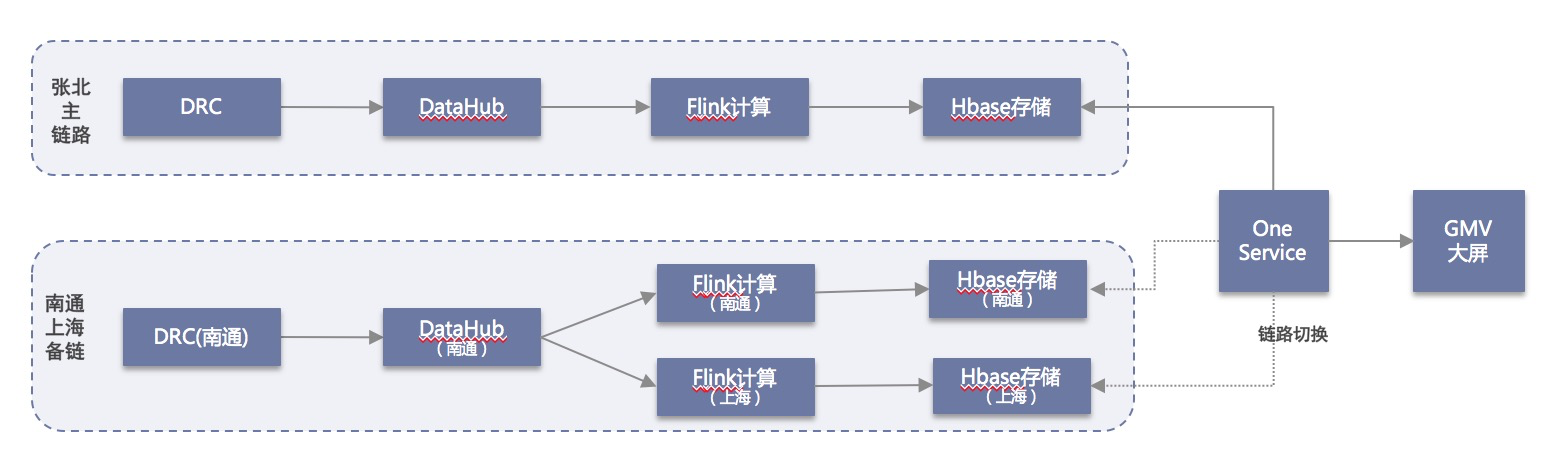
同时,配合全链路的实时任务异常监控和报警,出现异常时可以做到链路秒级切换,系统SLA达到99.99%以上。
2)零点3s起跳优化
为了保证零点3s起跳,对任务的全链路数据处理细节优化。
- 源头部分优化了DRC同步后binlog的TT写入,将源TT的多queue缩减为单queue,减少数据间隔时延。早期的开发没有正确评估各类目交易数据流量情况,而将TT的queue数设置过大,导致单queue内流量很小,TT采集时默认的cache size和频次,导致数据数据的间隔时延很大,从而放大了整体链路的时延。TT多queue缩容后,数据间隔时延基本下降至秒级以内。
- 中间部分优化各类目的交易公共层的处理逻辑,消减逻辑处理时延。初版的TTP交易(国际机票、火车票等)公共层,为了更多维的复用完全模仿了离线公共层的处理,将复杂且时延较大的航段信息关联到一起,导致整个任务的处理时延达十几秒。为了精确平衡时延和复用性,将旧有的多流join后统一输出,改为多级join输出,将gmv的处理时延降低到3s以内。整体流程如下:
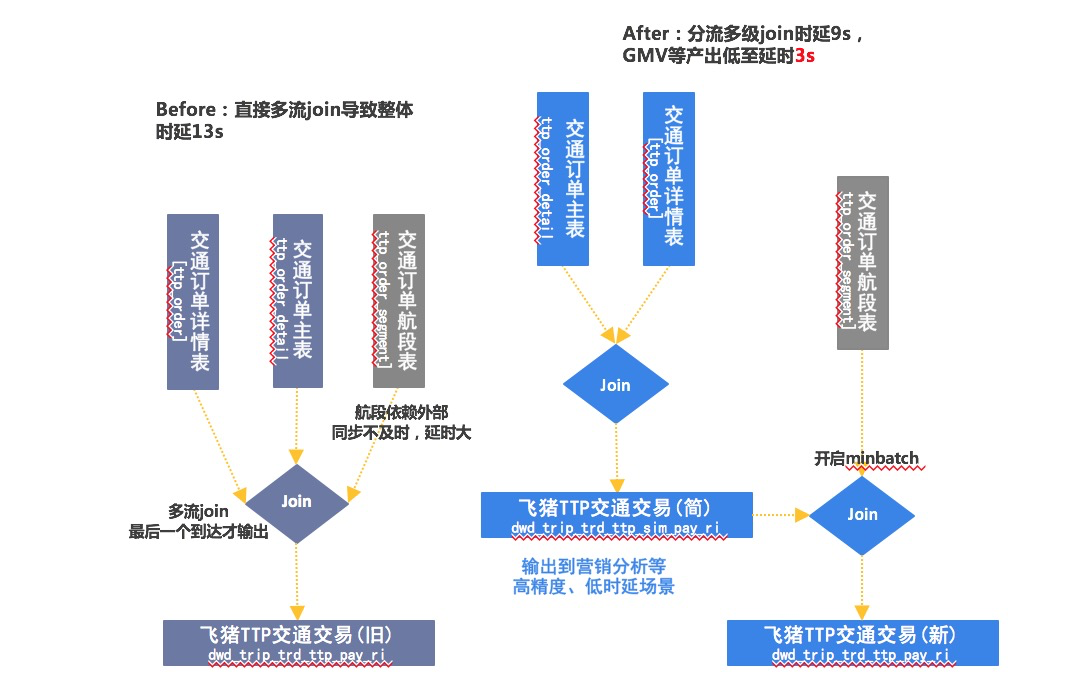
- 任务节点部分,调整参数配置,降低缓冲和IO处理时延。公共层和GMV统计部分,调整miniBatch的allowLatency、cache size,TT输出的flush interval,Hbase输出的flushsize等等
3)TopN优化
TopN一直实时营销分析常见的统计场景,因为其本身就是热点统计,所以比较容易出现数据倾斜、性能和稳定性问题。双十一预售开始后,会场、商家、商品的曝光流量的TopN作业就开始陆续的出现背压,作业checkpoint超时失败,时延巨大且易failover,统计数据基本不可用状态。初期判断为流量上涨,作业吞吐不够,调大资源和并发基本无任何效果,背压仍集中在rank的节点而资源充足。仔细排查发现rank节点执行算法蜕化为性能较差的RetractRank算法,之前group by后再row_number()倒排后取topN的逻辑,无法自动优化成UnaryUpdateRank算法,性能急降(原因为UnaryUpdateRank算子有准确性风险在内部Flink3.7.3版本被下线)。多次调整和测试之后,确定无法通过配置优化问题,最终通过多重逻辑优化进行化解。
- 将会场分类的曝光、商家商品的任务进行逻辑拆分为两个任务,防止商品或商家逻辑rank节点数据倾斜,导致整体数据出不来。
- 先做了一级聚合计算UV,减少TOP排序数据数据量,再做二级聚合优化为UpdateFastRank算法,最终checkpoint秒级,回溯聚合一天曝光数据只需要10分钟。
- 当然还有一种策略是做二级TopN,先
原文链接
本文为阿里云原创内容,未经允许不得转载。
数据大屏一直是实时场景高要求的代表,每次双十一业务带来的考验和挑战,都会对整个实时数据体系和链路带来新的突破。同时,飞猪的实时数据不仅仅只是止点亮媒体大屏,提效营销分析和会场运营,由实时公共层和特征层、实时营销分析、实时标签和RTUS服务构成的实时数据体系,正在全方位、多维度地附能搜索、推荐、营销、触达和用户运营等核心业务。
作者简介:王伟(花名炎辰),阿里巴巴飞猪技术部高级数据工程师 。